단어의 표현방법 종류
-
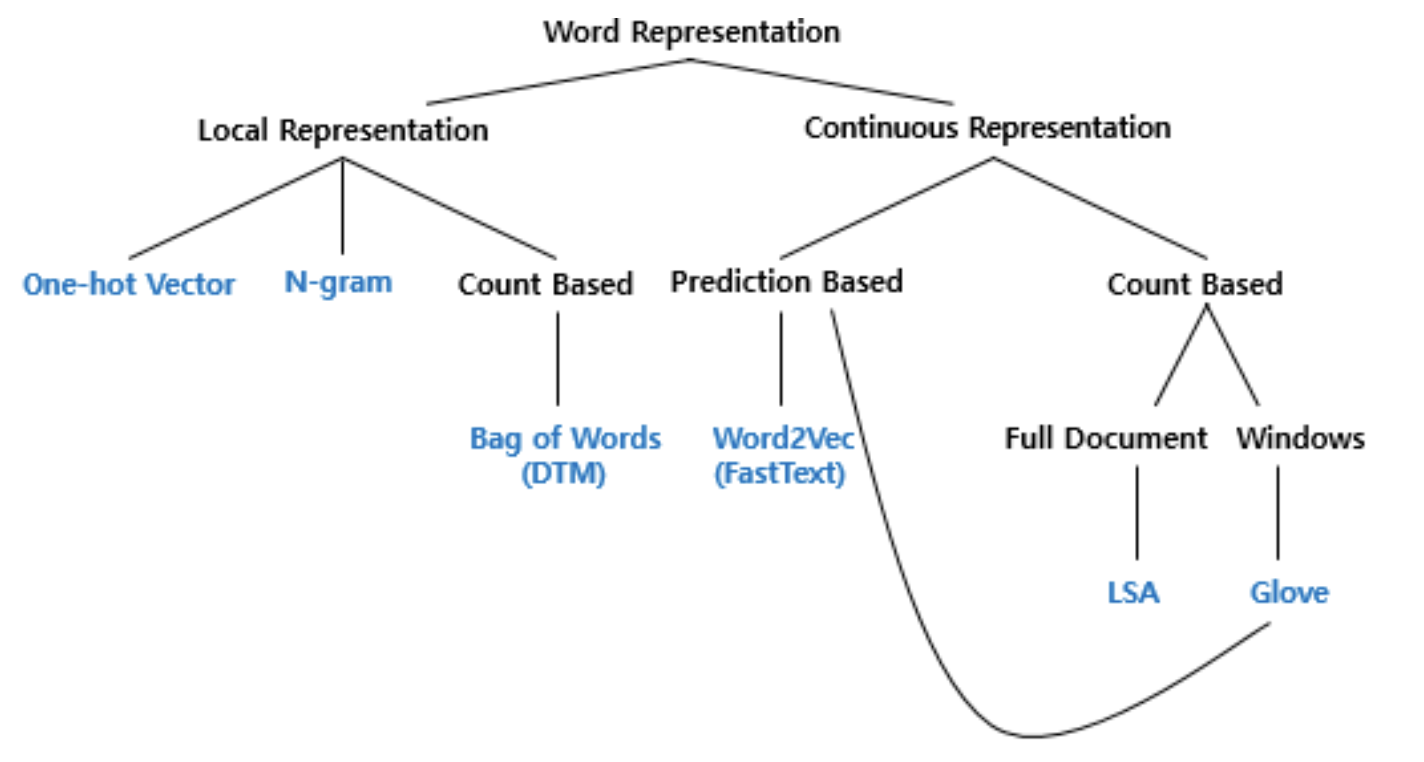
Local Representation
국소 표현, 해당 단어 그 자체만 보고 특정값을 맵핑하여 단어를 표현하는 방법
Discrete Representation (이산 표현) 이랑 유사
ex) One-hot vector, N-gram, BoW -
Distributed Representation
분산 표현, 해당 단어를 표현하고자 주변 단어를 참고하여 표현하는 방법
Continuous Representation (연속 표현) - 분산표현을 포괄하는 더 큰 개념
ex) word2vec
puppy, cute, lovely 단어의 표현 방법 종류에 따른 단어 표현 방법
- Local Representation : 각 단어에 1, 2, 3같은 숫자를 맵핑
- Distributed Representation : puppy단어 근처에 cute, lovely 단어 자주 등장
->puppy 단어는 cute, lovely 한 느낌이다로 정의
Bag of Words
Local Representation의 Count Based 단어표현 방법
- 단어순서 고려X
- 단어들의 출현 빈도 (frequency) 만 고려
BoW 만드는 과정
(1) 각 단어에 고유한 정수 인덱스를 부여합니다. # 단어 집합 생성.
(2) 각 인덱스의 위치에 단어 토큰의 등장 횟수를 기록한 벡터를 만듭니다.from konlpy.tag import Okt #한국어 형태소 분석기 Okt(Open Korea Text)
okt = Okt()
def build_bag_of_words(document):
#온점제거및형태소분석
document = document.replace('.', '')
tokenized_document = okt.morphs(document)
word_to_index = {}
bow = []
for word in tokenized_document:
if word not in word_to_index.keys():
word_to_index[word] = len(word_to_index)
# BoW에 전부 기본값 1을 넣는다.
bow.insert(len(word_to_index) - 1, 1)
else:
# 재등장하는 단어의 인덱스
index = word_to_index.get(word)
# 재등장한 단어는 해당하는 인덱스의 위치에 1을 더한다. bow[index] = bow[index] + 1
return word_to_index, bow
doc1 = "정부가 발표하는 물가상승률과 소비자가 느끼는 물가상승률은 다르다." vocab, bow = build_bag_of_words(doc1)
print('vocabulary :', vocab)
print('bag of words vector :', bow)결과
vocabulary : {'정부': 0, '가': 1, '발표': 2, '하는': 3, '물가상승률': 4, '과': 5, '소비자': 6, '느끼는': 7, '은': 8, '다르다': 9}
bag of words vector : [1, 2, 1, 1, 2, 1, 1, 1, 1, 1]자주 사용되는 단어 파악 가능 -> 어떤성격의 문서인지 파악, 분류가능
CountVectorizer 클래스로 BoW 만들기
sklearn의 CountVectorizer 클래스: 단어의 빈도 count해서 vector 로 만든다, 불용어 제거 가능
from sklearn.feature_extraction.text import CountVectorizer
corpus = ['you know I want your love. because I love you.']
vector = CountVectorizer()
#사용자가 직접 정의한 불용어 사용
#vector = CountVectorizer(stop_words=["the", "a", "an", "is", "not")
#CountVectorizer 에서 제공하는 자체 불용어 사용
#vector = CountVectorizer(stop_words="english")
#NLTK 에서 지원하는 불용어 사용
#vector = CountVectorizer(stop_words=stopwords.words("english"))
# 코퍼스로부터 각 단어의 빈도수를 기록
print('bag of words vector :', vector.fit_transform(corpus).toarray())
# 각 단어의 인덱스가 어떻게 부여되었는지를 출력
print('vocabulary :',vector.vocabulary_)bag of words vector : [[1 1 2 1 2 1]]
vocabulary : {'you': 4, 'know': 1, 'want': 3, 'your': 5, 'love': 2, 'because': 0}
이것저것 해보는 중