모든 사진 자료에 관한 출처는 아래 알튜비튜 - 튜터링에 있음을 밝힙니다.
https://github.com/Altu-Bitu/Notice
<배열에서 중복된 수를 제거한 뒤 오름차순 정렬하기 ver. vector>
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
//배열 1,6,2,1,9,8 에서 중복된 수를 제거한뒤, 오름차순 정렬한 결과는?
vector<int> arr = { 1,6,2,1,9,8 };
vector<int> result;
for (int i = 0; i < arr.size(); i++) { //result 에 arr[i]가 없다면 삽입
if (find(result.begin(), result.end(), arr[i]) == result.end()) //find는 일치하는 원소를 찾지 못할경우 last를 리턴
result.push_back(arr[i]);
}
sort(result.begin(), result.end());//정렬
}→ 시간복잡도 면에서 효율적이지 않고, 코드도 길다.
이때 SET을 이용한다면 ?!
📌SET
- 다양한 자료형의 데이터 저장 (key)
- key값을 중복 없이 저장
- key값을 정렬된 상태로 저장
- 검색,삽입,삭제에서의 시간복잡도는 O(log n)
- 랜덤한 인덱스의 데이터에 접근불가
<배열에서 중복된 수를 제거한 뒤 오름차순 정렬하기 ver. set>
#include <iostream>
#include <vector>
#include <set>
#include <algorithm>
using namespace std;
int main() {
//배열 1,6,2,1,9,8 에서 중복된 수를 제거한뒤, 오름차순 정렬한 결과는?
vector<int> arr = { 1,6,2,1,9,8 };
set<int> result;
for (int i = 0; i < arr.size(); i++) {
result.insert(arr[i]); //insert멤버 함수에 의해 삽입이 되면 키값을 중복없이 저장하며 원소는 자동으로 오름차순으로 정렬된다.
}
}🔎SET의 구조
BST(Binary Search Tree)
- 하나의 parten(root)에 최대 2개의 child가 있음
- 부모의 왼쪽 서브 트리 값들은 모두 부모 노드보다 작음
- 부모의 오른쪽 서브 트리 값들은 모두 부모 노드보다 큼
⚠사실 정확히 말하면 여기서 발전된 형태인 red-black-tree를 사용한다
📎 SET에 데이터 삽입
주어진 값이 현재 노드값보다 작다면 왼쪽으로, 크다면 오른쪽으로 이동시킨다.
♻ SET의 순회
SET의 멤버들에 접근해서 출력하는 방법?
->iterator를 이용한다!
Q. Iterator가 뭔가요?
A. 반복자란 컨테이너에 저장되어 있는 모든 원소들을 전체적으로 훑어 나갈 때 사용하는, 일종의 포인터와 비슷한 객체.
라이브러리의 방식대로 자료구조를 액세스할때 사용.
출처: https://eehoeskrap.tistory.com/263 [Enough is not enough]
<방법 1 자료구조에 맞는 Iterator 선언>
#include <iostream>
#include <vector>
#include <set>
#include <algorithm>
using namespace std;
int main() {
set <int >s;
s.insert(6);
s.insert(5);
s.insert(4);
s.insert(3);
s.insert(2);
s.insert(1);
set<int> ::iterator iter; //포인터와 비슷한 개념.
for (iter = s.begin(); iter != s.end(); iter++)
cout << *iter << ' ';
}결과
1 2 3 4 5 6
<방법 2. Auto Iterator 이용 >
c++은 알아서 자료구조를 인식하여 적합한 iterator를 만들어준다.
#include <iostream>
#include <vector>
#include <set>
#include <algorithm>
using namespace std;
int main() {
set <int >s;
s.insert(6);
s.insert(5);
s.insert(4);
s.insert(3);
s.insert(2);
s.insert(1);
//set<int> ::iterator iter; //포인터와 비슷한 개념.
for ( auto iter = s.begin(); iter != s.end(); iter++)
cout << *iter << ' ';
for (auto iter : s) //향상된 for문
cout << iter << ' ';
}결과
1 2 3 4 5 6
📋 SET의 멤버함수
begin(): 맨 첫번째 원소를 가리키는 반복자를 리턴end(): 맨 마지막 원소+1을 가리키는 반복자를 리턴clear(): 모든 원소를 제거insert(k):원소 k를 자동으로 정렬된 위치에 삽입.insert(iter, k): iter가 가리키는 위치 부터 k를 삽입할 위치를 탐색하여 삽입find(k): 원소 k를 가리키는 반복자를 반환. 원소 k가 없다면 s.end() 와 같이 맨끝을 가리키는 반복자를 반환size(): 사이즈(원소의 갯수)를 반환erase(k/iter):k를 제거, iter가 가리키는 원소를 제거
출처: https://blockdmask.tistory.com/79 [개발자 지망생]
🌐Map
map<자료형, 자료형> m
중복 저장이 되지 않고 값을 순서대로 출력할 수 없는 SET의 기능을 보충하기 위한 방안으로 Set에 좋은 기능은 가져가되, 인덱스를 따로 둠으로써 해당 문제점들을 해결함
- 다양한 자료형의 데이터를 key-value 쌍으로 저장.
- key값을 중복없이 저장.
- key값을 정렬된 상태로 저장.
- 검색, 삽입, 삭제에서의 시간 복잡도는 O(log n)
- 랜덤한 인덱스의 데이터에 접근불가
Q. MAP을 이용하여 다음문제를 푼다면?

1) 구조체와 벡터를 사용한다면?

2) 맵으로 구현시!
: O(logn)의 시간복잡도
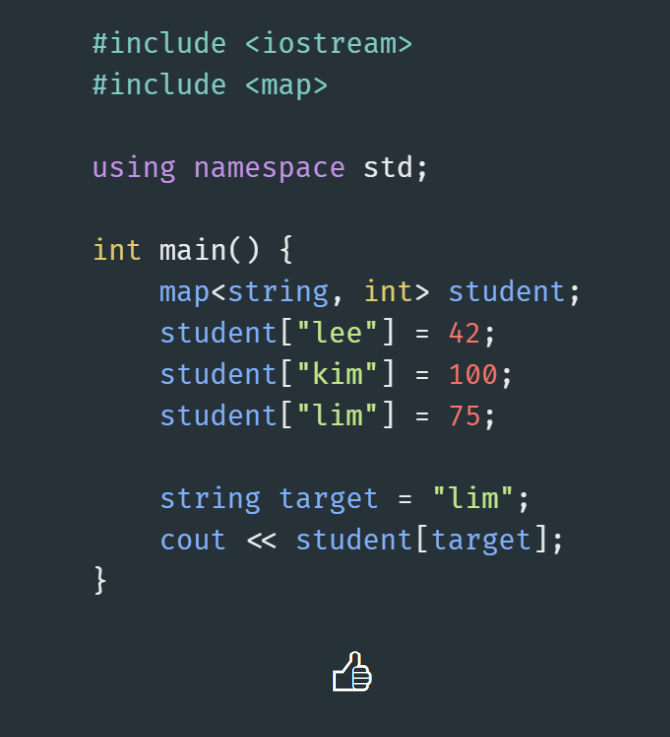
🔎Map의 구조
Set과 동일한 형태!
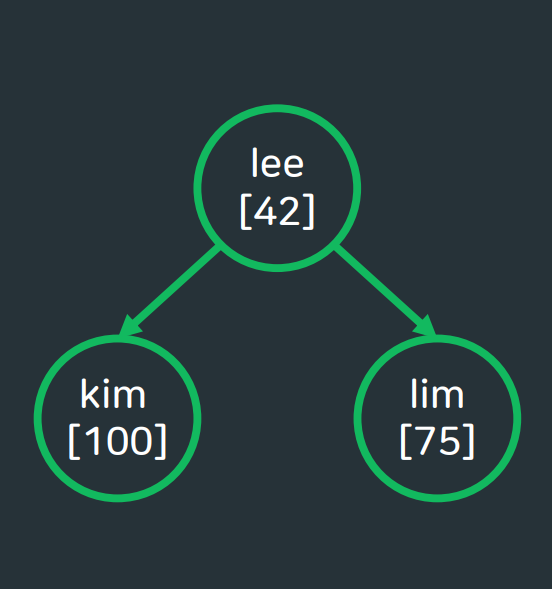
- 하나의 parent(root)에 최대 2개의 child가 있음.
- 부모의 왼쪽 서브트리 값들은 모두 부모 노드보다 작음.
- 부모의 오른쪽 서브트리 값들은 모두 부모 노드보다 큼.
📥맵의 멤버함수
:set의 멤버함수와 거의 동일한 양상을 띰.
해싱 (Hashing)
- 해시 함수를 이용해 key를 특정한 값으로 변환
- 변환된 값은 주소로 사용되며 해당위치에 value 저장
- 암호에 많이 사용됨
- 검색,삽입,삭제 에서의 시간복잡도는 O(1)
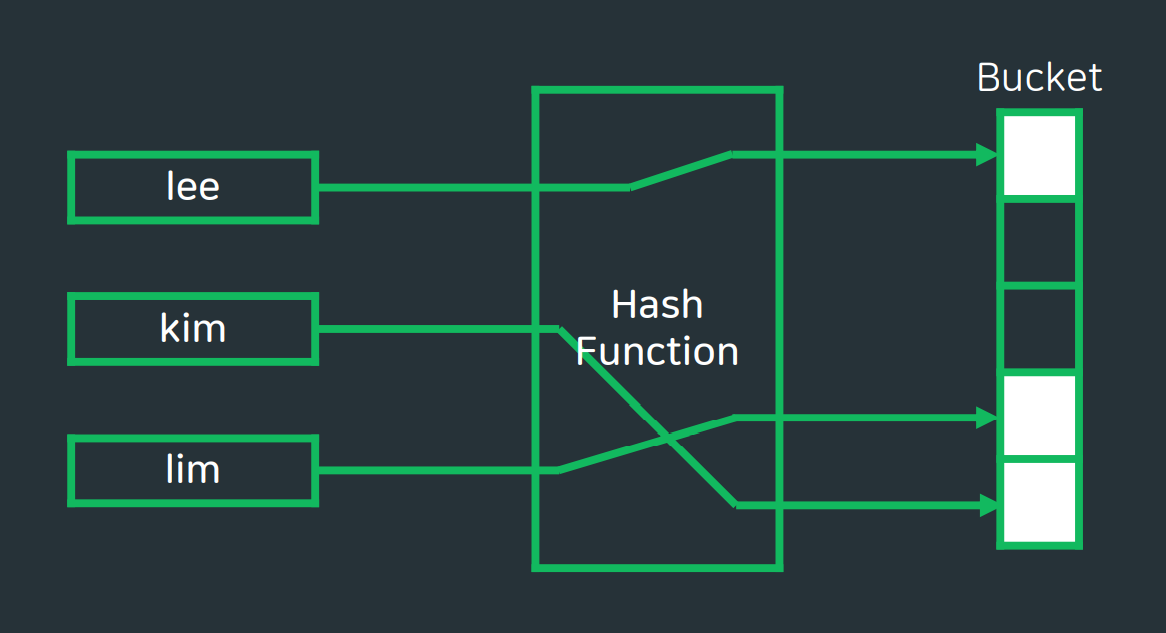
해시함수의 예
해시함수란? 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수.매우 빠른 데이터 검색을 위한 컴퓨터 소프트웨어에 널리 사용

이때 bucket의 크기로 나눈 나머지 값으로 지정하면 bucket의 index를 초과하는 범위에 저장되는 것을 막을 수 있다.
그렇지만, 같은 str(key)값에 대해서 같은 bucket을 mapping 하게 될 염려가 있다.
서로 다른 key의 해시 함수 결과값이 겹친다면?
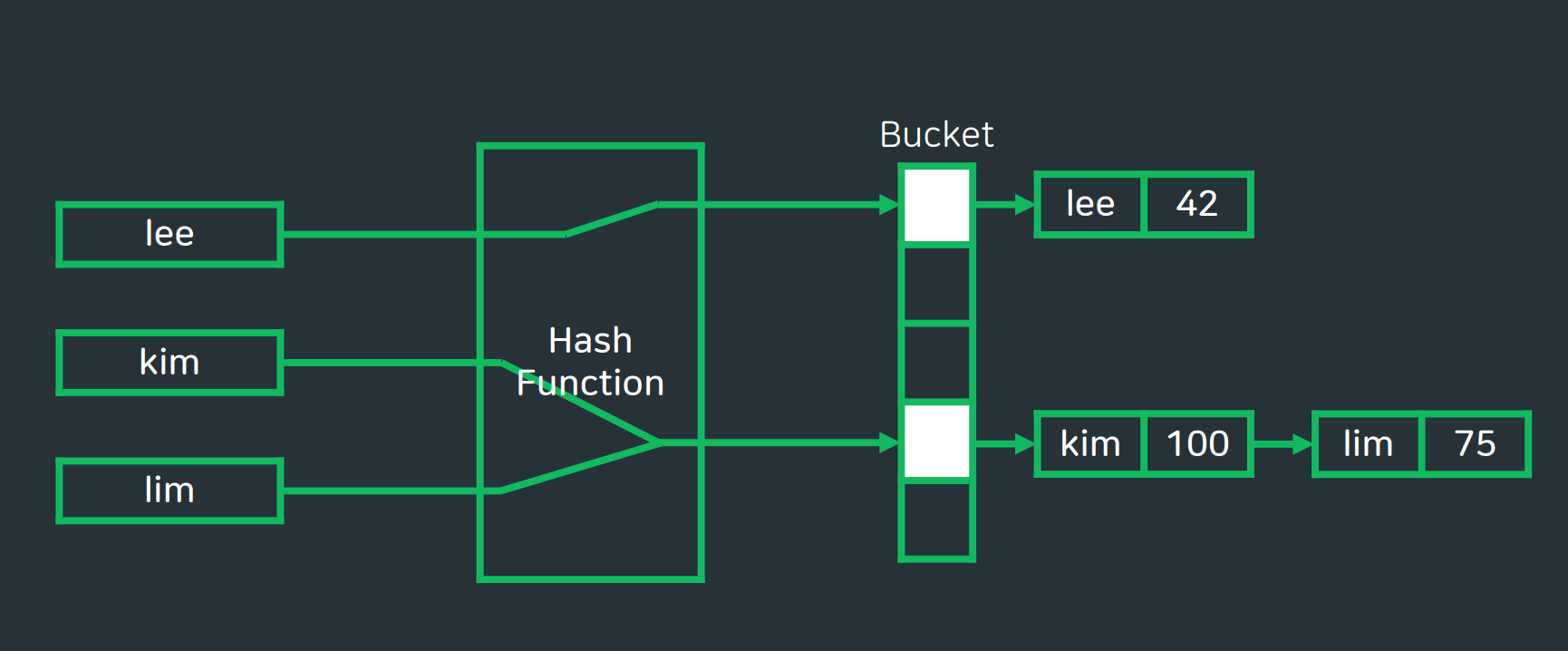
🛠충돌 (Collision)
- 서로 다른 input에 대해 같은 output이 나오는 현상.
- 이중해싱, 재해싱, 기타 등등
- 버킷의 크기를 아주 크게 하면 공간 복잡도로 인한 메모리초과현상 발생.
- 체이닝 :연결 리스트를 이용하여 점유된 슬롯에 자료를 추가하는 방식
📜마무리
- 연관 컨테이너(Set,Map)은 검색에 최적화된 자료구조
- 내부 구조는 BST에서 발전된 형태인 Red-Black Tree
- 기본적으론 key값을 중복없이 정렬된 상태로 저장하지만, 정렬 없이 중복저장하는법도 있음
- set과 map에 저장된 데이터를 순회하기 위해서는 반복자(iteraotr)를 사용해야함.
✨이것도 알아보세요!
- BinarySearchTree와 RedBlackTree의 차이는 뭘까요?
Binary search에서는 평균 트리의 시간복잡도는 O(logn) 이다.
그러나, 아래와 같이 랜덤하게 배치된 BST의 경우 E를 검색하기 위해서는 결국 모든 Node들을 탐색해야 하는 문제가 생겨 최악의 경우 O(n)의 형태가 될 수 있다.
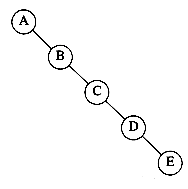
이를 이진탐색트리 불균형(unbalanced Binary tree) 라고 한다.
이를 위해서 고안된 트리가 RBT(Red Black Tree) 이다.
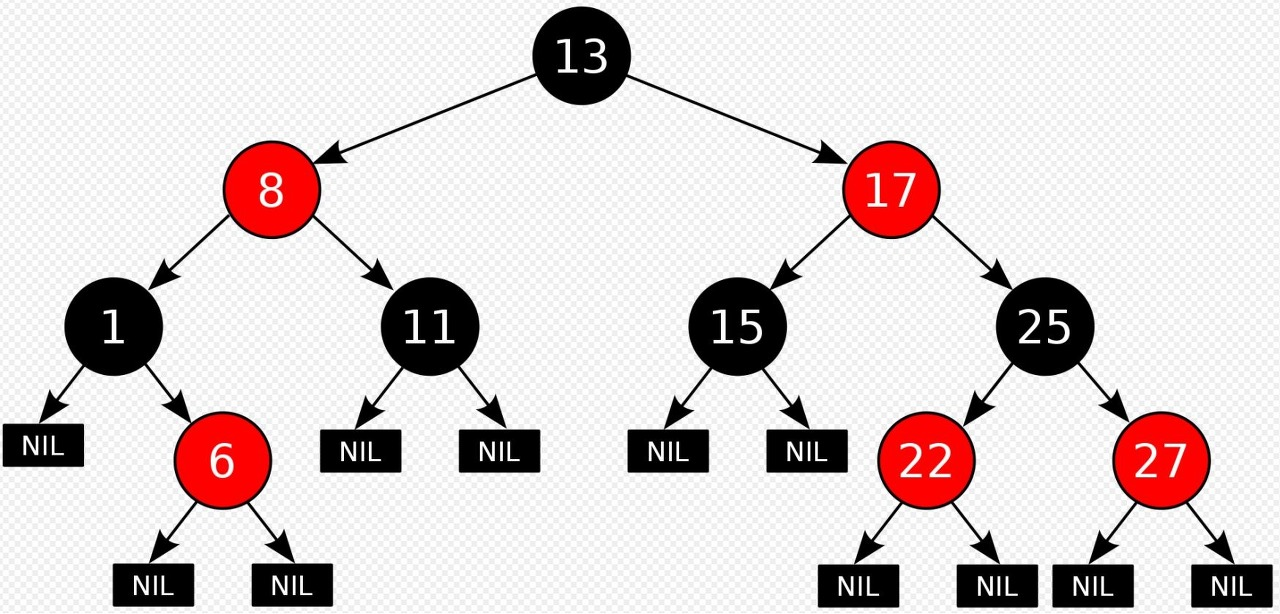
탐색은 BST 와 같은 동작으로 하지만 시간복잡도는 Worst Case 경우 O(logn) 은 충족한다. 그 이유는, 삽입과 삭제에서 기본적으로 트리의 Balance 가 보장되는 구조를 취하기 때문이다.그래서 RBT를 자가균형 이진탐색트리 라고도 불리운다.
출처 : https://dev-tak.tistory.com/6
| BST | RBT | |
|---|---|---|
| 정의 | 이진탐색트리 | 노드가 레드나 블랙인 색상 속성을 가지고 있는 이진 탐색 트리 |
| 평균 시간복잡도 | O(logN) | O(logN) |
| Worstcase | O(N) | O(logn) |
- BST에서 데이터를 삭제하기 위해서는 어떻게 해야할까요?
:우선 삭제하고자 하는 데이터의 자식노드가 몇개인지에 따라 그 방법이 달라질 수 있다.
1) 자식노드가 없을경우
:단순히 해당 노드를 삭제한다.
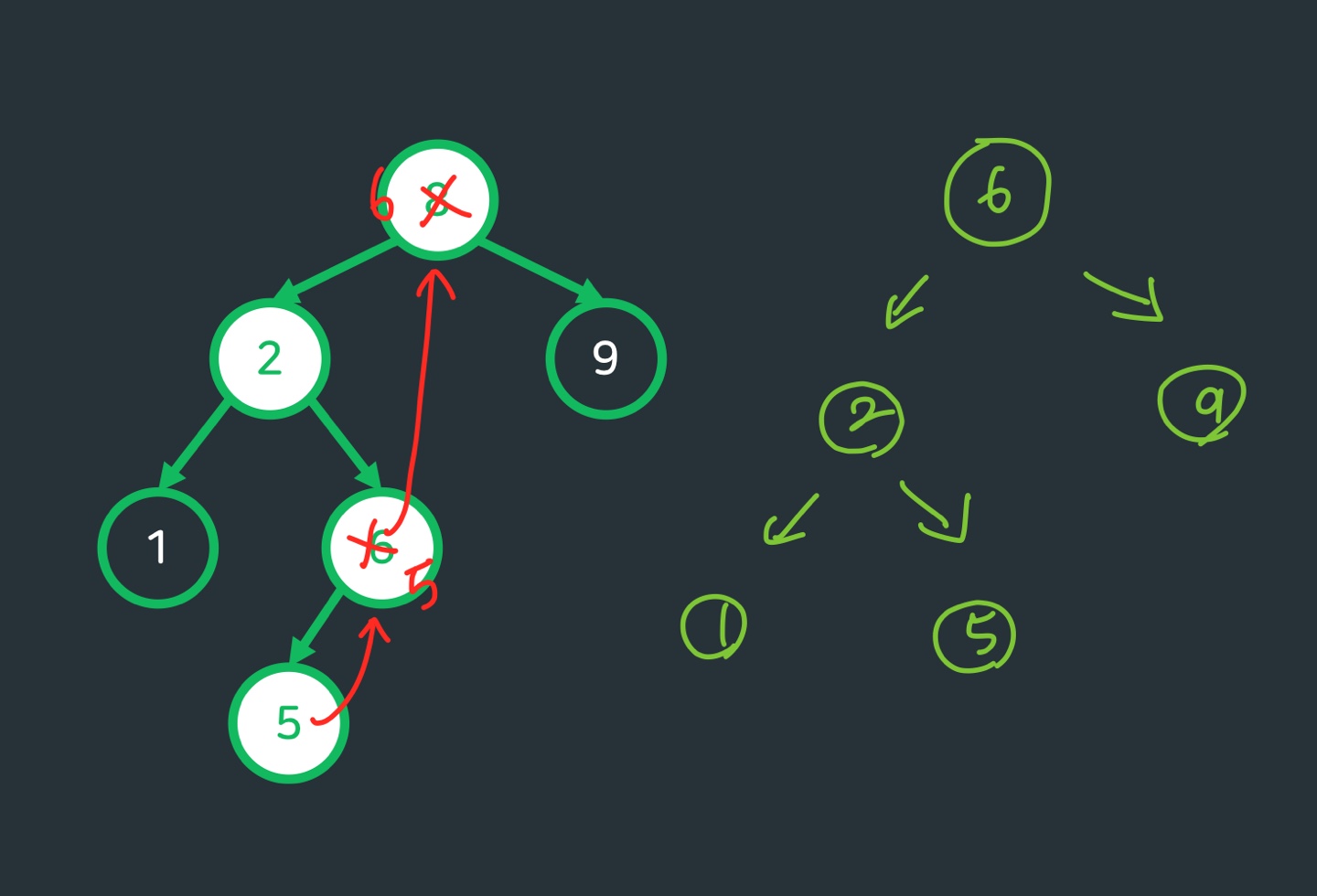
2)자식노드가 1개일경우
:해당 노드를 삭제하고 그 위치에 해당 노드의 자식노드를 대입한다.
![]()
3)자식노드가 2개일경우
:삭제하고자 하는 노드의 값을 해당 노드의 왼쪽 서브트리에서 가장 큰값으로 변경하거나, 오른쪽 서브트리에서 가장 작은 값으로 변경한 뒤, 해당 노드(왼쪽 서브트리에서 가장 큰 값을 가지는 노드 또는 오른쪽 서브트리에서 가장 작은 값을 가지는 노드)를 삭제한다.
- 해시에서 Bucket의 크기를 소수로 하는 이유가 무엇일까요?
: 입력의 분포가 임의적이고 균등하지 않을때 해시 버킷간에 데이터를 가장 잘 분배하기 위해 소수를 선택한다.입력 패턴을 처리 할 때 소수 모듈러스를 사용하면 최상의 분포를 얻을 수 있다.
- 아래 코드의 실행결과는?
map <string, int> m;
int a = m["no_key"];
cout << a;[결과] 0
저장되지 않은 키값을 map의 인덱스로 줄 경우, 0을 반환한다.
반대로 아래의 경우, 김이화라는 키값이 저장되어있으므로 21을 리턴한다.
map <string, int> m;
m.insert( make_pair("김이화", 21));
int a = m["김이화"];
cout << a;
[결과] 21
모든 이미지 출처 : 알튜비튜 2.맵과 셋
