챗봇 개발기
1.커스텀 GPT 만들기 #1 FineTuning
RAG방식을 선택하기 까지의 기록처음엔 데이터를 크롤링해서 학습시키라는 지시가 있었음GPT를 학습시키는 방법을 공부하다 보니 GPT FineTuning 이란 개념이 있음FneTuning :ChatGPT Fine-tuning은 특정 작업이나 도메인에 특화된 추가 학습 데
2.커스텀 GPT 만들기 #2 RAG 개요
파인튜닝을 시도해보니 Raw데이터 정제에 너무 많은 리소스가 들어가고 있으며그마저도 잘 되지 않는 것이 사실이였다.Redis나 Java 정보와 같이 내가 학습시키려는 데이터와 공통적으로 가지고 있는 데이터에 비해 학습 데이터가 너무 적기 때문에 AI모델의 생성에 영향을
3.커스텀 GPT 만들기 #3 Vector Store

LangChain은 초거대언어모델(LLM)을 쉽게 활용할 수 있도록 돕는 프레임워크다. 챗GPT, Meta의 LLaMA 등 다양한 LLM에 적용할 수 있으며, 대표적으로 로컬 DB로는 faiss나 chromadb가 클라우드 네이티브로는 pinecone 같은 벡터 데이
4.커스텀 GPT 만들기 #4 벡터DB 만들기

데이터는 과거 줄기차게 만들었으니 JSON 데이터로 수집하던 로직만 Text 데이터로 형식만 바꾸고 진행 했다 이제 적재할 벡터 DB를 만들고 넣는것 까지 해본다 오픈소스이자 무료인 Pinecone채택 Pinecoe홈페이지에서 회원가입하고 API KEY를 발급받는다 Pinecone API에 접근하기 위해 라이브러리는 langchain, pinecon...
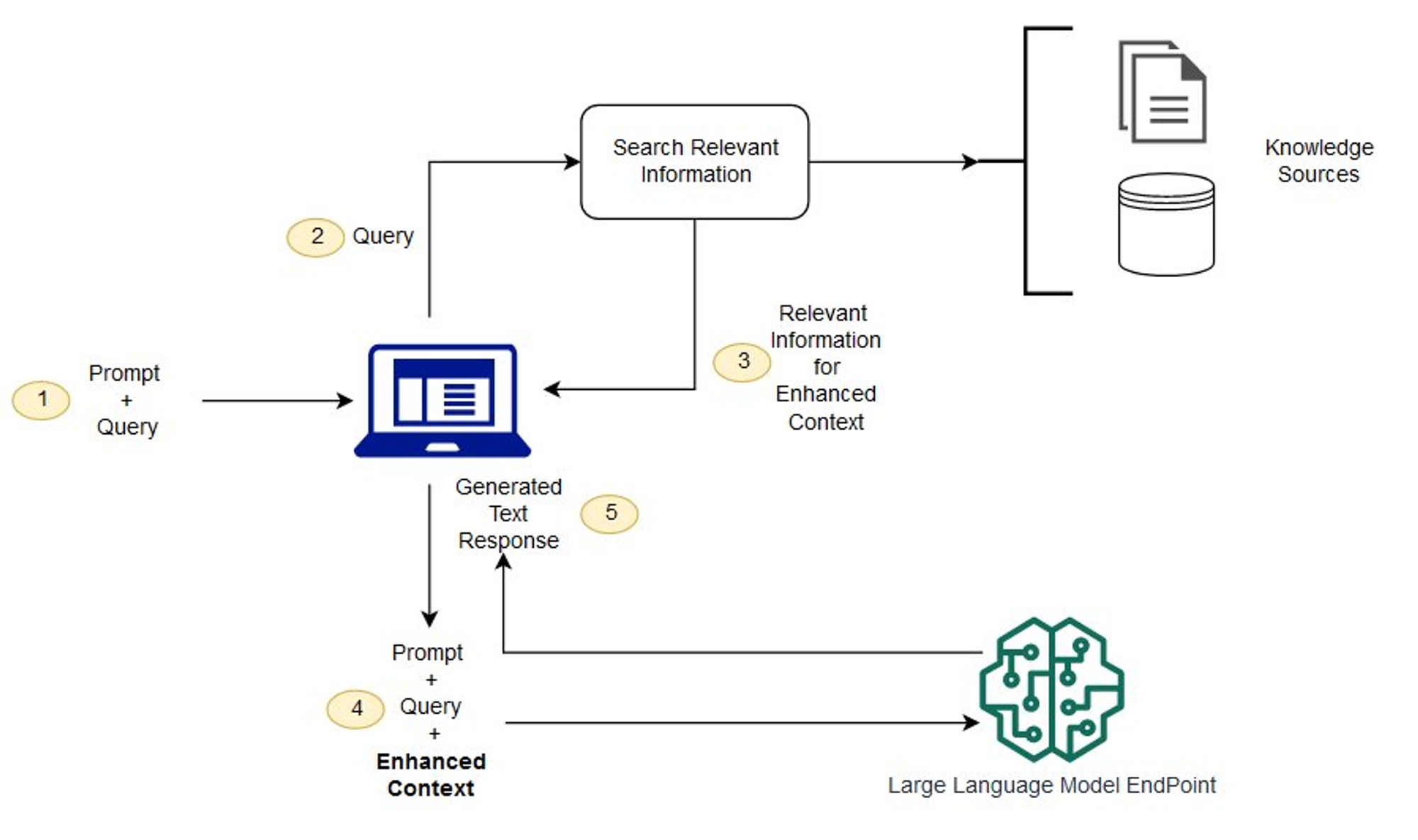
5.커스텀 GPT 만들기 #5 RAG GPT
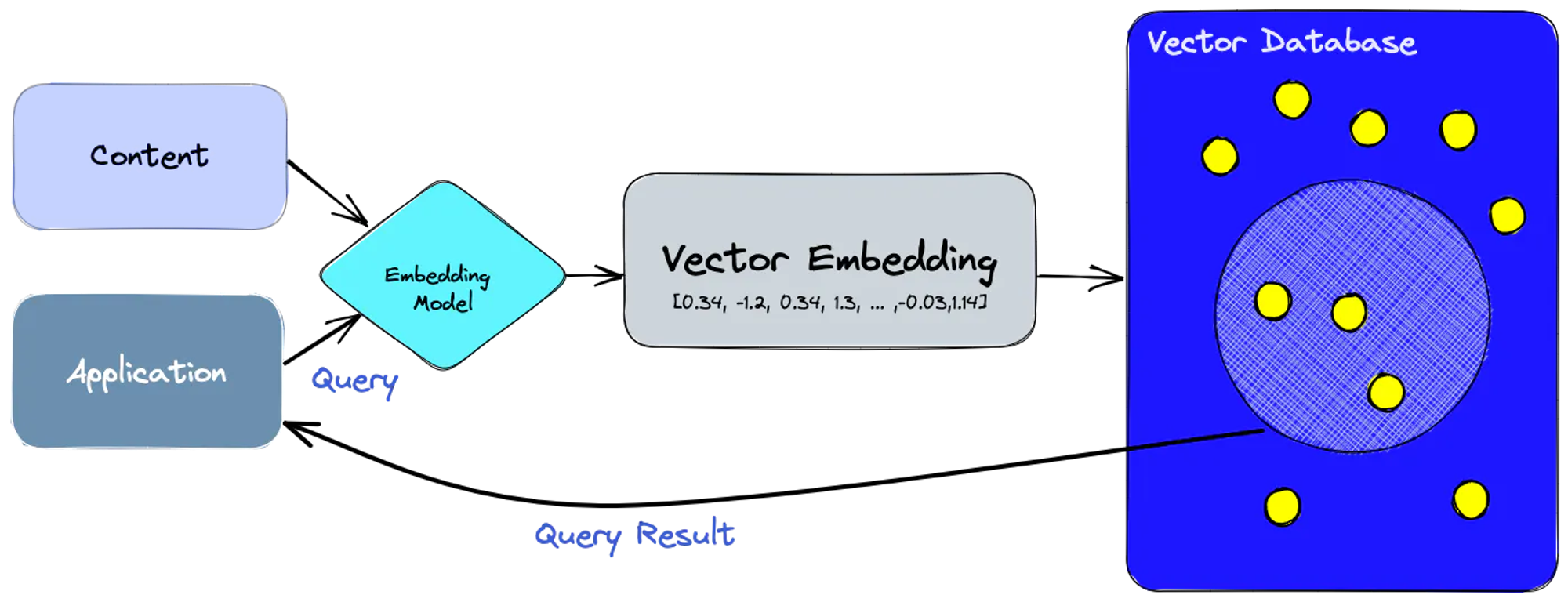
바로 구현으로 넘어가기 전에 벡터DB로 쿼리를 날리는 유즈케이스를 통한 설명이 있어야 포스트 마지막에 RetrievalQA에 대해 이해할 수 있을 것 같아 내용을 추가 했다먼저 임베딩 모델을 사용하여 인덱싱하려는 콘텐츠에 대한 벡터 임베딩을 만든다벡터 임베딩에 참조한
6.커스텀 GPT 만들기 #6 LangChain

Rag pipeline을 구성하기 위해 VectorStore를 생성하고 문서를 embedding하여 저장하는 방법까지 다뤄보았다 꽤나 오랜 시간이 지났지만 그동안 고도화 시킨 작업물은 정리해보고자 한다.Langchain 은 언어 모델을 활용해 다양한 애플리케이션을 개발
7.하이브리드 검색(Hybrid Search)이란?
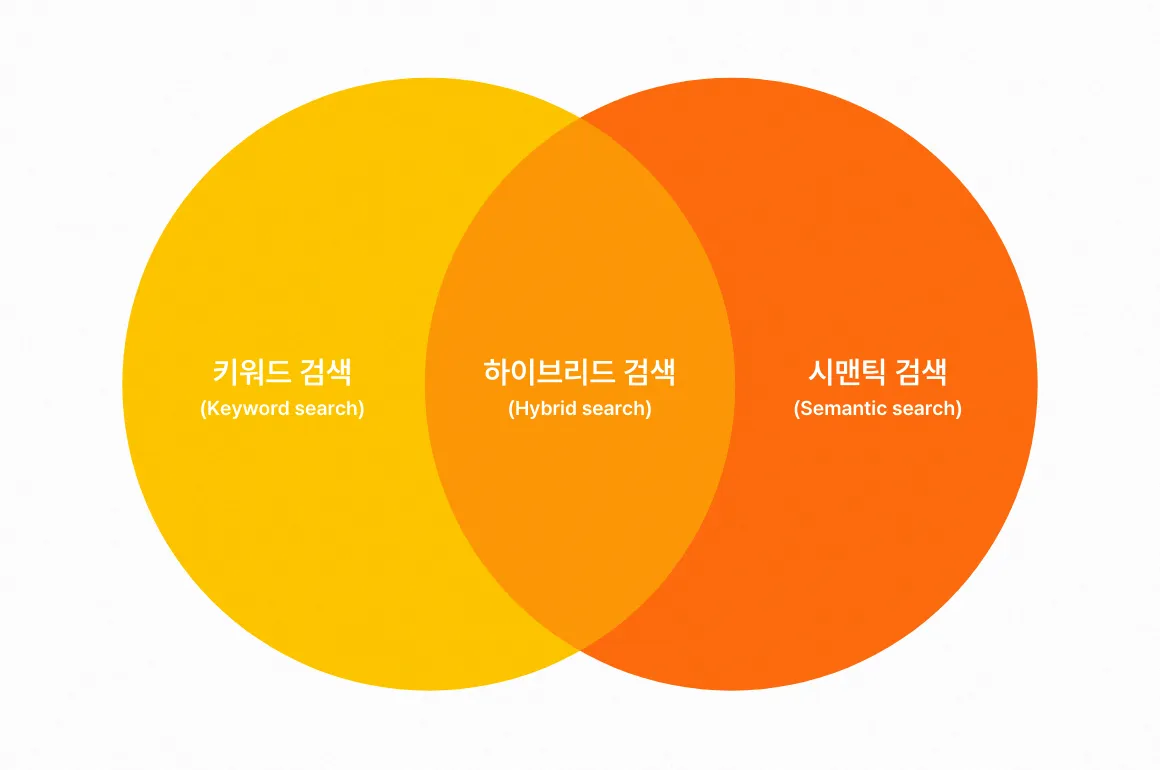
현재 LLM을 활용하는 대부분의 챗봇이 환각 현상을 줄이기 위해 RAG를 사용하고 있다.하지만 이러한 유사도 기반 검색조차 단어 임베딩 품질에 따라 답변의 정확도가 떨어져 다소 부족함이 있었다. 이를 해결하기 위해 유사도에 더해 키워드 기반 검색을 함께 활용하는 Hyb
8.개인정보 마스킹 처리 - RAG 파이프라인에 적용

RAG 파이프라인에 새롭게 추가된 개인정보 마스킹 처리에 대해 설명하려고 한다. Retrieve 된 데이터의 컨텍스트를 정규식을 사용해 마스킹 처리하는 로직을 구현함으로써, 개인정보 보호를 강화할 수 있었다.RAG(Retrieval-Augmented Generation