
Distill이란?
HuggingFace의 DeepSeek-R1 모델명을 보면 R1-Distill-Qwen과 같은 접미어가 붙어 있는 것을 볼 수 있다.
- R1: 버전명
- Qwen, Llama: 기반 모델
- Distill: 무엇을 의미하는가?
Distill은 영어로 "증류하다"라는 뜻이며, 딥러닝에서 Knowledge Distillation(지식 증류)이라는 개념으로 사용된다. 즉, 큰 모델(Teacher Network)에서 작은 모델(Student Network)로 지식을 전이하는 과정을 의미한다.
Knowledge Distillation의 개념
Knowledge Distillation은 NIPS 2014 workshop에서 발표된 논문 “Distilling the Knowledge in a Neural Network”에서 처음 등장했다.
오늘날 AI 모델들은 OpenAI의 ChatGPT, Google Bard와 같은 대형 모델들이 있다. 하지만 개인이 이러한 거대한 모델을 학습하고 배포하는 것은 현실적으로 어렵다. 따라서 작은 규모의 프로젝트에서도 효율적인 AI 모델을 사용할 수 있도록 Knowledge Distillation 기법이 활용된다.
🔹 모델 크기와 성능 비교 예시
만약 AI 모델을 선택해야 하는 상황에서 다음과 같은 옵션이 있다면?
- 복잡한 대형 모델 T: 예측 정확도 99% / 예측 시간 3시간
- 단순한 소형 모델 S: 예측 정확도 85% / 예측 시간 1분
이 경우, 소형 모델 S는 성능은 조금 낮지만 속도가 빠르고 실용적이다. 하지만 Knowledge Distillation을 사용하면 대형 모델 T의 성능을 소형 모델 S에 일부 전이하여 더 빠르면서도 성능이 높은 모델을 만들 수 있다.
Knowledge Distillation의 구조
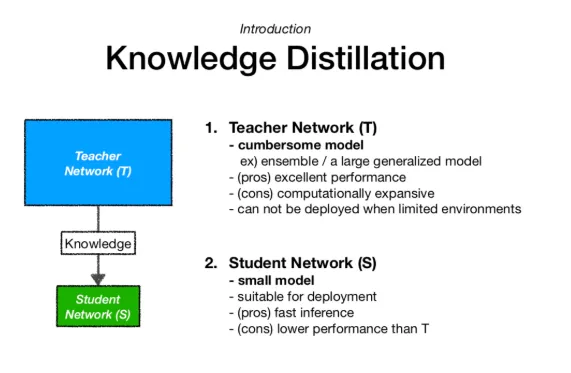
선생님 모델 (Teacher Network)
- 사전 학습된 대형 모델로 높은 정확도와 일반화를 제공한다.
- 대규모 데이터셋으로 학습된 딥러닝 모델이다.
- Knowledge Distillation을 통해 학생 모델에 성능을 전이한다.
학생 모델 (Student Network)
- 교사 모델보다 더 작고 가벼운 모델이다.
- 교사 모델과 유사한 구조를 가지지만 파라미터 수가 적고 연산량이 낮다.
- 목표는 교사 모델의 성능을 유지하면서도 추론 속도와 메모리 효율성을 높이는 것이다.
Knowledge Distillation의 장점
- 연산 효율성: 대형 모델의 계산량을 줄여 작은 모델에서도 높은 성능을 유지할 수 있다.
- 빠른 추론 속도: 실시간 애플리케이션에서도 사용 가능하다.
- 모바일 및 Edge AI 적용 가능: 스마트폰, IoT 기기에서도 활용 가능하다.
결론
Knowledge Distillation은 대형 모델의 성능을 유지하면서도 소형 모델의 속도와 효율성을 높이는 기법이다. 이러한 방법을 통해 최신 AI 모델들은 성능과 효율성의 균형을 맞추며 발전하고 있다.
참고 자료
