1. IIANET: An Intra-and Inter-Modality Attention Network for Audio-Visual Speech Separation
간단 요약
대부분 오디오-비주얼 음성 분리에서 멀티모달 융합에 초점을 두고 selective attention 메커니즘을 사용하지는 않습니다. 그래서 IIANET이라는 오디오 비주얼 특징 융합을 위한 attention 메커니즘을 활용한 모델을 만들었습니다.
attention block- Intra attention/ Inter attention 이렇게 두개로 구성되어 있습니다.
(IIANET의 빠른 버전인 IIANET-Fast도 있습니다.)
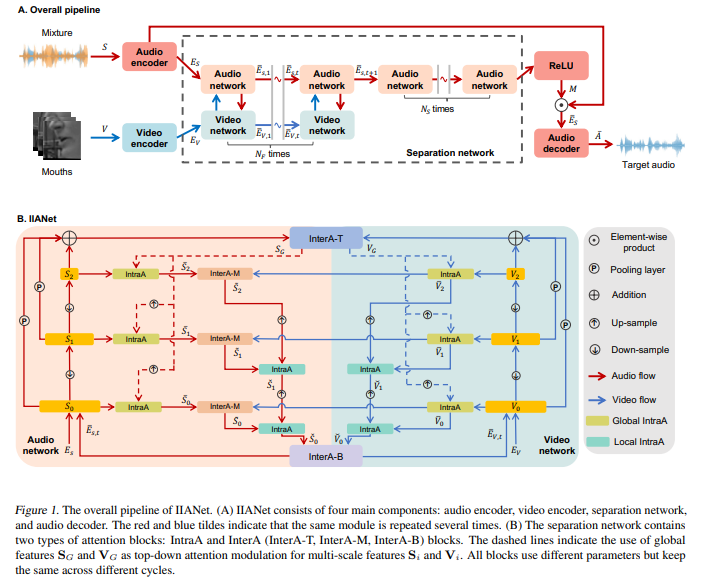
네가지 모듈로 구성되어있습니다 - 오디오 인코더, 비디오 인코더, 분리 네트워크,오디오 디코더
과정
1. 입술 추출: 2명의 화자가 포함된 비디오에서 각 이미지 프레임으로부터 입술 영역을 추출합니다.
2. 입술 및 잡음 음성 인코딩: 비디오 인코더를 통해 입술 프레임을 입술 임베딩으로, 오디오 인코더를 통해 잡음이 섞인 음성을 잡음 음성 임베딩으로 인코딩합니다.
3. 타겟 화자의 음성 임베딩 추정: 분리 네트워크는 입술 임베딩과 잡음 음성 임베딩을 입력으로 받아 소프트 마스크를 생성합니다. 그 후, 잡음 음성 임베딩에 소프트 마스크를 곱하여 타겟 화자의 음성 임베딩을 추정합니다.
4. 타겟 화자의 음성 생성: 오디오 디코더를 이용하여 추정된 타겟 화자의 음성 임베딩을 실제 음성 신호로 변환합니다.
=> 잡음 섞인 음성에서 타겟 화자의 깨끗한 음성 분리 가능
2. STELLA: Continual Audio-Video Pre-training with SpatioTemporal Localized Alignment
간단 요약
오디오-비디오 의미 학습은 중요하지만 두가지 어려운 문제점이 있습니다.
1. 드문 시공산적 상관관계 - 오디오와 비디오가 항상 잘 맞아떨어지지 않을 수도 있습니다.
ex. 누군가가 화면 밖에서 말할 때
2. 멀티모달 상관관계 덮어쓰기 - 새롭게 학습한 내용이 기존에 학습한 오디오-비디오 관계를 잊게 할수도 있습니다.
ex. 새로운 사람의 얼굴, 목소리를 학습하다가 기존에 학습한 사람의 얼굴, 목소리의 연결을 잊을수 있습니다.
이를 해결하기 위해
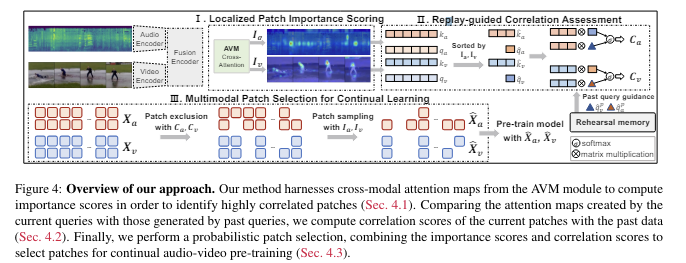
1. 비디오프레임을 여러 조각으로 나눠서 각 패치의 중요도를 평가하여 의미적으로 잘 연결된 패치에 더 높은 점수 부여합니다.
2. 새로운 정보를 학습할때, 이전에 학습한 정보와의 상관관계를 평가하여 중요한 기존정보를 잊지 않도록 합니다.
=> 성능이 3.69% 향상, 메모리 사용량도 45% 줄어들었습니다.
3. EquiAV: Leveraging Equivariance for Audio-Visual Contrastive Learning
간단 요약
데이터 증강 기법이 효과적으로 쓰이게 하기 위해 오디오-비디오 대조 학습을 위해 EquiAV라는 새로운 프레임 워크를 만들었습니다.
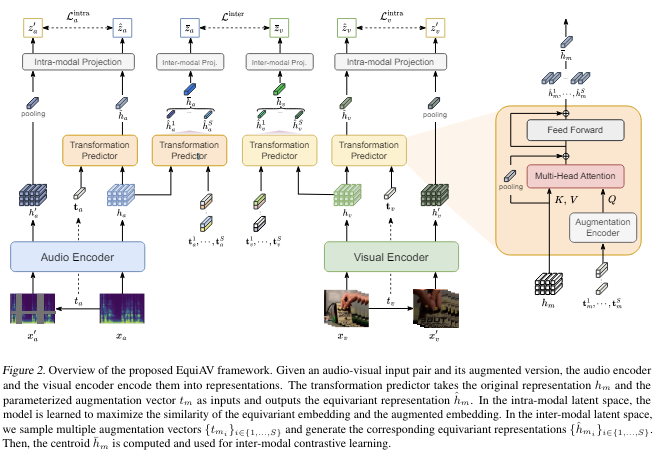
shared attention-based transformation predictor를 사용하여 오디오와 비디오의 변형을 효과적으로 다룹니다.
다양한 데이터 변형에서 얻은 특징을 모아서 하나의 대표적인 표현으로 만듭니다.
-Audioset-2M에 pretrain했습니다.
4. video-SALMONN: Speech-Enhanced Audio-Visual Large Language Models
간단요약
video-SALMONN이라는 single end-to-end audiovisual-LLM을 제안하여 시각적인 프레임 시퀀스, 오디오 이벤트 및 음악뿐만 아니라 음성도 이해할 수 있습니다.
(오디오 인코더 구조를 유사하게 하여 추가적인 시각 인코더를 통합합)
텍스트 표현 공간과 세가지 다른 시간 척도에서 동기화된 audio-visual 입력 특징을 정렬하는 다중 해상도 MRC(인과적) Q-Former 구조를 제안합니다. MRC Q-Former에는 인과 self attention 구조가 포함되어 있음

