1. Introduction
1-1 Difficulty of Mean-field Approach*
- assumes that all variables of the model(data, latent, parameters) are independent (but they are not!)
- simplifies the calculation, but can have poor approximations for complex models with dependent variables, which requires solving intractable expectations
*mean-field approach?
👉 commonly used method in VB for choosing the form of the approximate posterior
1-2 Auto-Encoding Variational Bayes (AEVB)
- in order to overcome such intractability, the paper suggests new algorithm called AEVB
- enables efficient, differentiable, and unbiased estimation of the variational lower bound via Stochastic Gradient Variational Bayes (SGVB) estimator
- simplifies posterior inference and model learning, avoiding costly iterative schemes like MCMC.
2. Method
2-1 Problem Scenario
Assumptions
- value generated from prior distribution <- prior
- value generated from conditional distribution <- likelihood
- PDF of prior & likelihood distribution are differentiable almost everywhere w.r.t. and z
- true parameters and latent variables are unknown
- do not simplify the marginal / posterior probabilities
Main Contributions
- Efficient approximate ML or MAP estimation for the parameters
- Efficient approximate posterior inference of the latent variable z given an observed value x for a choice of parameters
- Efficient approximate marginal inference of the variable x
2-2 Variational Bound
-
Let marginal likelihood*
-
Since the value of KL-Divergence is always non-negative,
becomes the lower bound. -
Lower bound on the marginal likelihood of datapoint i can be re-written as :
Gradient of the lower bound w.r.t. , can lead to gradient estimator exhibiting high variance, thus impractical!
==> Importance of SGVB estimator
*marginal likelihood (evidence)?
👉 represents the probability of the observed data given the prior distribution of the model parameters
👉 When optimizing, since the marginal likelihood can make the computation intractable, we use variational lower bound.
2-3 Reparametrization Trick
-
Let z be a continuous random variable, be some conditional distribution.
-
Then z can be expressed as:
, where is a random variable following simple, known distribution -
- :
- an expectation of a function f(z) under the distribution , represented by the integral of f(z) times the PDF of z (), over all possible values of z
- :
- changing the random variable of interest in the expectation calculation from z to , which follows the distribution and respectively.
- Since does not depend on the parameters , it is possible to compute the gradient of the expectation w.r.t.
- :
2-4 SGVB estimator and AEVB algorithm
-
After applying reparametrization trick of section 2-3, estimates of expectation of some function w.r.t. can be formed as :
-
Yield generic Stochastic Gradient Variational Bayes estimator by applying technique in 1.
where and
Below is the AEVB algorithm that utilizes above estimator.

3. Example : VAE
3-1 Variational approximate posterior
- mean and s.d. of approximate posterior : parameters learned from encoder
- : variational parameters
- the main goal of VAE is to find good approximate posterior over the latent variables
3-2 Estimator for VAE and datapoint
where and
3-3 Architecture
Auto-encoder vs Variational Auto Encoder
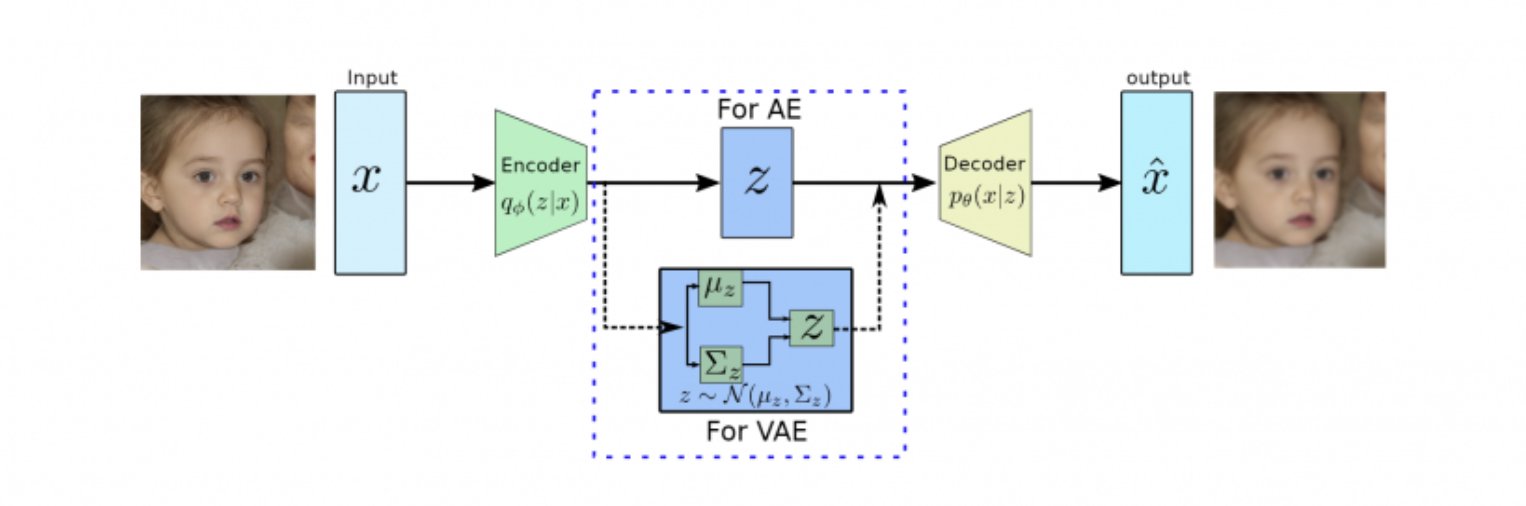
Source : https://data-science-blog.com/blog/2022/04/19/variational-autoencoders/
4. Conclusion
- SGVB is a novel estimator of the variational lower bound, resolving intractibility when parameters are optimized
- Since SGVB is differentiable and can be optimized straight forward, it can lead to efficient approximate inference with continuous latent variables.
- For the case of i.i.d. datasets and continuous latent variables per datapoint we introduce an efficient algorithm called Auto-Encoding VB (AEVB), learning an approximate inference model using the SGVB estimator.

잘 보고 갑니다