바로 구현으로 넘어가기 전에 벡터DB로 쿼리를 날리는 유즈케이스를 통한 설명이 있어야 포스트 마지막에 RetrievalQA에 대해 이해할 수 있을 것 같아 내용을 추가 했다
-
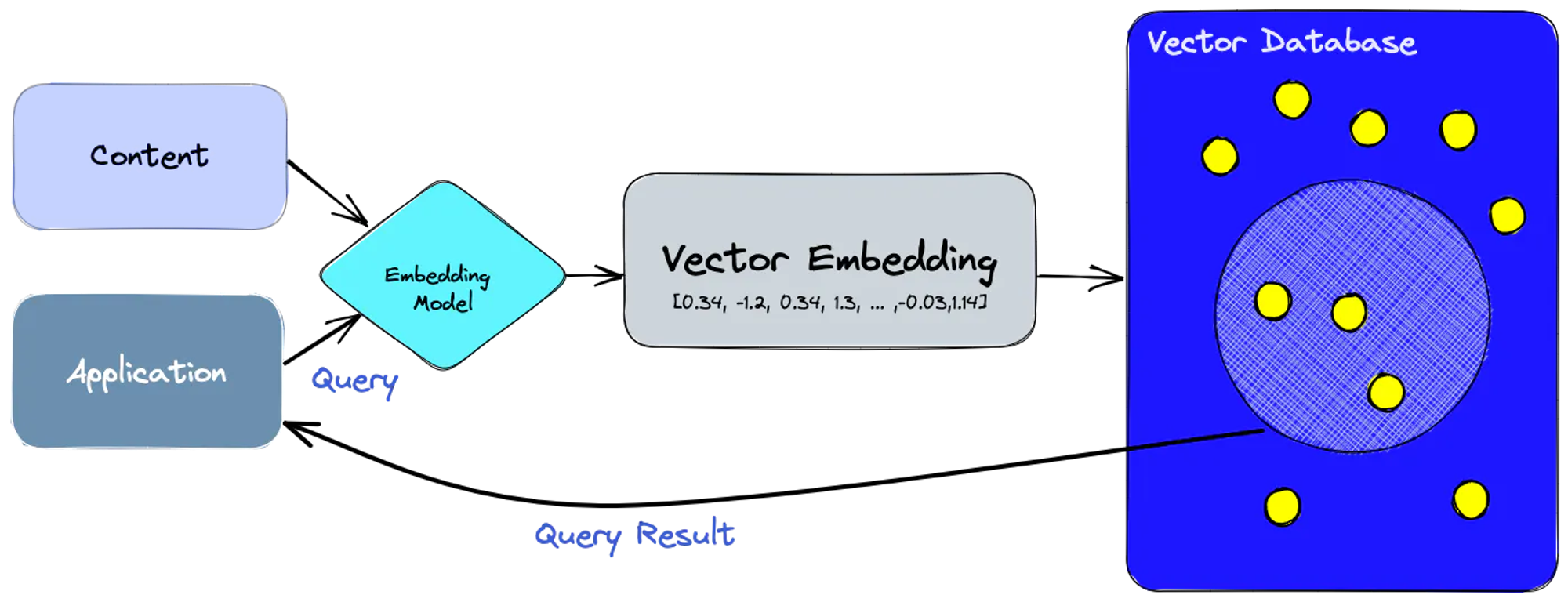
먼저 임베딩 모델을 사용하여 인덱싱하려는 콘텐츠에 대한 벡터 임베딩을 만든다
-
벡터 임베딩에 참조한 source와 함께 벡터 데이터 베이스에 삽입
- 이때 차원값 (ex 3차원 [0.04,0.9,0.86])과 함께 저장하고 이는 쿼리 수행시 유사성 측정 사용됨
-
쿼리문을 임베딩하여 유사한 벡터 임베딩에 대한 데이터베이스를 쿼리
(ex Top_k : 2 일 경우 아래 사진)
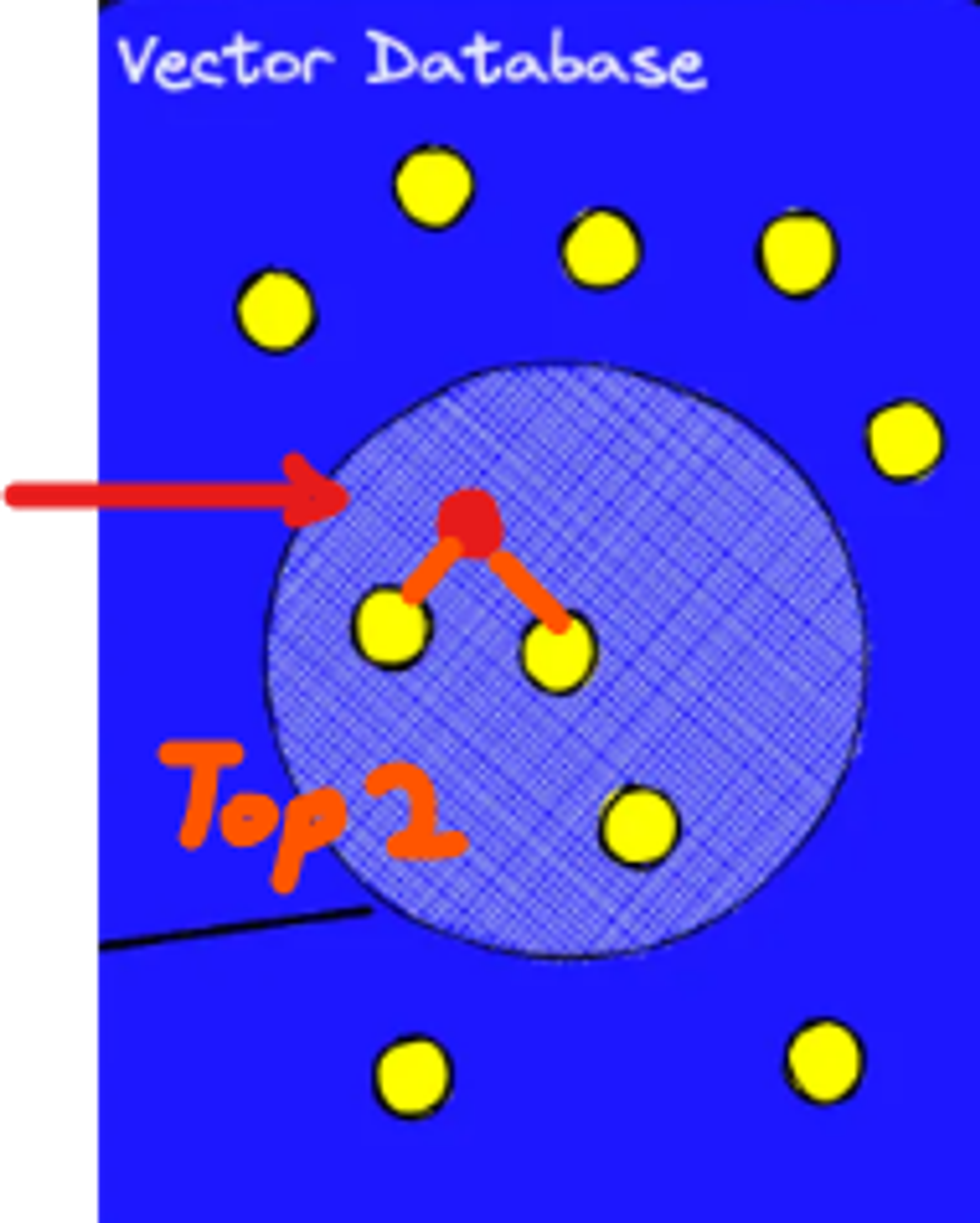
- LLM(GPT)는 이제 이 여러 조각의 청크의 knowledge를 참고하여 질문에 대한 답변을 생성
자 그럼 이제 GPT를 호출 할 때 데이터베이스를 참고(Retrieve) 하여 답변을 구현해본다
llm은 OpenAI의 GPT를 사용하고 대화 비용마저도 없애기 위해 자체 LLM모델을 개발한다면 이부분이 변경될 수도 있다
llm = ChatOpenAI(
openai_api_key=os.environ.get("OPENAI_API_KEY"),
# model_name="gpt-3.5-turbo",
model_name="gpt-4o-mini",
temperature=0.0 # (1)
)(1) 언어 생성 모델에서 생성된 텍스트의 다양성(degree of diversity)을 조절하는 하이퍼파라미터가 높으면 다양한 대답을(예상치 못한 답변 가능성O), 낮으면 가능한 선택지 중에서 가장 높은 것을 선택(예상 가능하게)
knowledge는 LLM이 참고할(Retrieve) 문서로 pineconeVectorStore를 참고한다
여기 또한 임베딩이 필요한데 이는 쿼리 텍스트(프롬포트 질의)를 벡터화하여 기존의 벡터 데이터와의 유사성을 계산하고 검색하기 위해 사용된다
knowledge = PineconeVectorStore.from_existing_index(
index_name=index_name,
namespace=namespace,
embedding=OpenAIEmbeddings(openai_api_key=os.environ["OPENAI_API_KEY"])
)최종적으로 LLM 모델과 기반 문서를 파라미터로 RetrievalQA를 생성한다
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # (1)
retriever=knowledge.as_retriever(),
)
result = qa.invoke(question1)
answer = result.get("result") # (1)(1) 주요한 체인 유형은 다음과 같다
- stuff: 검색된 문서들을 모두 하나로 묶어 단일 입력으로 처리합니다. 이 체인은 간단하고 효율적이며, 검색된 문서가 많지 않은 경우에 적합함
- map_reduce: 검색된 문서들을 개별적으로 처리한 후, 개별 처리 결과를 종합하여 최종 답변을 생성합니다. 많은 문서가 검색될 때 유용하며, 각 문서를 별도로 처리하여 더 정확한 답변을 생성할 수 있다.
- refine: 초기 답변을 생성한 후, 추가적인 문서를 사용하여 답변을 점진적으로 개선한다. 처음 생성된 답변에 추가 정보를 더해 최종 답변을 도출하는 방식
- map_rerank: 검색된 문서들을 개별적으로 처리한 후, 각 문서의 중요도에 따라 순위를 매기고 최종 답변을 생성합니다. 검색된 문서의 품질이 다양할 때 유용함
Referece
What is a Vector Database & How Does it Work? Use Cases + Examples
[LangChain] Chroma Vector DB를 사용해서 RAG (Retireval-Augmented Generation) 구현
랭체인(LangChain) 입문부터 응용까지
