1. 데이터 파악하기
데이터 파악에는 기본적으로 다음의 여섯 가지 명령어를 사용한다.
| 함수 | 기능 |
|---|---|
| head() | 앞부분 출력 |
| tail() | 뒷부분 출력 |
| shape | 행, 열 개수 출력 |
| info() | 변수 속성 출력 |
| describe() | 요약 통계량 출력 |
예제를 위해 mpg(mile per gallon) 데이터를 사용한다. mpg는 미국 환경 보호국에서 공개한 데이터로, 1999~2008년 미국에 출시된 자동차 234종의 정보를 담고 있다.
import pandas as pd
mpg = pd.read_csv('./Doit_Python-main/Data/mpg.csv')head(), tail()을 통해 데이터의 형태를 확인한다. 기본 5행을 출력하며, 괄호 안에 숫자를 넣으면 입력한 숫자만큼의 행을 출력한다.
mpg.head()
mpg.tail()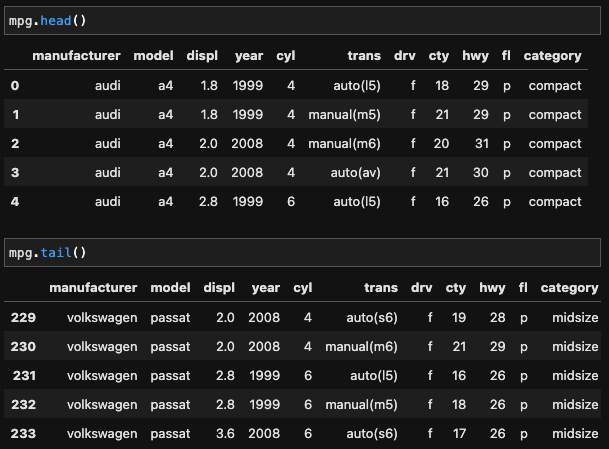
shape : 데이터 프래임의 행, 열 개수를 출력한다.
mpg.shape- shape는 함수가 아니라 데이터 프레임이 갖고 있는 속성인 어트리뷰트이므로 명령어 뒤에 괄호를 입력하지 않는다

info() 를 통해 변수 속성을 파악한다.
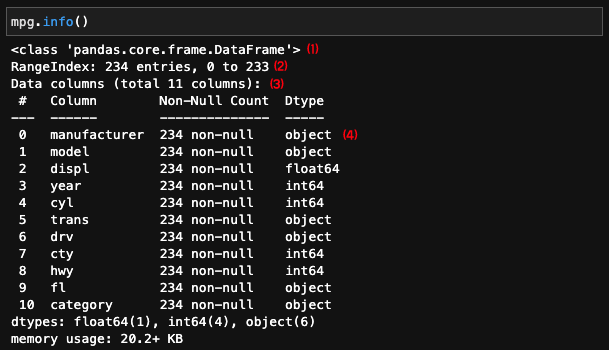
(1) pandas.core.frame.Dataframe을 보면 mpg가 pandas로 만든 데이터 프레임이라는 것을 알 수 있다.
(2) 234행으로 되어 있고, 행 번호가 0부터 233까지라는 것을 알 수 있다.
(3) pmg가 변수 11개로 구성되어 있다는 것을 알 수 있다.
(4) 데이터 프레임에 들어있는 변수들의 속성이 표시된다. 각 행에 변수 순서(#) , 이름(Column), 변수에 들어있는 값의 개수(non-null), 속성(Dtype)을 보여 준다. 예를 들어, 2행의 displ은 234개의 값이 있고 실수(float64)이다.
describe()를 통해 요약 통계량을 구한다.
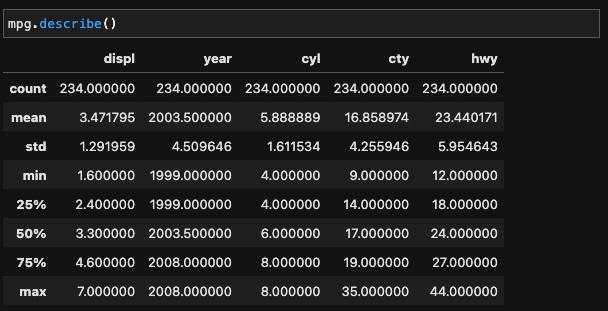
출력되는 통계량은 다음의 의미를 갖는다.
| 출력값 | 통계량 | 설명 |
|---|---|---|
| count | 빈도(frequency) | 값의 개수 |
| mean | 평균(mean) | 모든 값을 더해 값의 개수로 나눈 값 |
| std | 표준편차(standard deviation) | 변수의 값들이 평균에서 떨어진 정도를 나타낸 값 |
| min | 최소값(minimum) | 가장 작은 값 |
| 25% | 1사분위수(1st quantile) | 하위 25%(4분의 1)지점에 위치한 값 |
| 50% | 중앙값(median) | 하위 50%(중앙) 지점에 위치한 값 |
| 75% | 3사분위수(3rd quantile) | 하위 75%(4분의 3)지점에 위치한 값 |
| max | 최대값(maximum) | 가장 큰 값 |
2. 변수명 바꾸기
변수명을 바꾸기 전, 먼저 copy()를 사용해 데이터 프레임의 복사본을 작성한다.
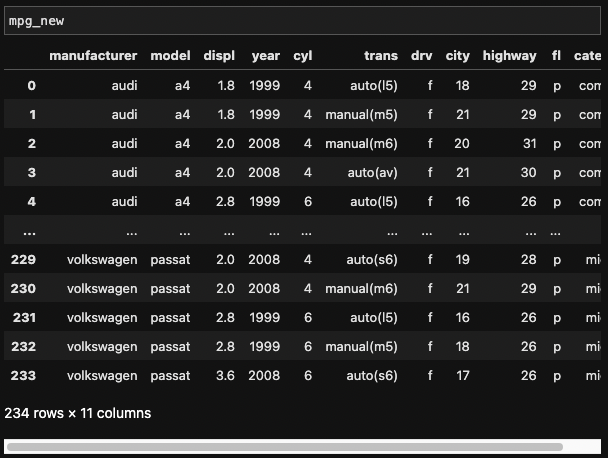
mpg_new = mpg.copy()rename()을 통해 변수명을 수정할 수 있다. columns 파라미터를 추가한 다음, {'기존 변수명' : '새 변수명'}을 입력하면 된다.
mpg_new = mpg_new.rename(columns = {'cty' : 'city'})
mpg_new = mpg_new.rename(columns = {'hwy' : 'highway'})변수명 cty가 city로, hwy가 highway로 변경된 것을 확인할 수 있다.