해당 논문은(The Logic Theory Machine - A Complex Information Processing System) 약 70년전인 1956년에 게재된 논문으로 기호 논리학의 정리를 증명하는 복잡한 정보 처리 시스템을 제안하며, 컴퓨터가 어떻게 인간과 유사한 방식으로 문제에 접근할 수 있는지 보여준 논문입니다.
최초의 인공지능 프로그램 논문 중 하나로 기계가 논리적 추론을 수행할 수 있다는 것을 실제 코드로 증명하였습니다.
인공지능의 고전논문들을 읽는것이 중요하다 생각하여 앨런튜링의 논문부터 읽고있지만 해당 논문은 앨런튜링의 논문보다 인쇄상태(?)가 매우 별로여서(타자기로 입력한 그대로인 인쇄물같다.) 읽기가 좀 불편하였습니다. 중간중간 표,공식,그림도 아닌것이 이해가 안되는게 있었다. 나중에 알고보니 프로그램 명세서였다.
서두가 길었고, 본격적으로 The Logic Theory Machine 리뷰를 시작해보겠습니다.
I. 복잡한 정보 처리 시스템 (Complex Information Processing System)
1. 복잡성이란 무엇인가
LT를 ‘복잡한 시스템’이라 부르는 이유는 단순히 계산량이 많아서가 아니다.
LT는 다음 세 가지 복잡성의 기준을 충족한다:
- 다양성: 시스템 전체 성능에 직접 필수적이지 않아도 다양한 프로세스들이 존재한다.
- 유연성: 프로세스의 실행 순서가 고정되어 있지 않고, 환경·결과에 따라 달라진다.
- 계층성: 동일한 프로세스가 다양한 맥락에서 반복·재귀적으로 사용된다.
LT는 이 세 특징을 모두 갖추었으며, 이는 기존의 ‘고정된 알고리즘’ 기반 프로그램들과 구분된다.
즉, LT는 휴리스틱적(발견적) 접근의 효용을 증명한 최초의 시도였다.
2. 시스템의 뼈대와 언어 (LL 과 IPS)
LT의 명세에는 형식 언어 논리 언어(Logic Language, LL) 가 사용된다.
LL은 하나의 정보 처리 시스템(Information Processing System, IPS) 으로 구성되며, 이는 메모리와 정보 프로세스(IP) 의 집합이다.
IPS의 주요 구성요소
- Working Memory
- Storage Memory (T, P, Q 리스트)
- Information Process (Instruction 구조)
-
작업 메모리(Working Memory) : 단일 요소(element)를 임시로 저장
→ H (변수 위치 수), J (고유 변수 수), K (레벨 수) 등의 기술 정보 포함 -
저장 메모리(Storage Memory) : 세 개의 리스트 형태
- T (Theorem List) – 증명된 공리 및 정리 저장
- P (Active Problem List) – 현재 해결 중인 문제
- Q (Inactive Problem List) – 중복 또는 보류된 문제
-
정보 프로세스(Information Process, IP) :
메모리에 저장된 논리 표현식을 읽고, 치환·비교·추론 등의 연산을 수행하는 절차. LT에서는 이러한 IP들이 ‘치환(MSb)’, ‘분리(MDt)’, ‘연결(MCh)’ 등의 루틴 형태로 구현된다.
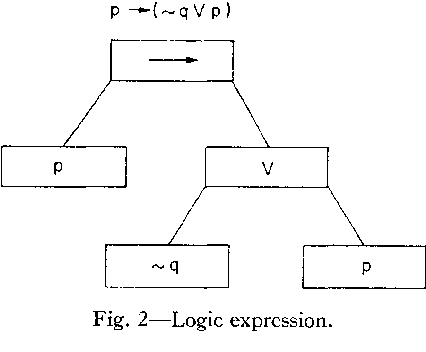
논리 표현식은 트리(tree) 구조로 나타낸다. 각 노드는 위치(P), 변수, 논리 기호(∨, ⊃), 부정 기호 수(G) 등을 저장한다.
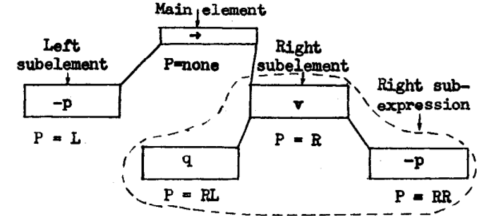 1.7: −p ⊃ (q ∨ −p) 의 트리 도식
1.7: −p ⊃ (q ∨ −p) 의 트리 도식
II. 논리 이론 기계(The Logic Theory Machine)
LT는 Principia Mathematica 에 수록된 정리들을 스스로 증명하기 위해 설계되었다.
핵심은 세 가지 휴리스틱 발견 방법 이다.
1. 치환 방법 (Method of Substitution, MSb)
핵심: 이미 증명된 정리 T 리스트에서 목표 정리와 유사한 구조를 찾는다.
- 유사성 테스트(CSm) : K, J, H 값(레벨, 고유 변수, 변수 위치)을 비교
- 일치(Matching, LMc) : 변수 치환 및 기호 대체를 통해 완전 일치 시도
- 성공 시 즉시 증명 완료
논문에는 유사성 판단 기준 K, J, H 계산식이 수식으로 제시되어 있다.(아래 표로 정리)
| 기호 | 의미 | 계산 기준 | 예시 |
|---|---|---|---|
| H | 변수 위치 수 (number of variable positions) |
논리식 내 변수 위치 개수 | p → q → H = 2 |
| J | 고유 변수 수 (number of distinct variables) |
중복 제외한 서로 다른 변수 개수 | p → (p ∨ q) → J = 2 |
| K | 레벨 수 (level of tree structure) |
논리 트리의 깊이(depth) | ¬p ⊃ (q ∨ ¬p) → K = 3 |
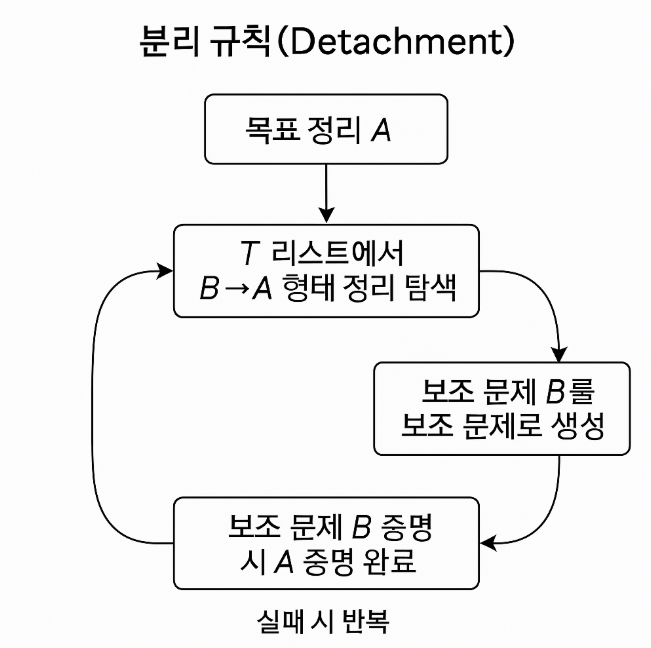
2. 분리 방법 (Method of Detachment, MDt)
핵심: 논리학의 기본 규칙 A ∧ (A → B) ⇒ B 를 역방향으로 사용한다.
- 목표 A 를 증명하기 위해
B → A형태의 정리 T 를 탐색 - 매칭 성공 시, T의 왼쪽 부분 B 를 새로운 보조 문제(sub-problem) 로 생성
- 보조 문제가 성립하면 A 도 성립한다
분리 규칙의 순환 다이어그램(Proof Cycle Flow)
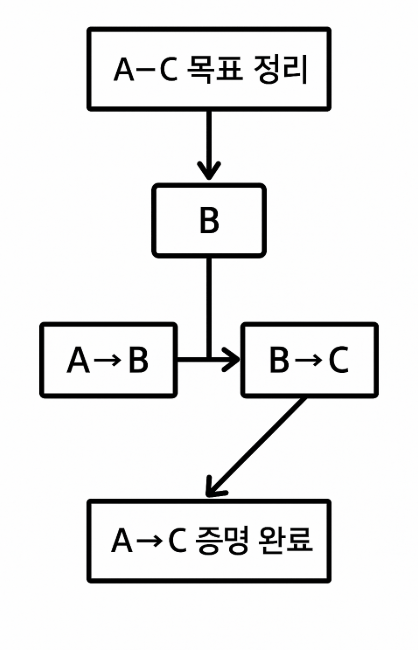
3. 연결 방법 (The Chaining Method, MCh)
핵심: 추이성 이용 — A → B, B → C 이면 A → C.
- 를 증명할 때 중간 연결고리 탐색
- 정방향 또는 역방향 체이닝으로 보조 문제 생성
- 보조 문제에는 주로 치환 방법(MSb) 적용
연결방법(Chaining Method) 흐름도
4. 시스템을 관리하는 지휘자 (Executive Routine, Ex)
세 방법의 실행 순서와 제어를 담당하는 중앙 루틴이다.
-
적용 순서: 치환 → 분리 → 연결
-
실패 시 생성된 보조 문제는 P 리스트에 저장
-
K값(레벨) 이 작은 문제부터 우선 처리
-
중단 조건
- P 리스트가 비면 종료
- 총 작업량 W 레지스터 가 한도 초과 시 종료
-
Executive Routine 의 의사코드 및 분기 조건 표 정리
| 단계 | 실행 내용 | 분기 조건 / 결과 |
|---|---|---|
| 1 | 치환 방법(MSb) 실행 | 성공 → 증명 완료 실패 → 다음 단계로 이동 |
| 2 | 분리 방법(MDt) 실행 | 성공 → 보조 문제(B) 생성 및 증명 시도 실패 → 다음 단계로 이동 |
| 3 | 연결 방법(MCh) 실행 | 성공 → 보조 문제 생성 실패 → P 리스트에 문제 기록 |
| 4 | 문제 선택 (P 리스트 관리) | K값(레벨)이 가장 작은 문제부터 선택하여 재시도 |
| 5 | 중단 조건 검사 | (1) P 리스트가 비면 종료 (2) 총 작업량 W가 한도 초과 시 종료 |
5. 학습과 성과
LT는 경험적 학습은 하지 않지만, 새로운 정리를 증명할 때마다 이를 T 리스트에 추가하여 재사용한다.
즉, “증명된 정리 → 새 문제의 빌딩 블록” 으로 활용.
이 누적 방식은 LT를 단순한 계산기가 아닌 지식 축적형 추론 시스템으로 만든다.
결과 요약 :
Principia Mathematica 제2장의 52개 정리 중, LT는 38개 정리를 독립적으로 증명하는 데 성공했다.
III. 전체 프로그램 명세 (Formal Specification)
이 부분은 논문 Section III 에서 가장 기술적으로 작성된 부분으로,
LT 내부 루틴의 의사코드(pseudo-code) 와 기본 명령(primitive operations) 이 정의되어 있다.
1. 명령어 형식
각 명령은 다음 형식을 갖는다.
A OPER L C R B- A : 루틴명 (e.g., MSb, LMc)
- OPER : 연산명
- L/C/R/B : Left, Center, Right, Branch 레지스터 (입력/출력 및 분기 위치)
2. 기본 연산 (Primitives)
| 기호 | 논문의 원문 | 설명 |
|---|---|---|
| FEF x y b | Find the first E in A(x) and put it in y; if none, branch b. | A(x)에서 첫 E를 찾아 y에 넣고, 없으면 b로 분기 |
| FEN x y b | Find the next E in A(x) after E(y); if none, branch b. | A(x)의 E(y) 다음 E를 찾아 y에 넣고, 없으면 b로 분기 |
| FL x y | Find EL(x) and put in y. | 왼쪽 하위식 EL(x)을 찾아 y에 저장 |
| FR x y | Find ER(x) and put in y. | 오른쪽 하위식 ER(x)을 찾아 y에 저장 |
| PE x y | Put E(x) in E(y); E(x) remains. | E(x)를 E(y)에 복사 (원본 유지) |
| S x | Store E(x) back in A(x); if absent, append at end. | E(x)를 A(x)에 저장, 없으면 끝에 추가 |
| SW x y | Store E(x) as next E in A(y). | E(x)를 A(y)의 다음 E로 저장 |
| GS x y | Store a copy of X(x) in A(y). | X(x)의 사본을 A(y)에 저장 |
| TC x b | If C(x) = → then branch b. | C(x)이 ‘→’이면 b로 분기 |
| TV x b | If C(x) = ∨ then branch b. | C(x)이 ‘∨’이면 b로 분기 |
위에 나열된 기본 연산들은 언뜻 보면 복잡한 기계어처럼 느껴진다. 하지만 이 명령어들은 LT가 논리적 사고를 하기 위해 사용하는 '알파벳'이다. '치환'이나 '연결'과 같은 더 큰 전략(단어와 문장)들은 모두 이 알파벳들의 정교한 조합으로 만들진다. 즉, LT의 모든 지능적인 활동은 바로 이 작고 기본적인 동작들로부터 시작되는 것 입니다.
3. 루틴 예시
- MSb (Substitution Method) : 치환 시도 후 실패하면 보조 문제 생성
- LMc (Matching Routine) : 식 패턴 매칭 검사 및 치환
- LSb (Substitution Routine) : E(G) 를 X(s) 에 대입하고 결과를 저장
결론 (Conclusion)
LT는 “컴퓨터가 논리적으로 사고할 수 있는가?”에 대한 최초의 실험적 대답이었다.
단순한 공리 증명기를 넘어, 인간의 추론 과정을 기계적으로 재현한 휴리스틱 추론 시스템의 원형이었다.
“The Logic Theorist는 인간의 추론을 기계적으로 모사함으로써,
논리적 사고 역시 정보처리 과정으로 구현될 수 있음을 최초로 입증한 시스템이었다.”
논문리뷰를 마무리하며..
모든 논문들이 그렇지만, 이 논문은 매우 어렵고 재미도 없다. '최초의 인공지능 프로그램 논문'으로 알게되어 읽었으나 시도는 좋았고 과정은 처참했다.
하지만, 계속 다른 논문들도 열심히 많이 읽고 정리하다보면은 이 논문도 쉽고 이해가 잘 되길바라며 꾸준히 논문리뷰를 진행하려고 한다.
길고 즐거운 추석 연휴에 자기개발을 위해 뭐 하나라도 한게 어디냐
