쓰기 지연 저장소란?
- 한 트랜잭션안에서 이뤄지는 UPDATE나 SAVE의 쿼리를 쓰기지연 저장소에 가지고 있다가 트랜잭션이 커밋되는 순간 한번에 DB에 날리는 것을 말한다.
이로써 얻을 수 있는 장점은 DB커넥션 시간을 줄일 수 있고, 한 트랜잭션이 테이블에 접근하는 시간을 줄일 수 있다는 장점이 있다.
쓰기 지연 저장소의 장점
- 쓰기지연저장소가 없다면 쌓아둠 없이 매번 쿼리를 날려야할테니 디비에 연결 ~ 해제 하는 과정이 매번필요하고 매번 테이블에 접근해야하는데 이때 시간이 걸린다. 그래서 쓰기 지연 저장소를 활용하면 이 시간을 줄일 수 있게 된다
쓰기 지연 저장소가 작동하지 않는 경우
- IDENTITY옵션을 사용하여 식별자를 적용하는 경우
- IDENTITY는 디비에 저장이 되어야 부여가 된다. 그렇기 때문에 쿼리 밑에 출력을 해보면 쿼리가 먼저 나간 뒤에 출력문이 나가는 것을 확인할 수 있다.
- 업데이트 후에 필드로 검색
@Transactional
fun test() {
val productItem = productItemRepository.findById(1L).orElse(null)
productItem.amount = 1000
productItemRepository.save(productItem)
println("update query not working")
val productItem1 = productItemRepository.findByName("bananana")
}- 이 경우에는 쓰기지연 저장소가 작동하지 않는다
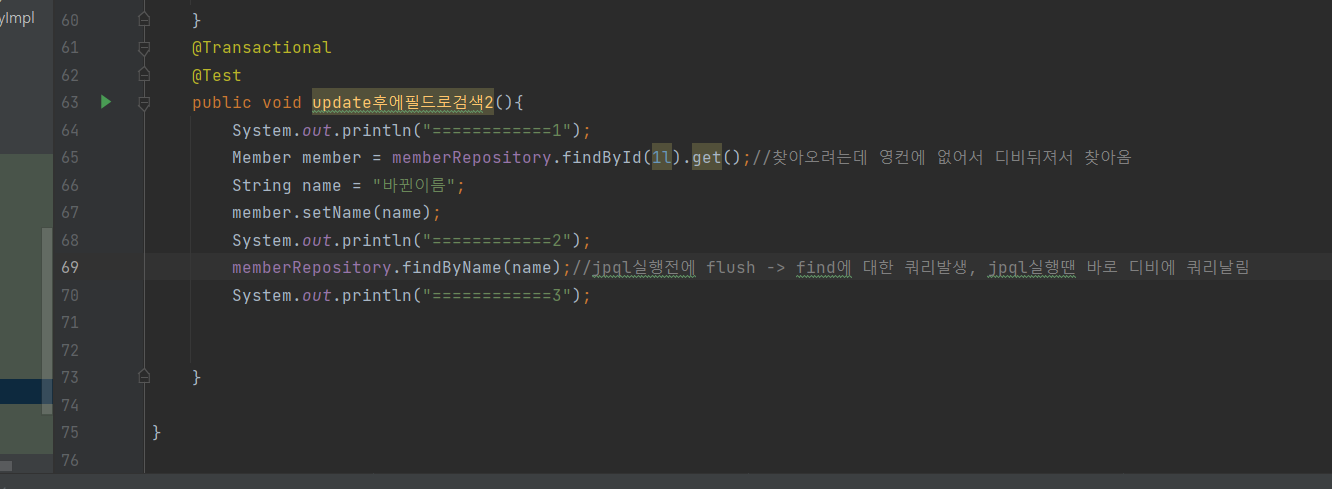
- 업데이트 후에 id로 검색
- 이 경우에는 쓰기 지연 저장소가 작동한다
- 이건 jpql이 아니니까..
필드로 검색하면 왜 쓰기 지연 저장소가 작동하지 않는걸까?
- JPQL 날릴때는 flush하고 날리는데 필드로 쿼리 날릴때 jpql을 쓰는게 아닐까 싶네요
-> jpql이란?
예제
https://velog.io/@cksdnr066/TIL-em.find-vs-JPQL-SELECT
- 이건근데 find랑 select의 차이라기보단
jpql과 jpql이 아닌것(em의 기본제공메서드)의 차이?인것같다
전자는 바로디비로 요청이 가고 후자는 영컨을 뒤져본다음에 디비로 요청이 가기때문이다. 또한 후자는 jpql이 아니라 바로 sql을 만들어서 보낸다
엔티티 수정
- JPA는 엔티티를 수정할 때는 단순히 엔티티를 조회해서 데이터만 변경하면 된다.
update() 라는 메소드는 없다.
변경 감지(dirty checking) 기능을 사용해서 데이터베이스에 자동으로 반영한다.
플러시 시점에 스냅샷과 엔티티를 비교해서 변경된 엔티티를 찾는다.
수정 순서
- 트랜잭션 커밋 -> 엔티티 매니저 내부에서 먼저 플러시가 호출된다.
(플러시: 영속성 컨텍스트의 변경 내용을 DB 에 반영) - 엔티티와 스냅샷을 비교해서 변경된 엔티티를 찾는다
- 변경된 엔티티가 있으면 수정 쿼리를 생성해서 쓰기 지연 SQL 저장소로 보낸다.
- 쓰기 지연 저장소의 SQL을 데이터베이스로 보낸다.
- 데이터베이스 트랜잭션을 커밋한다.
플러시를 실행하게 된다면..
- 변경 감지가 동작해서 영속성 컨텍스트에 있는 모든 엔티티를 스냅샷과 비교해서 수정된 엔티티를 찾는다.
- 수정된 엔티티는 수정 쿼리를 만들어 쓰기 지연 SQL 저장소에 등록한다.
- 쓰기 지연 SQL 저장소의 쿼리를 데이터베이스에 전송한다(등록, 수정, 삭제 쿼리)
영속성 컨텍스트를 플러시하는 3가지 방법
- em.flush()를 직접 호출
테스트나 다른 프레임워크와 JPA를 함께 사용할 때를 제외하고 거의 사용하지 않음. - 트랜잭션 커밋 시 플러시가 자동 호출
트랜잭션 커밋하기 전에 꼭 플러시를 호출하여 변경된 내용을 데이터베이스에 반영해야 한다.
JPA는 트랜잭션을 커밋할 때 플러시를 자동으로 호출한다. - JPQL 쿼리 실행 시 플러시가 자동 호출
예시 상황1

- 주솟값 비교인 isSameAs를 해도 값이 같게 나온다
- 그이유를 알아보자
- 조회해온다
- 조회해왔기 때문에 1차캐시에 프록시 객체가 저장된다
- set을 통해 필드를 변경한다
- 같은 객체이기 때문에 1차 캐시의 프록시 객체도 값이 변경된다
- 그다음에 조회해왔을땐 1차캐시에 객체가 들어있기 때문에 그 프록시 객체를 그대로 리턴한다.
-> findbyid는 프록시객체를 리턴하지 않는다. 내부적으로 em.find를쓰기때문에 프록시가 아닌 진짜클래스, 진짜객체를 리턴한다
여기서 왜 프록시 객체를 가져오는거지?
- em.find:진짜객체조회, em.reference:프록시객체조회
- repository.findById: em.find를 사용한다 진짜 클래스를 가져온다
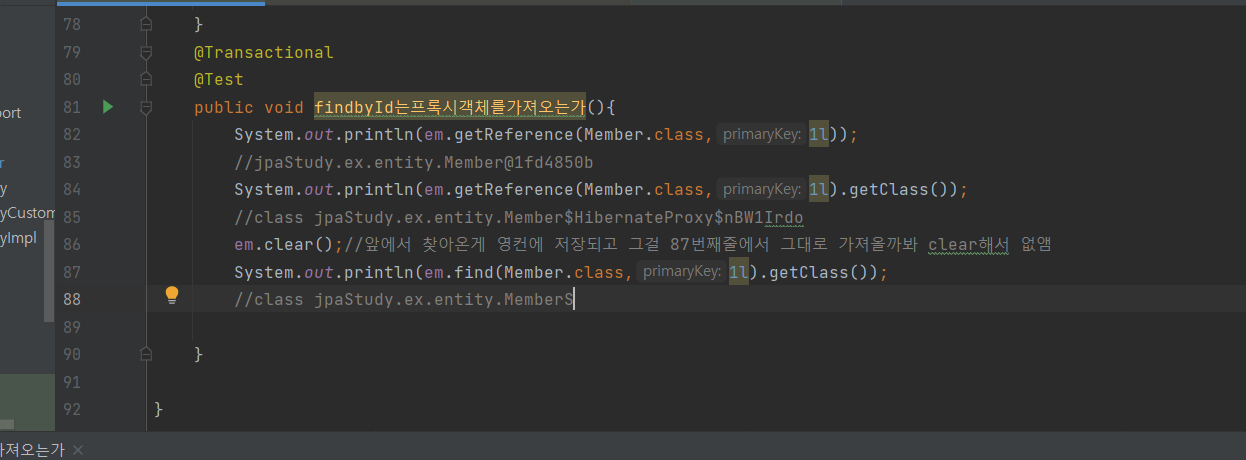
예시 상황2
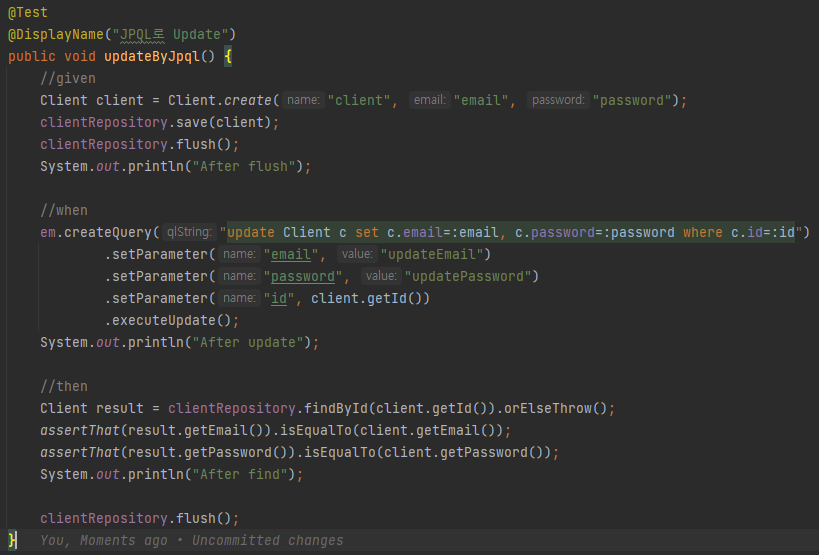
- 다음처럼 jpql로 update쿼리를 짜게 되면 자바 객체에 영향이 가지 않기 때문에 client랑 result의 값이 달라지게 된다
set으로 변경하는 것과 직접 쿼리를 날리는 것의 차이를 알아보자
- 예시상황1과 예시상황2를 보았다. set으로 변경하는 것과 직접쿼리를 날려서 변경하는 것에는 어떤 차이가 있을까?
- set으로 변경하면 자바 객체도 변경되지만 직접쿼리날리는경우는 그 자바객체는 변하지 않는다는 점정도..? 나머지는 잘 모르겠다!
1차캐시
- 엔티티 매니저로 조회하거나 변경하는 모든 엔티티는 1차 캐시에 저장된다.
하지만 동일한 트랜잭션 내에서만 1차 캐시가 존재하기 때문에 이미 1차 캐시에 저장되어 있는 경우는 흔치 않다.
질문) 과거 데이터
Q] Update가 발생하면 데이터가 갱신될텐데, 계속 캐시에 있는 것을 조회하면 과거의 데이터만 받는거 아닌가요?
A] 1차 캐시는 영속성 컨텍스트 내부에 있습니다. 영속성 컨텍스트 내부에 있는 엔터티의 변화가 즉시 1차 캐시에 저장되기 때문에, 캐시에서 갱신된 데이터를 받게 됩니다.
flush란
- 영속성 컨텍스트의 변경 내용을 DB 에 반영하는 것을 말한다
em.clear란
- 영속성 컨텍스트에 있는 데이터를 제거
출처
https://jobc.tistory.com/209
https://www.nowwatersblog.com/jpa/ch3/3-4
https://jaehoney.tistory.com/135

안녕하세요!