Motivation
After taking leave of absence of unviersity, I recently got into playing Minecraft. Reminding me of my childhood memory, at the same time I have realized that so many features have changed and updated. While enjoying my life in cubic 3D world, I wondered what would it look like if the Minecraft world were generated by generative models.
Now that I have read about the GAN, I searched if there are any generative models related to the game and found out an interesting model : World-GAN.
World-GAN
What is World-GAN?
World-GAN is a generative model for generating Minecraft worlds. From a single example, it can perform PCGML in Minecraft. It uses the block2vec representation, motivated by the word2vec and the dense representation of NLP. Via block2vec, World-GAN is able to generate worlds in large levels based on parts of users' creations.
Related Works
To understand how the World-GAN works, reading the following previous works would also be helpful :
1. Sin-GAN (Shaham, Dekel, and Michaeli 2019)
- GAN architecture, learning from a single natural image
- Cascade of fully convolutional generators and discriminators patched in diverse scales
2. TOAD-GAN (M. Awiszus, F. Schubert, and B. Rosenhahn 2020)
- replaced bilinear downsampling in Sin-GAN to a special downsampling operation
- determine the importance of token using a hierarchy that
is constructed by a heuristic, motivated by the TF-IDF metric from NLP - applied to 2D token-based games like Super Mario
Problem Scenarios
The main problem of applying TOAD-GAN directly into world generating can be summarized into two parts.
- The conversion from 2D to 3D leading to dramatic increase in size of samples.
- A large variety of tokens in Minecraft, and their long-tail distribution
- sometimes aliasing low-frequency tokens, which are significant and should not be ignored
block2vec
In order to resolve the above problems, the paper suggests a new token embedding method called block2vec.
Say that there is a token in a given training sample, and let the frequency of that token. Then the occurence probability of the token can be written as :
By sampling the tokens according to the , it can mitigate the issue of token imbalance.
Three advantages of using block2vec
- Reduced memory requirements
- Omit definition of hierarchy
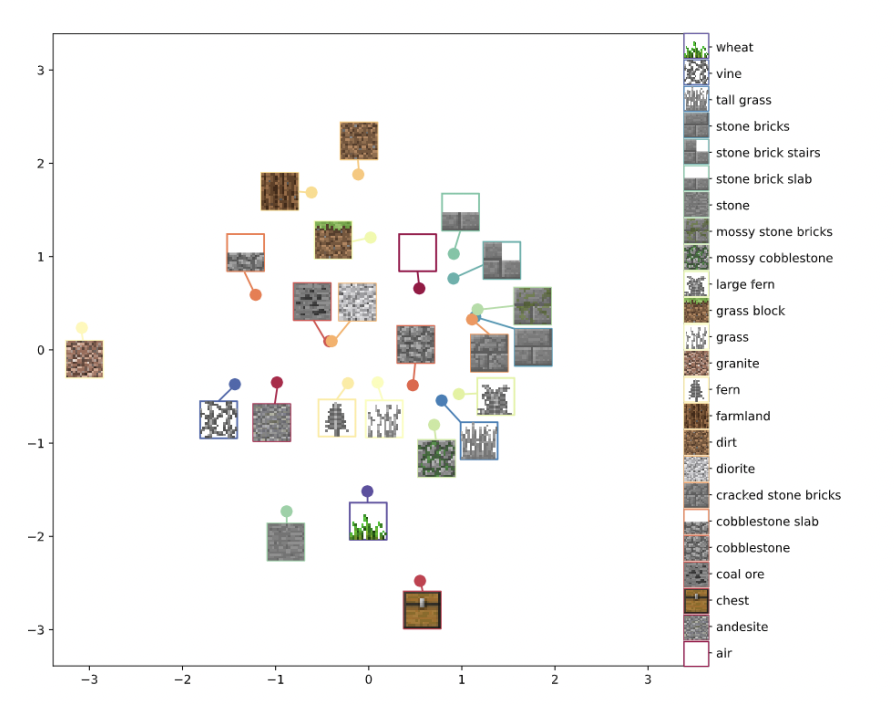
- visualized token embeddings (dimension reduced to 2 by MDE technique)
- rare tokens are placed close to semantically similar more common tokens
- Choosing a different mapping from internal representations to tokens allows us to change the style of the generated content after training

Training
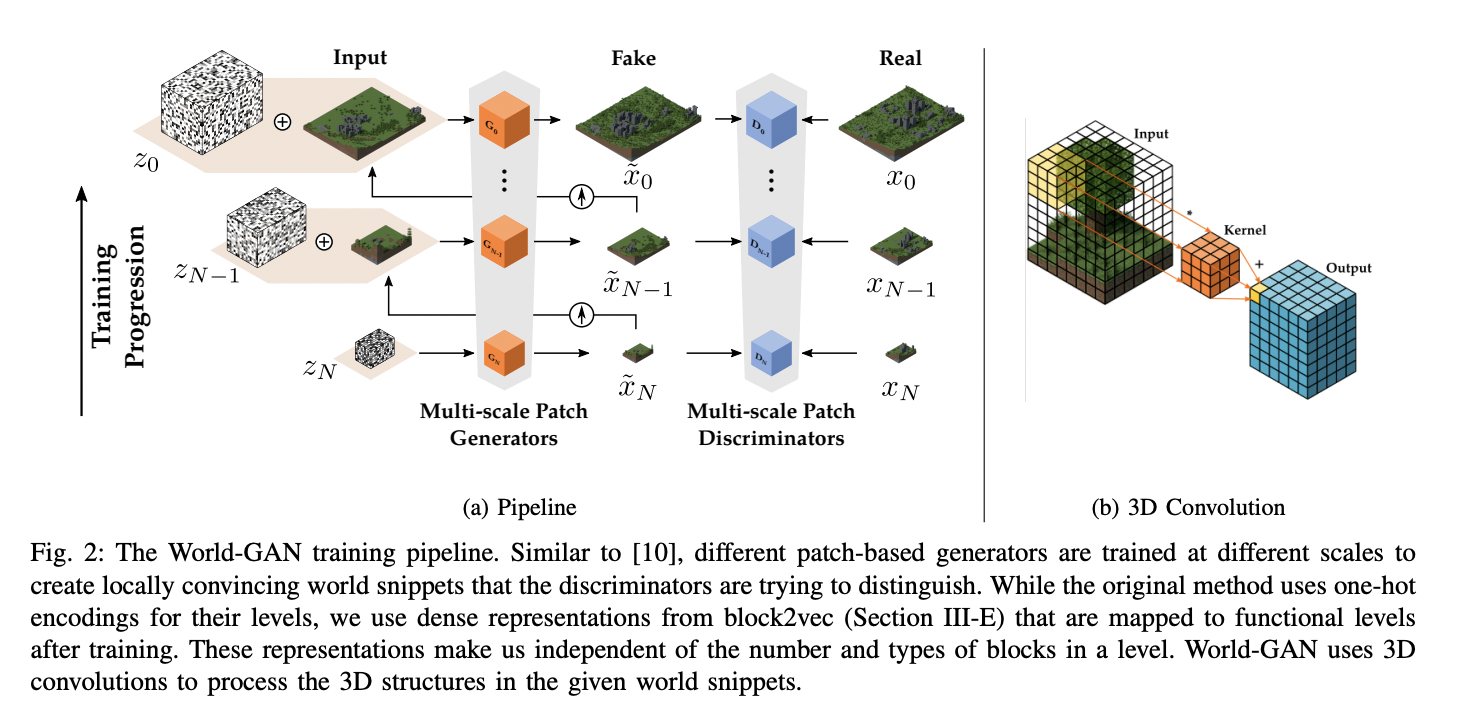
- skip-gram model with two linear layers predicting context from the target token
- Generator produces tensor
- Tensor fed to the discriminator
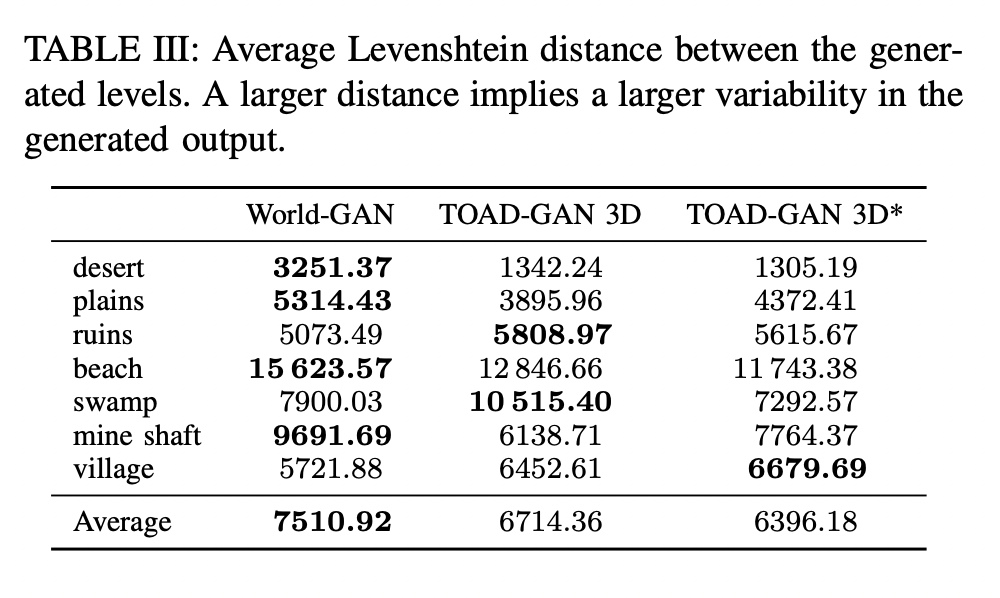
Experiment Results
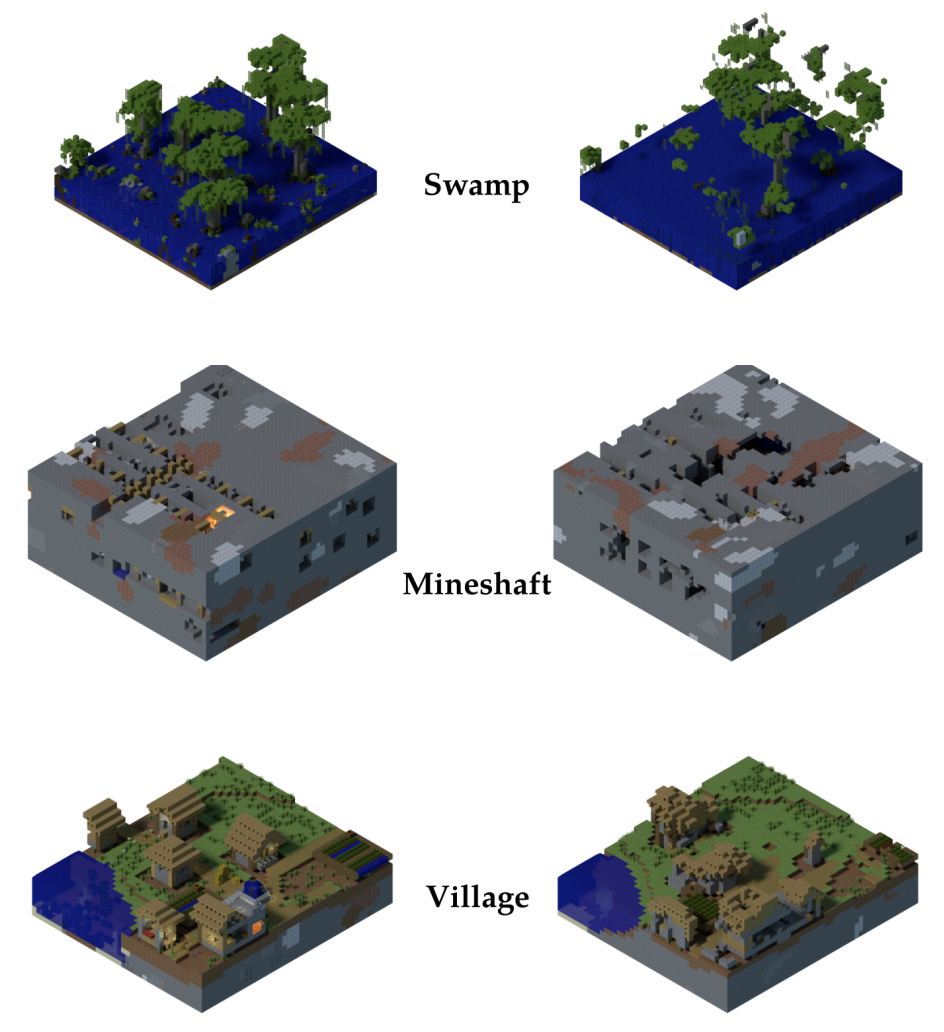
Qualitative
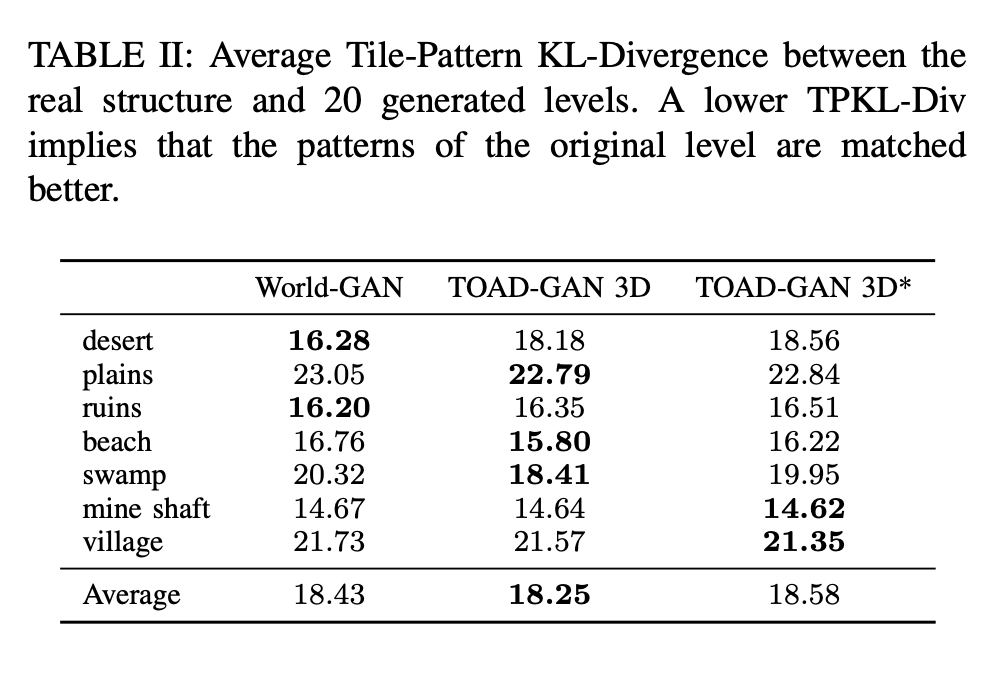
Quantitative

4개의 댓글

Whether on your phone during a trip or on your console at home, Minecraft Bedrock Edition keeps your worlds synced so you can continue your adventure without limits. visit: https://minescraftapks.com.tr/minecraft-bedrock-apk/

Minecraft APK at https://theminecraftapk.com.tr/ offers a smooth and customizable gaming experience for Android users. From new maps to survival mods, everything is available in one package.

The Minecraft Apk is perfect for someone who loves creativity and survival challenges in a game. It lets a person build, explore, and craft their own world filled with adventures. With smooth performance and exciting features, this game keeps every player engaged for hours. Visit now https://minecraftapkdl.com/
Thanks for this can I generate these worlds and use them in https://apkminescraft.id/ ? please do let me know