1. Introduction
DragGAN은 사용자로 하여금 GAN으로 생성된 이미지를 드래그 하여 편집할 수 있게 한다. 변경하고자 하는 핸들 포인트가 빨간색이고, 상응하는 타겟 점을 파란색으로 지정하면 변화에 flexible한(밝은) 영역은 이미지가 변화하고, 그 외 부분은 변하지 않는다.

이전에도 GAN을 컨트롤 하기 위한 시도는 꾸준히 이루어졌었다. 대부분의 시도는 기존의 3D모델들이나 인위적으로 annotated 된 데이터에 의존하는 지도학습을 통해 이루어졌기 때문에 새로운 object 카테고리에 대해 일반화가 어렵고, 편집 과정에서 바꿀 수 있는 공간적 특성이 한정적이다. 최근에는 text guidance를 이용한 image synthesis가 이목을 끌었지만, 공간적 특성을 바꾸는데 있어서 정확성이나 유연성이 떨어진다는 한계점이 있었다.
본 논문에서는 한계점을 극복할 수 있는 해결책으로 interactive point-based manipulation을 제시하였고, 이것을 구현된 모델로 DragGAN을 제안한다.
2. Method
latent code w로 GAN을 통해 생성된 임의의 이미지 가 있다고 하자. User는 input으로 n개의 handle point { }와 n개의 target point{ }를 지정해준다.
이미지 변형(image manipulation)은 optimization을 수행하는 맥락으로 이해할 수 있는데, 각 optimization 단계는 두 가지로 세분화될 수 있다. 하나는 motion supervision으로, 여기서는 handle point를 target point로 움직이게 하는 loss가 latent code w를 최적화하는데 사용된다. 이때 최적화 과정에서 물체는 미세하게 움직일 수 있다.
하지만 물체에 따라, 그리고 위치에 따라서 움직이는 정도가 다 다르기에 motion supervision은 새로운 handle point의 위치를 정확하게 제공해 주지 않는다. 따라서 다음 handle point 위치의 update, 즉, point tracking이 필요하다.
아래 그림은 Draggan이 작동하는 방법에 대한 것인데, 왼쪽에서부터 첫 번째 그림에서 두 번째 그림으로 넘어가는 부분이 Motion Supervision, 두 번째 그림에서 세 번째 그림으로 넘어가는 부분이 Point Tracking이다.
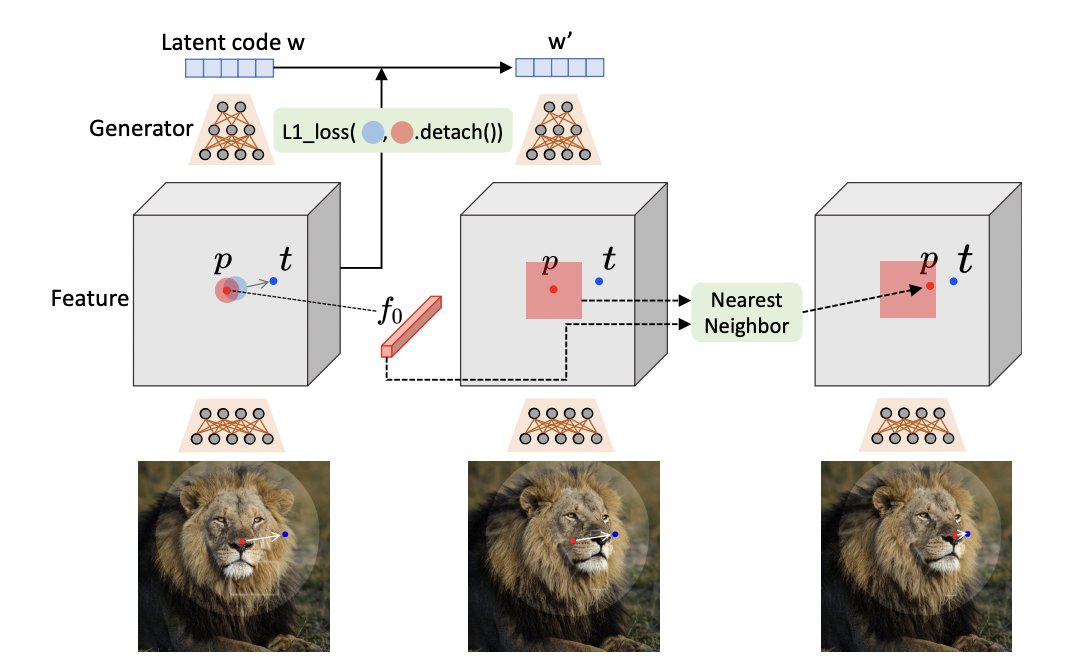
2-1. Motion Supervision
GAN으로 생성된 이미지에서 점의 이동을 지도하는 것은 연구된 바가 많지 않다. 본 논문에서는 추가적인 network에 의존하지 않는 motion supervision loss를 제안한다.
Motion supervision의 핵심은 GAN의 Generator의 중간 단계 feature가 매우 명확하게 구분이 된다는 점인데, 이는 즉 편집을 했을 때 더 명확한 변화가 관찰된다 정도로 해석할 수 있다.
- 그 이유는 아래 그림을 통해 알 수 있는데, input으로 주어지는 latent code W를 사용하는 것보다 layer를 통과한 를 사용하는 것이 '분포 밖'의 변화를 가하는데 용이하기 때문
실험을 통해서 StyleGAN2의 6번째 블럭(layer)을 통과한 feature map이 가장 적절한 resolution과 판별능력의 tradeoff를 갖는다는 것을 확인하였다.

DragGAN은 handle point 주위에 있는 작은 패치들을 target point로 지도하는데 이때 사용되는 motion supervision loss 는 다음과 같다.
이제 각각의 term 을 살펴보자.
| Terms | Definition |
|---|---|
| n | motion supervision 은 n 단계에 걸쳐 진행됨 |
| 까지의 거리가 보다 짧은 픽셀들 | |
| 픽셀 에서의 feature 값 | |
| 에서 를 향하는 벡터를 normalize한 것 | |
| 1-M | Mask하지 않은 부분 즉, 불변하는 부분 |
| Reconstruction loss |
2-2. Point Tracking
Motion을 움직이고 난 후에는 정확히 handle point가 어디로 이동했는지 그 새로운 위치를 찾아내야 한다. 보편적으로 point tracking은 optical flow estimation model이나 particle video approach를 통해 이루어지는데, 아까도 언급했지만 추가적인 모델을 활용하는 것은 효율성을 해칠 뿐 아니라 error의 누적을 야기한다. 그리고 이는 'alias artifacts', 즉 왜곡된 이미지를 생성하는 특성이 존재하는 GAN에게 있어서 치명적일 수 있다.
본 논문에서는 feature patch에서 가장 가까운 이웃을 찾는 방식으로 point tracking 문제를 접근한다. 최초의 handle point를 라고 하고 그 feature를 라고 하면, 를 둘러싼 patch는 다음과 같이 정의될 수 있다.
그리고 에서 의 가장 가까운 이웃을 찾아 를 업데이트 해준다.
3. Implementation Details
Motion Supervision과 Point Tracking에 사용된 거리 값인 과 는 hyperparameter로 실험에서는 각각 3, 12의 값을 사용했고, motion supervision loss에서의 값은 20으로 설정하였다.
Optimization은 모든 handle point의 target point와의 거리가 d pixel 이하일 때까지 진행되었다.
4. Discussions
4-1. Effects of Mask
 Mask 없이는 위 개 그림에서 머리가 아닌 몸통이 통째로 움직이는 문제가 발생한다. 이는 즉 point-based manipulation의 결과가 여러 가지로 나올 수 있다는 뜻이고, GAN이 image manifold에서 가장 정답에 가까운 것을 찾아내려고 한다는 것을 알 수 있다. 따라서 mask는 이미지의 특정 부분을 불변하도록 고정할 뿐 아니라 GAN으로 하여금 모호함을 줄여주는 중요한 역할을 한다.
Mask 없이는 위 개 그림에서 머리가 아닌 몸통이 통째로 움직이는 문제가 발생한다. 이는 즉 point-based manipulation의 결과가 여러 가지로 나올 수 있다는 뜻이고, GAN이 image manifold에서 가장 정답에 가까운 것을 찾아내려고 한다는 것을 알 수 있다. 따라서 mask는 이미지의 특정 부분을 불변하도록 고정할 뿐 아니라 GAN으로 하여금 모호함을 줄여주는 중요한 역할을 한다.
4-2. Out-of-Distribution Manipulation

DragGAN의 또 하나의 강점은 학습된 이미지 데이터 분포 밖에 있는 변형 역시 생성해낼 수 있다는 점이다.
*만약 사용자가 항상 이미지를 학습된 분포 내에 두고 생성해내고 싶다면, latent code w에 추가적인 regularization을 더해주는 잠재적인 방법도 있다고 한다.
4-3. Limitations

한계점이 있다면 편집의 퀄리티가 여전히 학습된 데이터의 다양성에 영향을 받는다는 점이다. 위 그림처럼 인간 포즈를 학습된 데이터 분포를 벗어나게 생성한다면, 가짜 이미지가 된다. 또한, Texture가 부족한 부분에 handle point를 설정한다면 tracking이 어렵다.
마지막으로 논문에서는 사회적/윤리적 문제를 우려하고 있다. DragGAN은 이미지들의 공간적 특성을 변형할 수 있기에 실제 사람이 허구의 포즈, 표정 등을 짓도록 악용될 우려가 있다.
개인적인 생각...
거의 chatgpt 급인 것 같다. 깃허브에 딸랑 read.md랑 gif로 ui만 올라와있는데 스타가 만개다. 누가 구현도 해놓은 것 같은데 official code인지는 모르겠다.
