Intro
비디오에 존재하는 오디오비주얼 정보를 활용하여 자기 지도 표현 학습을 개선할 것을 제안합니다.
=> 오디오비주얼 다운스트림 분류 작업에서 상당한 개선을 달성할 수 있으며, VGGSound와 AudioSet에서 최첨단 성능을 능가함
비디오와 오디오의 상관관계를 활용하여 데이터 표현 학습을 잘하는 것이 목표입니다.
masked autoencoding framework를 기반으로 함
깃허브 링크
Audiovisual masked AutoEncoders
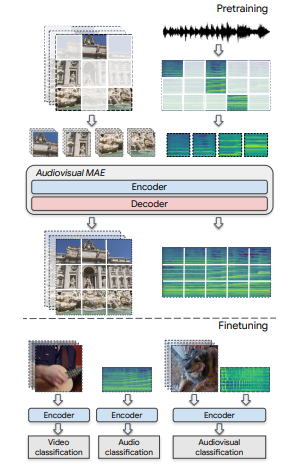
masked-autoencoding framework를 확장하여 멀티모달/단일모달 다운스트림 작업에 활용할 수 있는 오디오 비주얼 특징 표현을 학습한다.
Audiovisual encoders
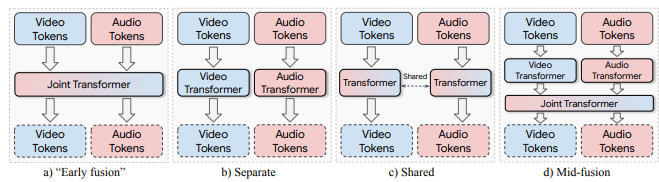
1. Early fusion - 각 모달리티의 마스크 되지 않은 토큰을 결합 후 단일 트랜스포머에 전달합니다.
2. Separate - 두개의 별도 인코더를 사용하여 오디오와 비디오 토큰을 각각 다른 매개변수로 인코딩합니다.
3. Mid-fusion - 트랜스포머 레이어의 총 수 = L, 처음 L−S 레이어는 "분리된" 인코딩 접근 방식과 같이 각 모달리티에 대해 별도로 처리, 이후 S ≥ 1 레이어를 통해 두 모달리티를 공동으로 처리
4. Shared - 마지막으로 매개변수 공유를 통해 두 모달리티를 결합하는 방법을 탐구합니다. separate 방법과 동일하지만 가중치가 공유되는 방식입니다.
Decoders

AI 개발자