알튜비튜
1.정렬

2.셋과 맵(Set and Map)
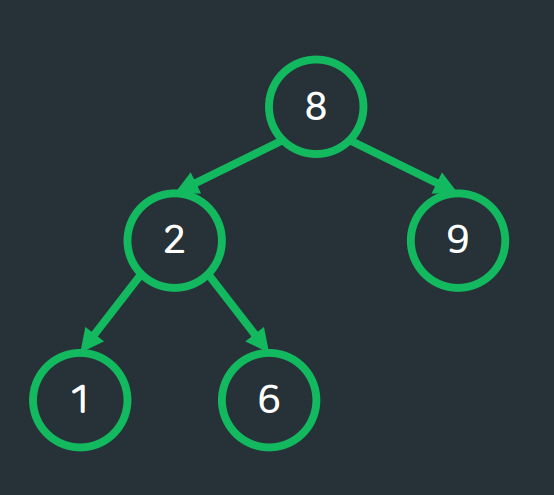
<배열에서 중복된 수를 제거한 뒤 오름차순 정렬하기 ver. vector>→ 시간복잡도 면에서 효율적이지 않고, 코드도 길다.이때 SET을 이용한다면 ?!다양한 자료형의 데이터 저장 (key)key값을 중복 없이 저장key값을 정렬된 상태로 저장검색,삽입,삭제에서
3.스택, 큐, 덱
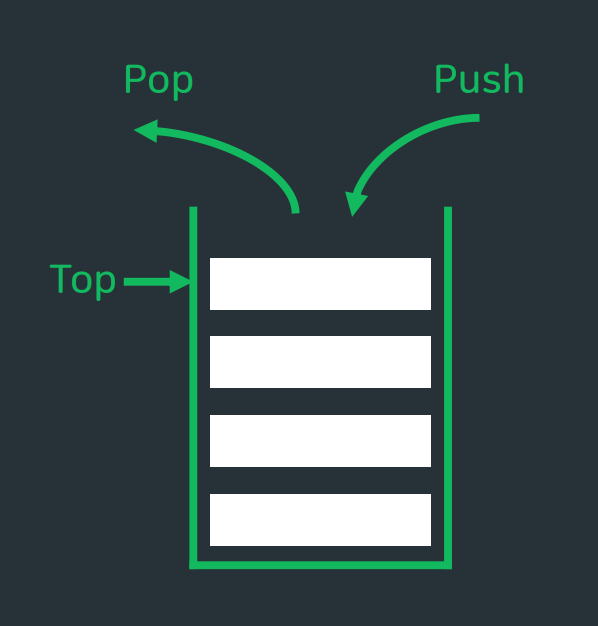
Last in, First out자료의 맨 끝 위치에서만 모든 연산이 이루어짐따라서 모든 연산에 대한 시간 복잡도는 O(1). 연산이 이루어지는 위치를 top이라고 하며 삽입은 push, 삭제는 pop🚩이때 주의할 점은, pop하기 전에 empty체크하기, push하
4.우선순위 큐
우선순위큐
5.정수론 및 조합론
방법 1. 소인수분해 이용; 구현이 까다로움방법 2. 두 수 중 작은 수 기준으로 돌리면서 가장 큰 공통 약수 구하기; 시간복잡도 O(N)✨방법 3. 유클리드 호제법✨; 시간복잡도 O(logN)A와 B의 최대공약수 = A%B와 B의 최대공약수 1\. 증명gcd(a, b
6.브루트포스

\- 단순히 가능한 모든 경우를 찾는 기법테스트 케이스의 크기에 따라 소요 시간이 엄청나게 커질 수 있음하지만, 떠올리기 가장 쉬운 방법이므로 문제를 풀때 가장먼저 고려해야하는 방법이기도함.입력범위와 시간복잡도를 잘 고려하여 선택하는것이 중요.▶ 총 연산수가 약 1억회
7.백트래킹
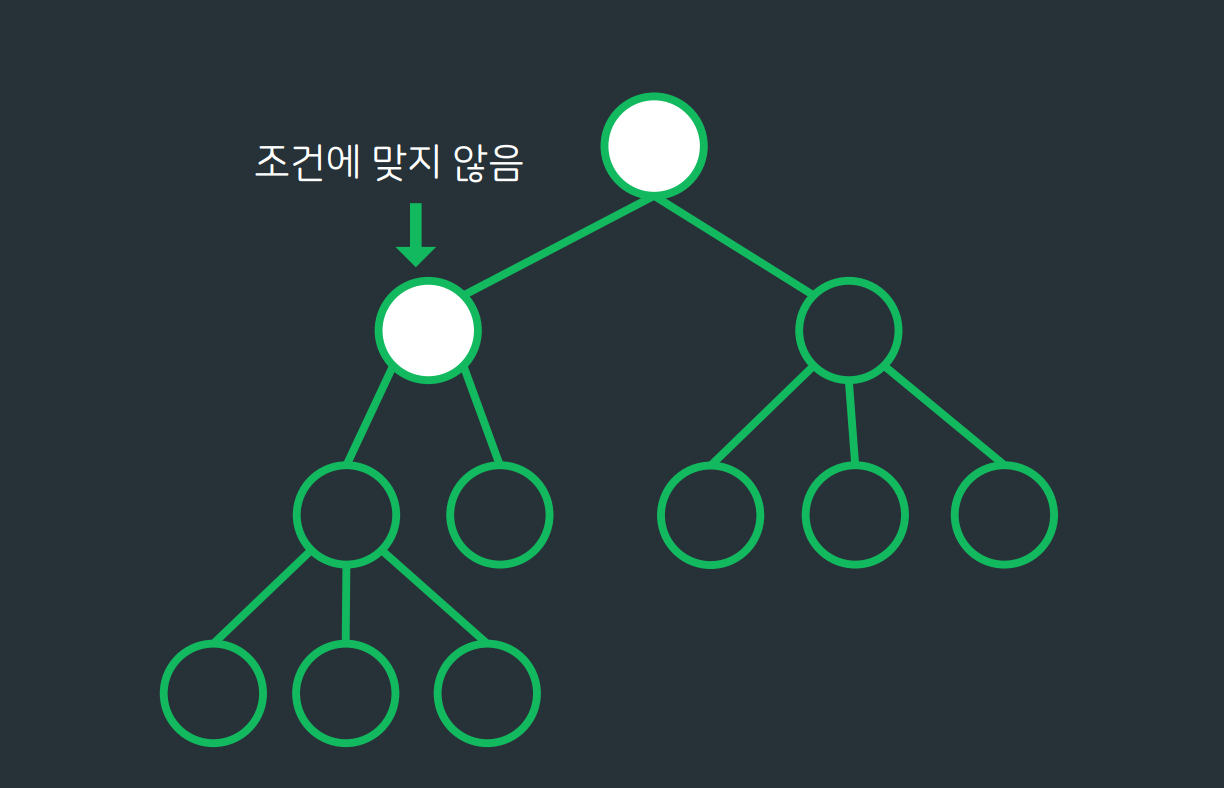
완전탐색처럼 모든 경우를 탐색하나, 트리 구조를 기반으로 중간 과정에서 조건에 맞지 않는 케이스를 가지치기하여 탐색시간을 줄이는 기법모든 경우의 수를 탐색하지 않기 때문에 완전 탐색보다 시간적으로 효율적임.탐색 중 조건에 맞지 않는 경우 이전 과정으로 돌아가야하기때문
8.동적계획법

특정 범위까지의 값을 구하기 위해 이전 범위의 값을 활용하여 효율적으로 값을 얻는 기법이전 범위의 값을 저장함으로써 시간적,공간적 효율을 얻음
9.그리디 알고리즘

현재 상황의 가장 최선의 선택으로 결국 전체 문제의 최선의 답을 만드는 기법시간적으로 매우 효율적모든 순간 답이 되는 방법은 아님.주로 O(N)의 시간복잡도를 가지므로 입력범위가 큰 경우가 많다. (1,000,000이상인 경우)순간의 최적해가 전체 문제의 최적해가 되어
10.분할정복

분할정복
11.투포인터

이런 문제가 있다고 해봅시다!더할때마다 시간 복잡도 O(n)만약 배열의 크기가 10,000 이라면 구하고자하는 구간이 1,000,000개만 돼도 총 연산횟수 100억!: Ai ~ Aj까지의 합 = sumj -sumi-1그렇다면 j-i가 고정된 상태, 즉 구해야하는 구간
12.DFS,BFS
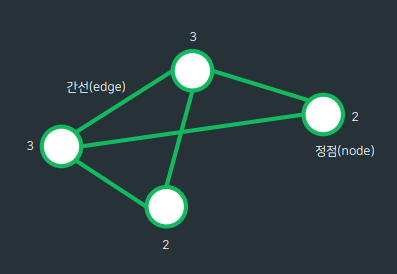
정점과 그 정점을 연결하는 간선으로 이루어진 자료구조간선의 방향은 단방향(방향 그래프)나 양방향(무방향 그래프)로 나뉨간선에 가중치가 있을 수 있음degree(차수) : 무방향 그래프에서 정점에 연결된 간선의 수무방향 그래프의 총 차수(degree)의 합 -= 간선의
13.동적계획법 역추적
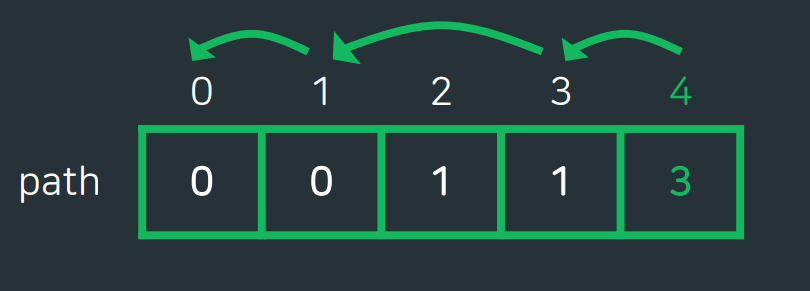
현재 해
14.트리
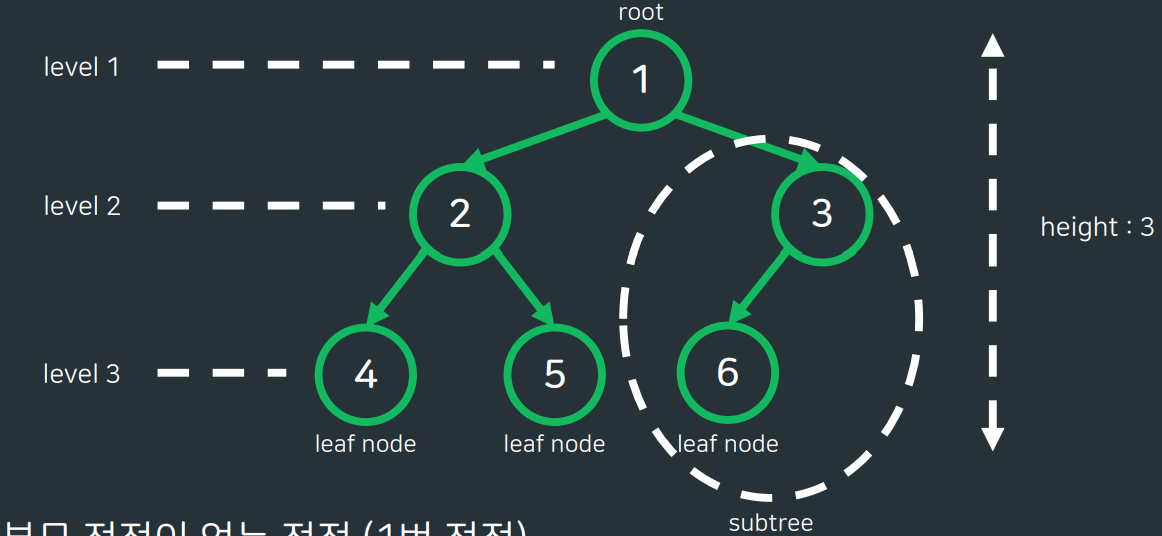
비선형 자료구조그래프의 부분 집합으로 사이클이 없고, V개의 정점에 대해 V-1개의 간선이 있음.부모-자식의 계층 구조트리 탐색의 시간 복잡도는 O(h) (h=트리의 높이)그래프와 마찬가지로 DFS,BFS를 이용하여 탐색Tree Root : 부모 정점이 없는 최 상위
15.최소신장트리

하나의 그래프로 만들 수 있는 트리들을 신장트리 (Spanning Tree)라고 부름신장 트리 중 간선의 가중치 합이 가장 작은 트리가 최소 신장 트리MST를 구하는 알고리즘으로는 크루스칼, 프림이 있음유니온 파인드 알고리즘을 이용해 MST를 구하는 알고리즘유니온 파인
16.위상정렬

Indegree(진입차수) : 방향 그래프에서 해당 정점으로 들어오는 간선의 수Outdegree(진출 차수) : 방향 그래프에서 해당 정점에서 나가는 간선의 수그래프의 선후 관계를 지키며 모든 정점을 일렬로 나열하는 알고리즘순서가 정해져 있는 작업을 차례로 수행해야 할