저번시간에 배운 BoW에 이어서 DTM에 대해 공부해보겠습니다.
DTM
DTM(Document‐Term Matrix)
- 서로 다른 문서들의 BoW 들을 결합한 표현 방법
- 즉, 각 문서에 대한 BoW를 하나의 행렬로 만든 것
- 행과 열을 반대로 하면 TDM이라고 부른다
- 문서단어행렬이라고도 부른다
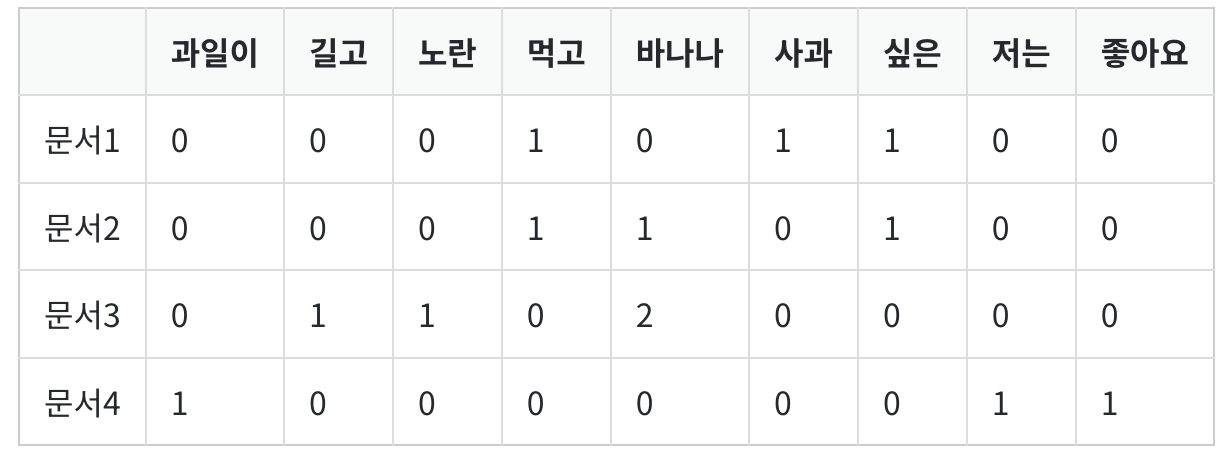
예)
문서1 : 먹고 싶은 사과
문서2 : 먹고 싶은 바나나
문서3 : 길고 노란 바나나 바나나
문서4 : 저는 과일이 좋아요
DMT의 한계
- 희소 표현 (Sparse representation)
One-hot vector 처럼 전체 토큰 크기의 차원을 가짐, 대부분의 벡터가 0 값을 가진다
-> 전처리 방법들 활용하여 집합 크기 낮춤 - 단순 빈도수 기반 접근
불용어는 자주 등장하지만 중요도 낮음
ex) 여러 문서 모두 "the"가 자주나온다고 유사한 문서라고 판단하면 안됨
-> TF‐IDF: DTM에 불용어와 중요한 단어에 대해서 가중치 줌
TF‐IDF
TF‐IDF(Term Frequency‐Inverse Document Frequency)
- DTM 내에 있는 각 단어에 대한 중요도를 계산
- DTM 을 만든 후, TF‐IDF 가중치를 부여
- 모든 문서에서 자주 등장하는 단어는 중요도가 낮다고 판단
- 특정 문서에서만 자주 등장하는 단어는 중요도가 높다고 판단
- TF-IDF 값이 크면 중요도가 크다고 판단
TF‐IDF 가중치 구하기
- 문서 = d
- 단어 = t
- 문서의 총개수 = n
- tf(d,t): Term Frequency, 특정 문서 d에서의 특정 단어 t의 등장 횟수
- df(t): Document Frequency, 특정 단어 t가 등장한 문서의 수
- idf(t) : Inverse Document Frequency, df(t) 에 반비례하는 수
- TF‐IDF = TF 와 IDF 를 곱한 값
tf(d,t) 구하기
- 특정 문서 d에서의 특정 단어 t의 등장 횟수
- DTM를 이용해서 구함
- DTM에서 각 단어들이 가진 값
df(t) 구하기
- 특정 단어 t가 등장한 문서의 수
- DTM를 이용해서 구함
- t가 한 문서에서 여러번 등장해도 카운트는 1
idf(t) 구하기
- df(t) 에 반비례하는 수에 로그 취함
- log는 n(총 문서의 수)이 커질수록, IDF의 값은 기하급수적으로 커지는 것을 방지
ex) 전체 문장 n = 1,000,000 이고 df(t) = 1일때
n/df(t) = 1,000,000 -> log취하면 6
TF-IDF 코드 구현
docs에 문서 저장하고 vocab에 단어집합 생성
import pandas as pd # 데이터프레임 사용을 위해
from math import log # IDF 계산을 위해
docs = [
'먹고 싶은 사과',
'먹고 싶은 바나나',
'길고 노란 바나나 바나나',
'저는 과일이 좋아요'
]
#단어집합 생성
vocab = list(set(w for doc in docs for w in doc.split()))
vocab.sort()TF, IDF, 그리고 TF‐IDF 값을 구하는 함수를 구현
# 총 문서의 수
N = len(docs)
def tf(t, d):
return d.count(t) #특정 문장 d 에서 특정 단어 t 출현 수
def idf(t):
df = 0
for doc in docs:
df += t in doc #특정 문장 doc에 단어 t 가 있으면 df += 1;
return log(N/(df+1))
def tfidf(t, d):
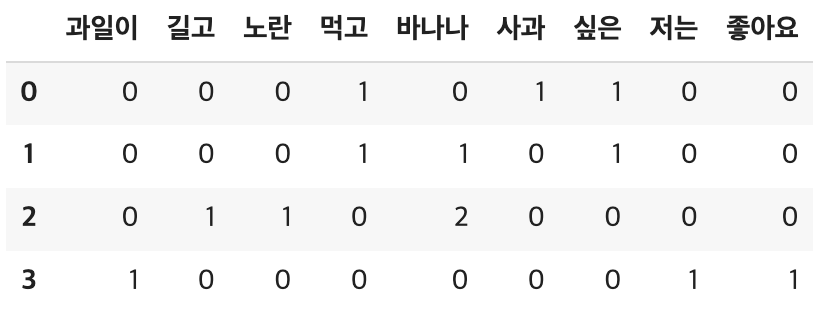
return tf(t,d)* idf(t)TF 를 구하기(DTM 을 데이터프레임에 저장)
result = []
# 각 문서에 대해서 아래 연산을 반복
for i in range(N):
result.append([]) #append에 새로운 행 만들기
d = docs[i]
for j in range(len(vocab)):
t = vocab[j] #특정 단어
result[-1].append(tf(t, d)) #마지막 칸에 tf(t, d)값 추가
tf_ = pd.DataFrame(result, columns = vocab)
tf_결과
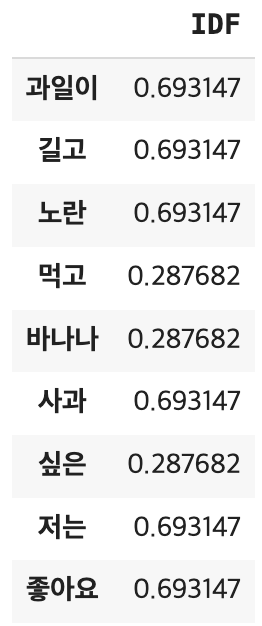
각 단어에 대한 IDF 값을 구하기
result = [] #초기화
for j in range(len(vocab)): #단어집합에 있는 단어들
t = vocab[j] #특정 단어 t
result.append(idf(t)) #result에 idf값 저장
idf_ = pd.DataFrame(result, index=vocab, columns=["IDF"])
idf_결과
마지막으로 TF 값과 IDF값을 곱한 TF-IDF 행렬 구하기
result = [] #초기화
for i in range(N):
result.append([]) #행 추가
d = docs[i]
for j in range(len(vocab)):
t = vocab[j]
result[-1].append(tfidf(t,d))
tfidf_ = pd.DataFrame(result, columns = vocab)
tfidf_ 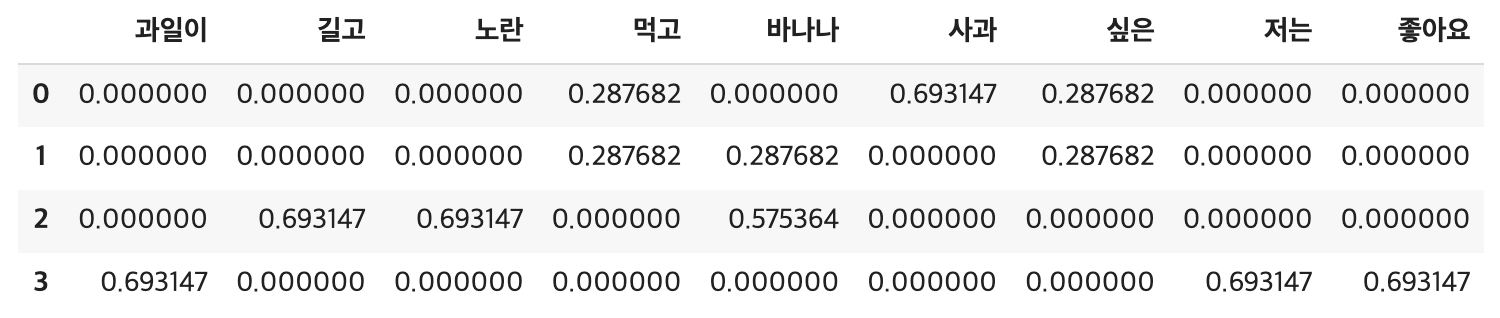
사이킷런을 이용한 DTM 과 TF‐IDF 실습
# 문서 집합(corpus)에 등장하는 각 단어의 빈도수(Count)를 계산해주는 CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
#TF-IDF를 자동 계산해주는 TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'you know I want your love',
'I like you',
'what should I do ',
]
vector = CountVectorizer()
tfidfv = TfidfVectorizer().fit(corpus)
print(vector.fit_transform(corpus).toarray())# 코퍼스로부터 각 단어의 빈도수를 기록 (DTM)
print(vector.vocabulary_) # 각 단어와 맵핑된 인덱스 출력
print(tfidfv.transform(corpus).toarray()) #바로계산
print(tfidfv.vocabulary_) #단어집합 생성결과
[[0 1 0 1 0 1 0 1 1]
[0 0 1 0 0 0 0 1 0]
[1 0 0 0 1 0 1 0 0]]
{'you': 7, 'know': 1, 'want': 5, 'your': 8, 'love': 3, 'like': 2, 'what': 6, 'should': 4, 'do': 0}
[[0. 0.46735098 0. 0.46735098 0. 0.46735098 0. 0.35543247 0.46735098]
[0. 0. 0.79596054 0. 0. 0. 0. 0.60534851 0. ]
[0.57735027 0. 0. 0. 0.57735027 0. 0.57735027 0. 0. ]]
{'you': 7, 'know': 1, 'want': 5, 'your': 8, 'love': 3, 'like': 2, 'what': 6, 'should': 4, 'do': 0}
이것저것 해보는 중