1. 데이터 프레임이란?
데이터 프레임 : 데이터를 다룰 때 가장 많이 사용하는 데이터 형태로, 행과 열로 구성된 사각형 모양의 표처럼 생겼다.
열 : 속성을 나타냄, 세로로 나열
행 : 각 사람(도시, 거래 내역 등)의 정보를 나타냄. 가로로 나열
| 1열 | 2열 | 3열 | 4열 | |
|---|---|---|---|---|
| 1행 | 성별 | 연령 | 학점 | 연봉 |
| 2행 | 남자 | 26 | 3.8 | 2,700만원 |
| 3행 | 여자 | 42 | 4.2 | 4,000만원 |
| 4행 | 남자 | 35 | 2.6 | 3,500만원 |
- 행이 많아지는 것보다 열이 많아지는 게 더 중요 - 열이 많아지면 변수를 조합할 수 있는 경우의 수가 늘어나기 때문
2. 데이터 프레임 만들기
2-1. 데이터 프레임 만들기
pandas 패키지의 DataFrame() 을 이용한다.
import pandas as pd
df = pd.DataFrame({'name' : ['윤이수', '김민지', '이유정', '김민수'],
'english' : [90, 80, 70, 60],
'math' : [50, 60, 70, 80]})
df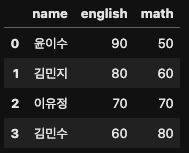
2-2. 데이터 프레임으로 분석하기
특정 변수의 값 추출하기
df['english'] #영어점수만 출력하기0 90
1 80
2 70
3 60
Name: english, dtype: int64
변수의 값으로 합계 구하기
sum(df['english']) #영어점수 합계 출력하기300
변수의 값으로 평균 구하기
sum(df['english']) / len(df)#영어점수 평균75.0
3. 외부 데이터 사용하기
실습을 위해 Do it! 쉽게 배우는 파이썬 데이터 분석의 실습 데이터를 사용한다.
3-1. 엑셀 불러오기
pandas의 read_excel()을 이용한다. 이때, 현재 사용중인 워킹 디렉터리에 불러올 파일이 있어야 한다.
df_exam = pd.read_excel('excel_exam.xlsx') #엑셀 파일을 불러와 df_exam에 할당
df_exam #출력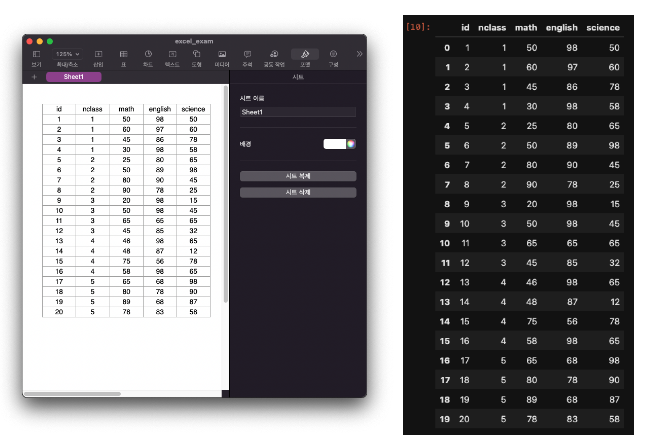
만약 첫 번째 행이 변수명이 아닐 경우에는 read_excel()에 header = None을 입력한다.
df_exam_novar = pd.read_excel('excel_exam_novar.xlsx', header = None)
df_exam_novar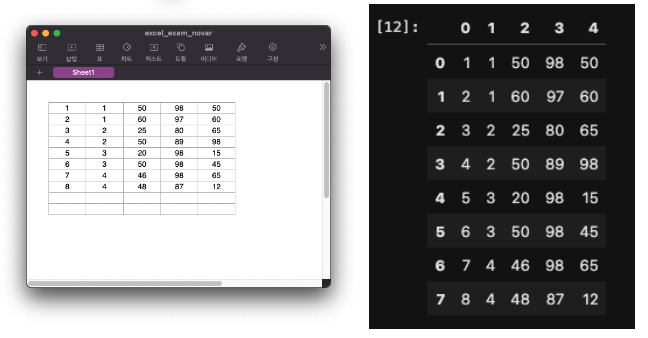
엑셀 파일에 시트가 여러 개 있을 경우 : sheet_name 파라미터에 시트 이름 또는 숫자를 입력한다.
이때, 시트 숫자는 0부터 센다.
# Sheet2의 데이터 불러오기
df_exam = pd.read_excel('excel_exam.xlsx', sheet_name = 'Sheet2')
# 세 번째 시트의 데이터 불러오기
df_exam = pd.read_excel('excel_exam.xlsx', sheet_name = 2)3-2. CSV파일 불러오기
CSV파일은 값이 쉼표로 구분된 형태의 범용 데이터이다.
pandas의 read_csv()를 이용해 불러올 수 있다.
df_csv_exam = pd.read_csv('exam.csv')
df_csv_exam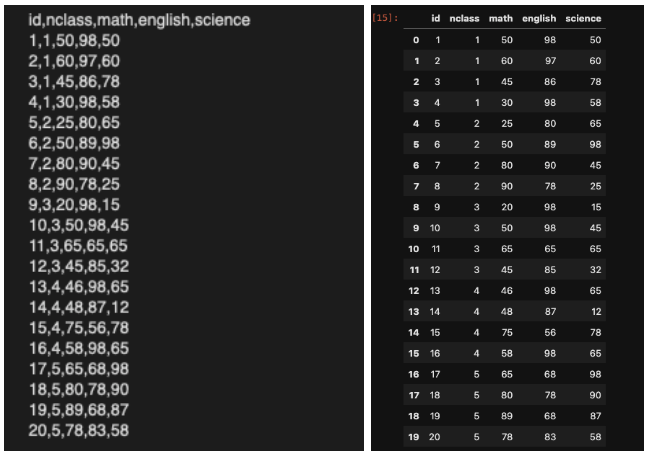
3-3. 데이터 프레임을 csv 파일로 저장하기
데이터 프레임을 csv 파일로 저장하면 파이썬 외에도 R, SPSS 등 데이터를 다루는 대다수의 프로그램에서 불러올 수 있다.
to_csv()를 사용한다.
df.to_csv("output_df.csv")인덱스 번호를 제외하고 저장하려면 index = False 속성을 사용하면 된다.
df.to_csv("output_df.csv", index = False)