1. Abstract
Audio-visual segmentation(AVS)는 주어진 비디오에서 소리 나는 물체의 위치를 찾아내고 분할 하는 것을 목표로 함
하지만 대부분의 방법들은 여러 상황에 세밀한 상관 관계를 동적으로 잘 처리하지 못한다.
AVSegFormer는
- 관심 있는 시각적 특징을 동적으로 조정할 수 있는 dense audio-visual mixer
- audio source를 암묵적으로 분리하고 최적의 시각적 특징을 자동으로 매칭하는 audio-visual decoder
로 구성되어 있습니다.
=> 이 두 구성요소를 결합하면 더 견고한 양방향 멀티모달 표현이 제공되어 다양한 시나리오에서 분할 성능이 향상됨
2. Introduction
audio-visual understanding task에서는 두가지 접근법이 있다.
- coarse-grained : audio-visual correspondence, audio-visual event localization, audio-visual video parsing
- fine-grained : audio-visual segmentation(이 task에는 3가지 sub-task가 있음 S4, MS3, AVSS)
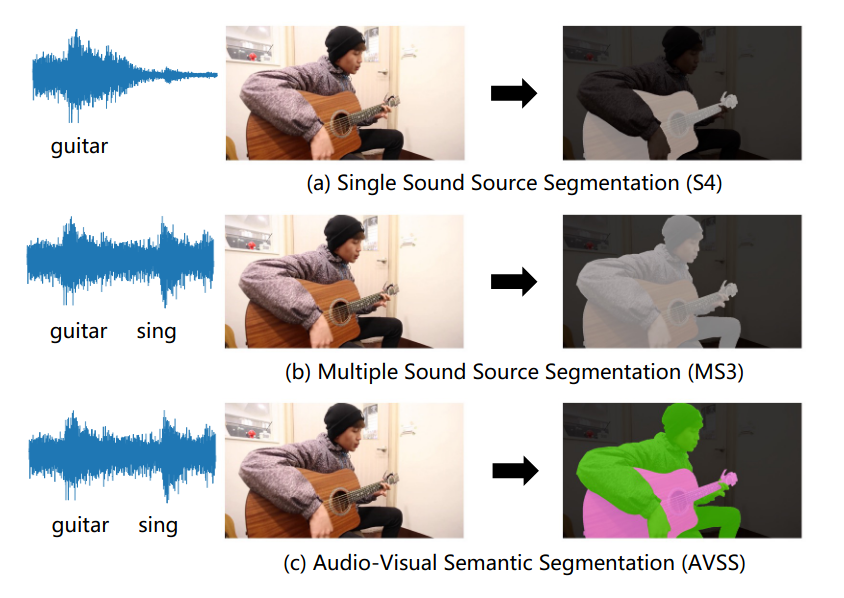
AVSBench
- AVS task를 fine-grained 방식으로 수행한 첫번째 논문임
- 모달리티 융합 모듈을 통합한 네트워크 아키텍처
- 간단하고 효과적이지만 다양한 상황에서 오디오와 시각적 신호 간의 상관관계를 탐구하지 못함
(여러 소리가 섞여 있을 때, 정보가 너무 많아서 비주얼 신호에 집중해서 연결하는 것이 힘듦
or
여러 객체가 동시에 있을 때, 소리를 정확하게 분리하기 어려움)
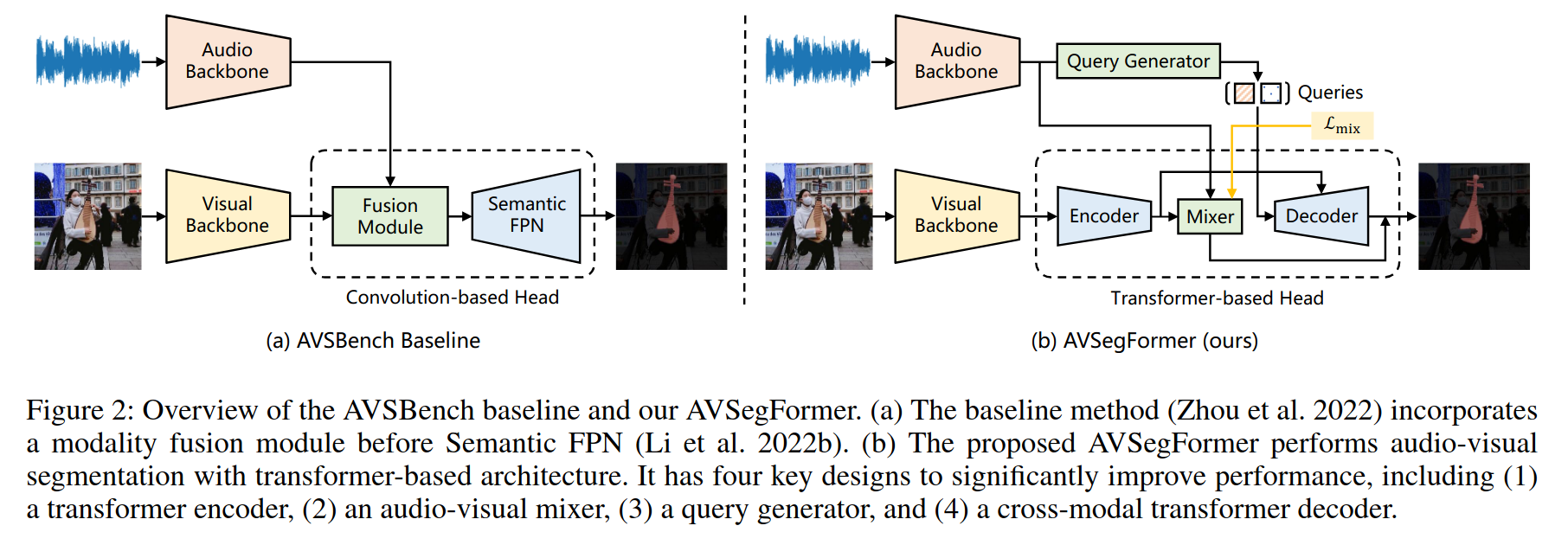
=> 이 문제를 해결하기 위해 나온게 AVSegFormer
AVSegFormer
-
4가지 구성요소로 이루어져 있음
(1. 마스크 특징을 생성하는 transformer 인코더 / 2. 시각 기반 마스크 특징을 생성하는 audio-visual mixer / 3. 희소한 오디오 기반 쿼리를 초기화하는 쿼리 생성기 / 4. 시각적 특징에서 희소 객체를 분리하는 cross-modal transformer decoder) -
auxiliary mixing loss- audio-visual mixer가 생성한 정보를 더 잘 활용하기 위해 손실함수를 변형함
-
cross-modal transformer decoder- 기존과 다르게 소리 정보를 바탕으로 희소한 쿼리를 만들어내는 걸 목표로 함
이 쿼리들은 특징맵과 합쳐져서 최종적으로 소리와 물체를 분할하는데 사용됨
<과정>
1. 특별한 손실 함수를 추가해서 복잡한 소리 안에서도 중요한 정보를 잘 찾을 수 있도록 모델을 훈련시키고,
2. 소리마다 맞는 물체를 찾기 위해 쿼리 (질문)을 던지고, 그에 맞는 정보를 영상에서 찾아서
3. 소리와 영상 정보를 합쳐서 각 물체를 정확히 분할하는 과정을 거침
Methods
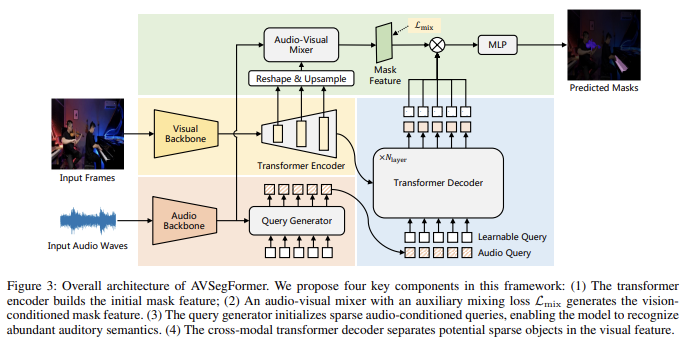
Overall Architecture
쿼리 생성기: 오디오 쿼리를 초기화, transformer encoder가 특징 추출=> transformer decoder에 입력으로 제공해서 희소 객체 분리
mixer: 관련된 특징 증폭, 관련 없는 특징 억제, 손실이 강화된 특징을 잡음
encoder
visual encoder, audio encoder는 이전 방법과 도일하게 특징 추출 과정 거침
Query Generator
희소한 오디오 쿼리를 생성하도록 설계, 모델이 청각 정보를 이해할수 있게
오디오를 key와 value로 사용해서 쿼리 생성기에 입력하고 오디오 쿼리를 얻음
오디오 쿼리와 학습 가능한 쿼리를 결합하여 transformer 디코더의 입력으로 사용함
Transformer Encoder
마스크 특징을 만드는 역할
Audio-Visual Mixer
기존의 방식은 눈에 띄지 않는 소리의 객체를 식별하는 모델의 능력을 저하시킴
=> mixer는 오디오-비주얼 cross attention을 통해 가중치 𝜔를 학습하고, 관련 있는 채널을 강조하는 방식으로 적용
Transformer Dencoder
잠재적인 희소 쿼리 생성, 시각적 특징을 해당 쿼리와 최적으로 매칭하도록 설계
Loss Function
- auxiliary mixing loss(보조 혼합 손실)
이 모델은 복잡한 장면에서는 여전히 성능이 좋지 않아서 혼합 손실 Lmix를 설계함
-
마스크 특징 통합: 모델이 생성한 마스크 특징
𝐹^ mask을 하나의 선형 레이어를 통과시켜 통합한 뒤, 이진 마스크를 예측함 -
gt에서 객체가 있는 부분만을 추출하여 새로운 이진 레이블을 만듬
-
Dice 손실 계산: 예측된 이진 마스크와 실제 이진 마스크 사이의 차이를 측정하기 위해 Dice 손실을 계산
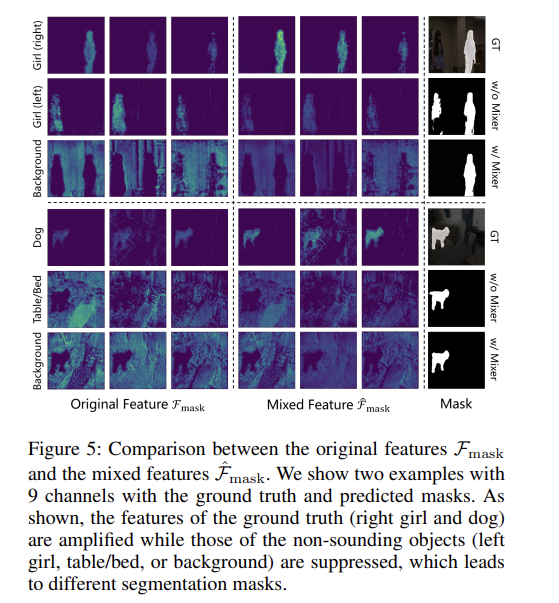
=> dog는 점점 진해지고 소리 안나는 책상이나 이런건 더 연해짐
교수님 피드백
-
특색이 다른 데이터셋을 구축
-
소리에 대한 관심, audio source에 대한 특징을 더 공부
-
왜 분할이 필요한지 localization을 통해 바운딩 박스를 만들고 segmentation을 하면 two stage
-
박스는 모양이 다양할때 빈공간이 많음, 다른 것도 많이 들어옴 error를 만듦 써먹기가 어려움, 부정확한 정보를 가지고 학습한거
-
소리가 같이 들어올때 의미
-
semantic segmentation
-
모션을 보는게 좋을까 event 소리가 주는 정보를 쫌 써먹자 impact에 대해서 인지
-
visual grounding을 통해서 사람이 기타를 쳤다 이거를 알면 graph를 써서 주어 서술어 목적어
소리가 진짜 나야지 사람과 object와의 관계를 보고 impact
표현하는 부분을 보기 관계에 대해서 생각ㅇ하자 -
event 정의하는 거 -> 시간으로 하는지 , 변화하는 순간인지
scene generalization하는거
사이사이 impact가 있어서 기타가 소리를 내는구나가 되게
눈은 속지만 빠르게 지나가는건 못 잡음
그치만 소리는 잡을수 있따 -
소리가 어디서 나오는지 타겟하자
context를 이용하자
