Abstract
오디오와 비주얼 모달리티 간의 관계를 활용하는 오디오-비주얼 학습이 주목을 받고 있습니다.
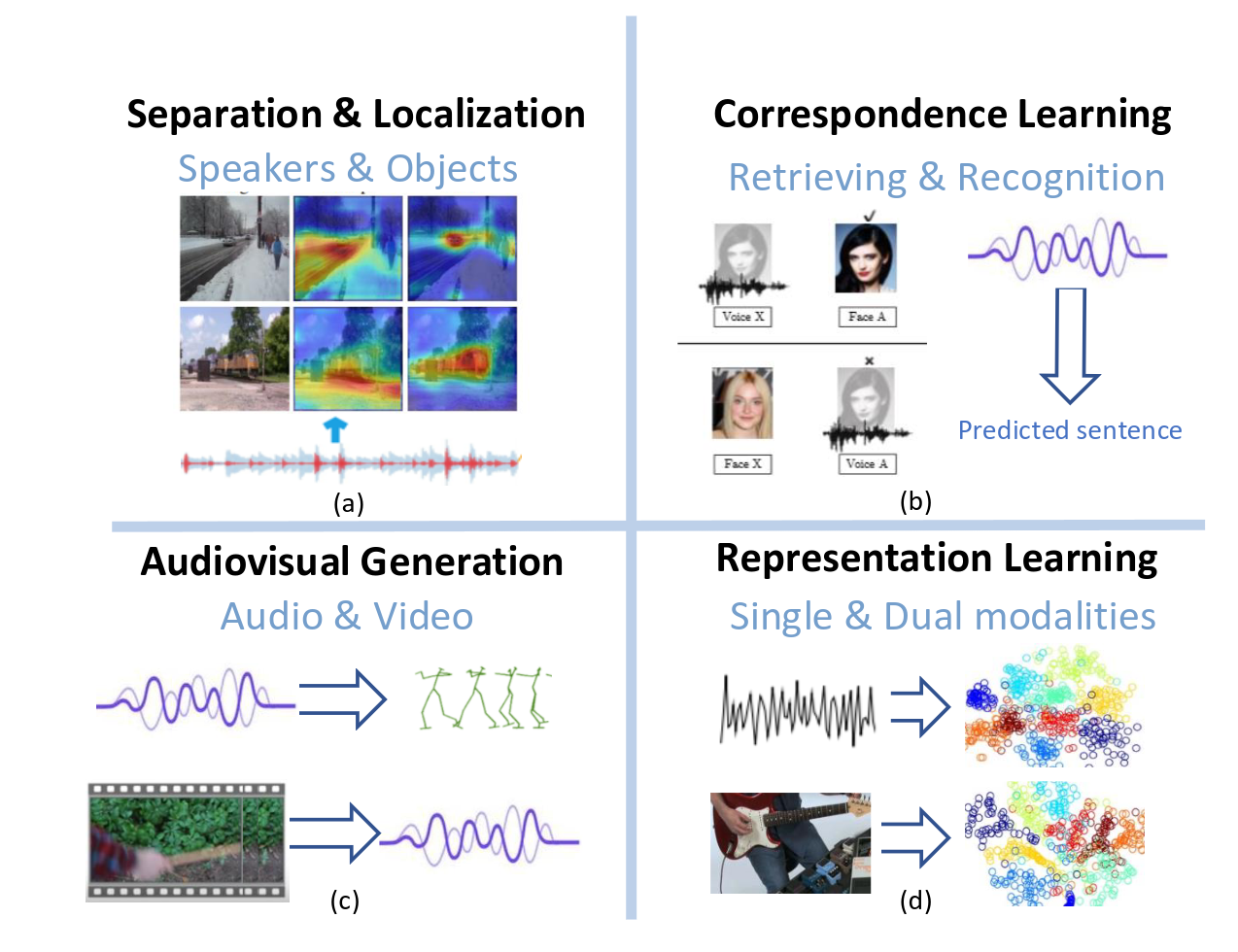
- audio-visual separation and localization
- audio-visual correspondence learning (대응학습)
- audio-visual generation (생성)
- audio-visual representation learning
내용
- audio-visual separation and localization
해당 물체로부터 나오는 특정 소리를 분리하고 시각적 맥락에서 각 소리를 위치 추적하는 것을 목표로 한다.
-
Speaker Separation: 소음이 많은 장면에서 단일 음성 신호를 분리하는 것을 목표로 한다.
-- 소음 소리에서 직접 목표 목소리를 추출하는 대신에 비디오 프레임을 비디오-음성 모델에 입력한 다음에 캡쳐된 얼굴 움직임으로 목소리를 예측하는 방식을 씀
-- 관심 있는 각 연사에 대해 별도의 모델을 훈련해야하는 방식과 달리, 한번만 훈련하고 모든 연사에 적용 가능한 연사 독립 모델 제안
-- 오디오-비주얼 매칭 네트워크 강화하여 음성과 인간 입술 움직임 간의 대응을 구별함 -
Separating and Localizing Objects' Sounds
-- 인터넷에서 레이블이 없는 비디오의 수가 급격히 증가하여 최근 방법은 주로 비지도 학습에 초점을 맞추고 있음
-- 학습된 attention을 통해 소리를 내는 객체의 의미를 캡쳐하고 시간 정렬을 활용하여 두 모달리티 간의 상관관계를 발견하는 방법을 제안함
- audio-visual correspondence learning
오디오와 비주얼 모달리티 간의 의미 관계를 발견하는 것을 목표로 한다.
- 오디오-비주얼 매칭-> 예를 들어 피아노를 연주하는 소녀 사진이 주어지면 피아노 소리를 반환하는 것이 된다.
- 오디오-비주얼 음성인식-> 사람의 음성을 정확하게 인식하고 이해하는데 초점
- audio-visual generation
한 모달리티를 기반으로 다른 모달리티를 합성하려고 한다. 시각신호로부터 오디오를 생성하는 것 or 오디오로부터 시각 신호를 생성하는 것을 목표로 함
주어진 장면에서 발생할 수 있는 소리를 예측하는 데 중점을 둠
- Visual to Audio
- Audio to Visual
- audio-visual representation learning
원시데이터로부터 표현을 자동으로 발견하는 것을 목표로 함
모델이 데이터에서 패턴을 찾아 유용한 표현을 학습하게 됨
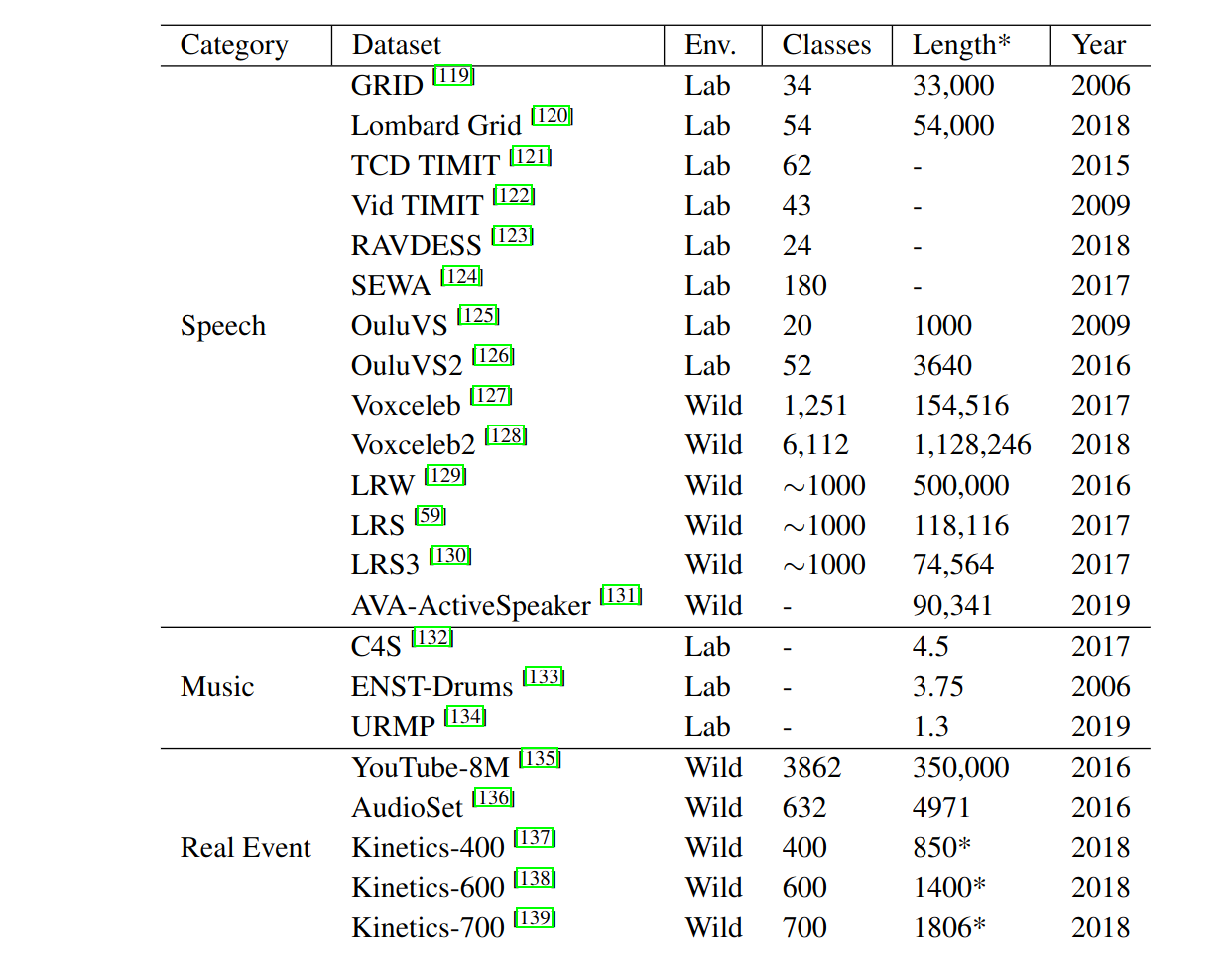
Dataset

Speech-realated audio-visual datasets

AI 개발자