논문 링크
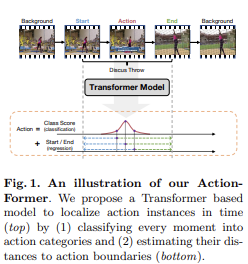
ActionFormer:트랜스포머 네트워크를 비디오에서의 Temporal Action Localization(TAL)에 적용하는 모델임
(TAL은 시간 내의 액션을 식별하고 그 카테고리를 단일 샷으로 인식하는 것)
=> Multiscale Feature Representation+ Local Self-Attention
가벼운 디코더를 사용하여 매 순간을 분류하고 해당 액션 경계를 추정한다.
ActionFormer는 입력 비디오에서 Feature Pyramid를 추출하기 위해 local self attention을 통합한다.

AI 개발자