MOE 모델이란? 쉽게 이해하기
최근 Deepseek-R1 모델이 MOE(Mixture of Experts) 아키텍처를 사용한 것으로 알려지면서, MOE 모델이 무엇인지 쉽게 정리해보겠습니다.
MOE란?
MOE(Mixture of Experts)는 하나의 거대한 모델이 모든 작업을 처리하는 방식이 아니라, 여러 개의 전문가 모델(Expert)이 각자 특정 역할을 맡아 동작하는 방식입니다.
쉽게 말하면, 학교의 선생님들을 떠올리면 됩니다:
- 국어 선생님, 수학 선생님, 과학 선생님이 각자의 전문 분야를 가르치는 것처럼,
- MOE에서는 여러 전문가 모델이 특정 유형의 데이터를 처리하는 데 최적화되어 있습니다.
이렇게 하면 전체 모델이 모든 입력을 다 처리할 필요 없이, 가장 적절한 전문가 모델만 선택해서 계산을 수행하므로 연산 속도가 빠르고 자원 효율성이 좋아집니다.
MOE의 역사
MOE 개념은 2017년 Google Brain 연구진(Noam Shazeer, Quoc Le, Geoffrey Hinton, Jeff Dean 등)이 발표한 논문 "Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer"에서 처음 NLP 영역에 적용되었습니다.
MOE의 동작 방식
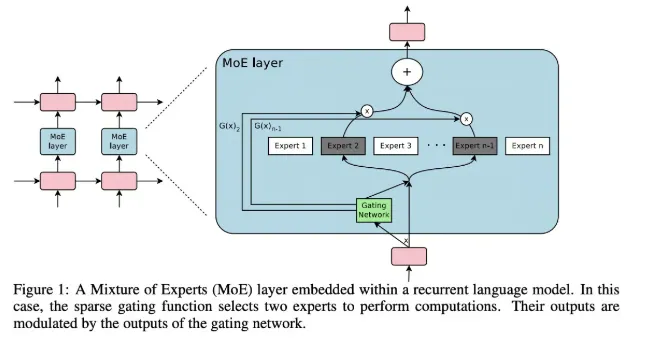
- 입력 토큰화 → 벡터 변환
- 입력된 텍스트를 벡터로 변환합니다.
- 게이팅 메커니즘(Gating Mechanism)
- 각 토큰에 대해 가장 적합한 전문가 모델을 선택합니다.
- 전문가 모델 처리
- 선택된 전문가 모델이 입력 벡터를 처리하여 출력 벡터를 생성합니다.
- 출력 결합(Merging Outputs)
- 여러 전문가 모델의 출력을 결합해 최종 결과물을 생성합니다.
이 과정을 통해 모델은 빠르고 정확한 응답을 생성할 수 있습니다.
MOE의 장점
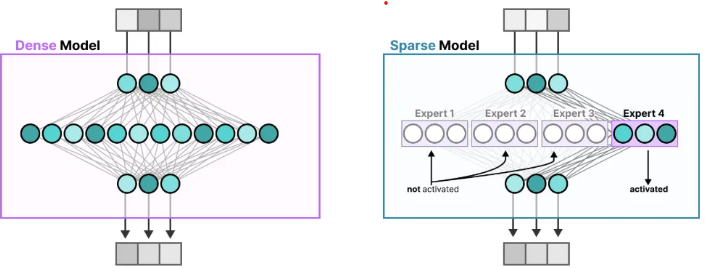
연산 속도 향상
- 모든 전문가 모델이 동시에 계산하지 않고, 필요한 전문가만 활성화되므로 속도가 빨라집니다.
- 즉, 불필요한 연산을 줄이고 자원을 효율적으로 사용할 수 있습니다.
불필요한 정보 배제
- 학습 과정에서 덜 중요한 전문가의 영향력을 최소화할 수 있습니다.
- 예를 들어, 어려운 문제를 풀 때 모든 전문가를 참고하는 것이 아니라 해당 문제를 잘 푸는 전문가들만 선택해서 정답을 낸다고 보면 됩니다.
즉, 헛소리하는 전문가들의 의견을 배제하고, 중요한 전문가들의 의견만 반영할 수 있는 것이 MOE의 핵심 장점입니다.
마무리
MOE 모델은 거대한 언어 모델이 더 빠르고 효율적으로 작동하도록 돕는 강력한 방법이다.
Deepseek-R1과 같은 최신 모델들이 MOE를 채택하는 이유도 바로 이런 효율성 덕분입니다. 앞으로 더 많은 AI 모델들이 MOE 방식을 활용할 것으로 예상된다.
참고

기록 == 성장