Dataset
1. Audio-Visual Event (AVE) Dataset
페이지 링크: Audio-Visual Event Localization in Unconstrained Videos
=> 이 링크에 있는 데모 영상을 보면 이해가 쉽습니다.
AVE 데이터셋을 다운로드 해보니,
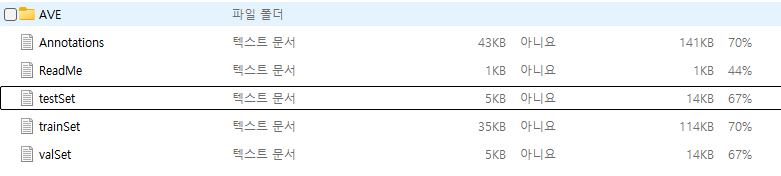
이런식으로 trainset, testset, valset, annotation 파일들이 있었고,
데이터셋은
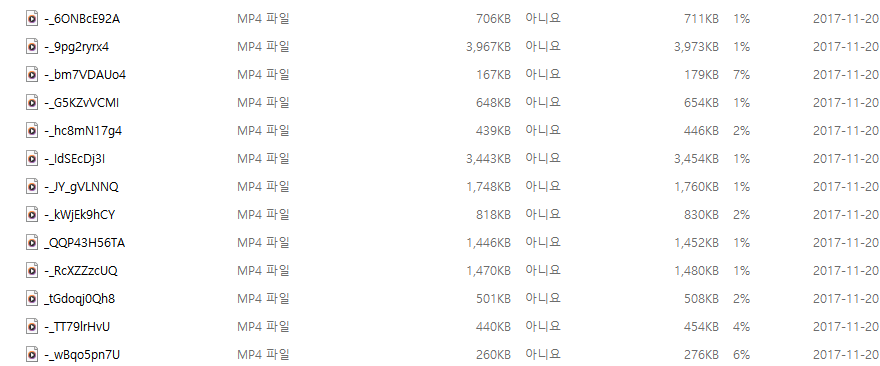
짧은 영상들이 4097개 있었습니다. 주로 9초대의 영상들로 이루어져 있었고, 항목은 동물 소리, (소방차/비행기/오토바이) 차 소리, 연설, 악기 소리 등등이 있었습니다.

Task
- Supervised audio-visual event localization
: 비디오와 오디오 데이터를 둘다 사용하여 특정 이벤트가 발생하는 위치를 정확하게 찾아내는 것입니다. - Weakly-supervised audio-visual event localization (label이 완벽하지 않을 때)
: visual_feature_noisy.h5 파일에 포함된 데이터는 오디오-비주얼 이벤트가 발생하지 않는 비디오에서 추출된 비주얼 특징들입니다. 이를 학습 데이터에 포함시켜 모델이 배경과 사건을 구분할 수 있도록 도와줍니다. - Cross-modality localization
2. VGG-Sound Dataset
VGG-Sound Page link
VGG 논문 링크
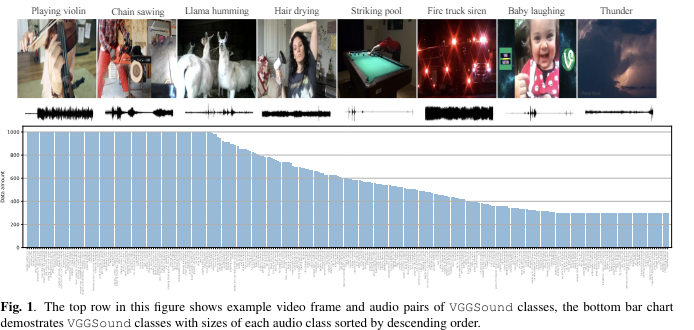
컴퓨터 비전 기술을 이용해 유튜브 비디오로부터 라벨 노이즈가 적은 대규모 오디오-비주얼 데이터셋을 수집하는 방법을 제안합니다.
이를 통해 300개의 오디오 클래스를 포함하는 200,000개 이상의 비디오로 구성된 VGGSound 데이터셋을 생성했습니다.
이 데이터를 다운받으려면 다른 데이터셋들처럼 한번에 다운로드 받지는 못하고 코드를 작성해야합니다.
참고 깃허브링크
3. STARSS23 Dataset
STARSS23 논문 링크
STARSS23 페이지 링크
demo
STARSS23은 다채널 오디오, 비디오, 그리고 프레임별로 시간적 및 공간적 주석 (활동 및 DOA label)을 포함하는 새로운 데이터셋입니다.
소리 이벤트는 시각적으로 인식 가능한 소스 객체에서 발생합니다. 예를 들어, 발자국 소리는 걷는 사람의 발에서 발생합니다.
이 논문에서는 다채널 오디오와 비디오 정보를 사용하여 소리 이벤트의 시간적 활성화와 DOA(소리 이벤트의 방향각)를 추정하는 오디오-비주얼 소리 이벤트 로컬라이제이션 및 감지(SELD-sound event localization and detection) 작업을 제안합니다. 오디오-비주얼 SELD 시스템은 마이크로폰 배열의 신호와 오디오-비주얼 대응을 사용하여 소리 이벤트를 감지하고 localize할 수 있습니다.
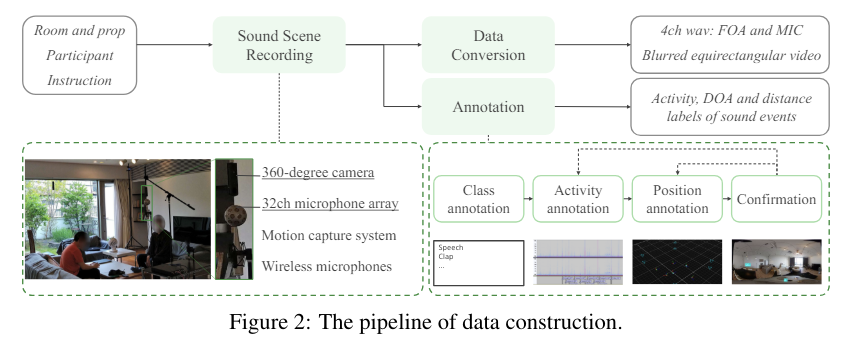
57명의 참가자가 16개의 방에서 녹음한 7시간 이상의 자료를 포함하며, 13개의 소리 이벤트 클래스를 다룹니다.
0. Female speech, woman speaking
1. Male speech, man speaking
2. Clapping
3. Telephone
4. Laughter
5. Domestic sounds
6. Walk, footsteps
7. Door, open or close
8. Music
9. Musical instrument
10. Water tap, faucet
11. Bell
12. Knock
데이터 영상을 직접 다운로드 해서 봤습니다. 
Kaggle Task
캐글에는 관련된 task가 별로 없었습니다. 그나마 제일 유사해보인게 이 kaggle task였습니다. 이 task가 적합한지 확실하지 않아 아직 돌려보지는 못했습니다.
audio/urban sound detection kaggle
