1️⃣ Backpropagation
- 역전파(Backpropagation)는 신경망에서 학습 알고리즘으로 사용되는 방법으로, 입력 데이터를 기반으로 모델의 출력과 실제 값 사이의 오차를 최소화하기 위해 가중치와 편향을 조정하는 과정을 의미한다.
-
학습은 크게 순전파와 역전파라는 두 단계로 이루어지는데, 순전파 단계에서는 입력 데이터가 모델을 통과하면서 예측값을 계산한다. 각 뉴런은 입력과 가중치를 곱한 후 활성화 함수를 통과하여 출력을 생성한다. 이러한 과정은 입력층에서부터 출력층까지 차례로 진행된다.
-
순전파가 완료되면 역전파 단계에서는 오차를 계산하고, 이 오차를 사용하여 가중치와 편향을 조정한다. 오차는 실제 값과 예측 값 사이의 차이로 계산된다. 역전파는 출력층에서부터 입력층까지 역방향으로 진행된다.
역전파의 핵심 아이디어는 오차를 거슬러 올라가며 각 층의 가중치에 대한 기여도를 계산하는 것이다. 이를 위해 미분 연쇄 법칙(Chain Rule)을 사용하여 각 노드의 입력에 대한 손실 함수의 미분 값을 계산한다. 이 미분 값은 가중치와 편향을 업데이트하는 데 사용된다. 역전파는 경사 하강법과 같은 최적화 알고리즘과 결합되어 신경망의 가중치를 조정하여 예측 성능을 향상시킨다.
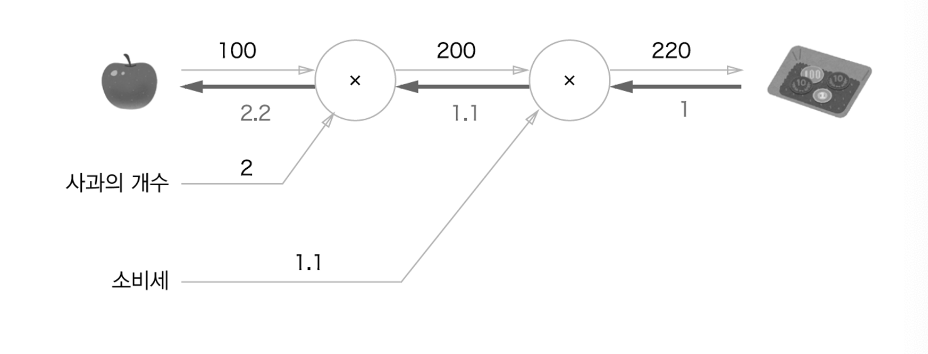
. 역전파는 국소적 미분을 전달하고 있고, 화살표 아래 값이 미분값이다. 현재 1 → 1.1 → 2.2 순으로 미분 값이 전달되었으므로 사과 가격에 대한 지불 금액의 미분값은 2.2라고 할 수 있다. 사과가 1원 오르면 최종 금액은 2.2배 증가하게 되는 것이다. 이러한 방식으로 여러 변수들에 대한 미분값을 효과적으로 구할 수 있는 것이 역전파이다.
2️⃣ Embedding
-
사진, 언어와 같은 인간의 표현 방식은 기계가 이해할 수 있는 수치 형태로 변환해주어야 한다.
-
이를 벡터화라고 말하며, 고차원의 벡터를 필요한 정보를 보존하면서 저차원으로 Mapping하는 것이 임베딩이다.
-
NLP에서는 One-hot 인코딩, Sparse Matrix로 표현된 각 단어를 저차원의 Dense Matrix로 임베딩하게 된다.
-
단순히 텍스트를 ‘구분’하는 것이 아니라 의미적으로 ‘정의’할 수 있도록, 유사한 의미의 단어는 임베딩 공간에서 가까이 놓이도록 수행된다.
NLP 분야에서의 대표적인 임베딩 방법으로는
CountVectorizer,TfidfVectorizer,Word2Vec이 있다.
⭐️ CountVectorizer
단순히 각 텍스트의 등장 횟수를 기준으로 특징을 추출하는 것이다. 가령 ‘하늘에 구름이 둥실둥실 떠있다’라는 문장을 벡터화할 때, 단어 사전을 등장 횟수에 따라 [’하늘에’, ‘구름이’, ‘둥실’, ‘떠있다’]를 [1, 1, 2, 1]로 정의하는 것이다. 하지만 이 방법은 큰 의미가 없는 조사가 높은 값을 가진다는 단점이 있다.
⭐️ TfidfVectorizer
- CountVectorizer의 단점을 해결하기 위해 나온 방법으로, TF-IDF를 특징으로 추출한다.
- TF는 Term Frequency로, 특정 단어가 하나의 문서 내에서 나오는 횟수를 뜻하고
- IDF는 Inverse Document Frequency로 특정 단어가 몇 개의 문서에서 등장하는지에 대한 지표의 반대이다.
- TF-IDF는 이 두 값을 곱한 값으로, 특정 문서에서만 자주 등장하는 단어에 높은 값을 부여하게 된다. - - 모든 문서에서 자주 등장하는 조사는 낮은 IDF 값을 가져 앞서 언급했던 CountVectorizer의 문제를 보완할 수 있다.
⭐️ Word2Vec
-
위 두 방법이 단어의 등장 빈도를 기준으로 한 임베딩 방법이었다면, Word2Vec은 학습을 통해 단어 간의 유사도를 특징으로 추출한다.
-
이 때 ‘비슷한 위치에 등장하는 단어는 비슷한 의미를 갖는다’는 분포 가설을 활용한다.
-
Word2Vec에는
CBOW와Skip-gram이 있다. -
CBOW는 어떤 단어를 문맥 안의 주변 단어들을 통해 예측하는 방법
-
Skip-gram은 어떤 단어를 가지고 주변 단어들을 예측하는 방식이다.
예를 들어 CBOW는 ‘나는 오늘 아침에 __를 먹었다’라는 문장의 빈칸에 들어갈 단어를 예측하는 방식으로 > 이뤄진다. 이를 위해 주변 단어를 One-hot 인코딩으로 나타내어 Input 벡터로 사용하고, 여기에 가중치 행렬을 곱해 n차원 벡터를 만든다. 이 n차원 벡터들을 평균낸 다음 다시 가중치 행렬을 곱해 One-hot 인코딩 차원과 같은 벡터로 만든다. 이 벡터를 정답 Label의 One-hot 인코딩 벡터와 비교하여 가중치를 업데이트한다. 이렇게 학습을 수행한 다음, 가중치 행렬의 각 행을 임베딩 벡터로 활용한다.
3️⃣ Framework
프레임워크(Framework)는 서비스 분야, 딥러닝, 웹 개발 등 맥락에 따라 사용하는 용도가 다양하다. 추상적인 의미로서, 작업을 효율적으로 할 수 있도록 짜놓은 틀로 이해할 수 있다. 개발 분야에 한정하여 말하자면, 보통 특정 작업을 도와줄 수 있는 라이브러리나 함수를 모아둔 집합체를 의미한다.
💡 딥러닝 프레임워크
딥러닝 프레임워크는 딥러닝 학습을 도와줄 수 있도록 데이터 로드, 데이터 학습, 평가 등을 도와줄 수 있는 모듈과 함수를 제공한다. 딥러닝 프레임워크가 지원하는 사항(데이터 로드, 모델 구축, 손실함수, 평가, 자동 미분)들은 대체로 비슷하지만 계산 / 구현하는 방식에 차이가 있다. 딥러닝 프레임워크는 보통 Python 언어를 기반으로 하며 대표적인 프레임워크로는 PyTorch, Tensorlfow, Keras가 있다. 각 프레임워크마다 장단점이 있지만, 최근 딥러닝 분야에서는 PyTorch의 사용 비중이 점차 높아지고 있는 추세다.
💡 웹 프레임워크
- 사용자가 웹 애플리케이션을 구축하고 싶고, Python 언어를 주로 사용한다면 Django와 같은 웹 프레임워크를 활용할 수 있다.
- 이때 프레임워크는 웹을 구성할 수 있는 일종의 규칙을 제공해준다.
- 사용자는 정해진 규칙에 따라 코드를 채워넣기만 하면 원하는 기능을 구현할 수 있는 것이다.
- 프레임워크가 기존에 정해놓은 규칙은 사용자가 바꿀 수가 없으며, 필요할 때마다 불러쓰는 라이브러리와는 차이가 있다.
- 실행의 주체는 Django이고, 규칙을 따라가기만 하면 보안을 비롯한 여러 기능들을 제공받을 수 있는 것이다.
💡 Flask
- 플라스크는 마이크로 웹 프레임워크이다.
- 이는 프레임워크를 간결하게 유지하고 확장할 수 있다는 의미이다. Django와 같은 프레임워크에 비해 초기 기능이 적지만, 확장 모듈을 활용해 필요한 기능을 개발해나갈 수 있다.
- 또한 규칙이 복잡한 대부분의 프레임워크와 달리 플라스크는 최소한의 규칙만 존재하기 때문에 비교적 다른 프레임워크에 비해 자유도가 높다.
- 간단한 프레임워크가 필요하다면, 플라스크를 사용하는 것이 좋다.
4️⃣ Inductive Bias
💡 Inductive Bias란?
- Inductive Bias를 직역하면 귀납적 편향이다.
- 네트워크의 편향(Bias)을 귀납적으로 추론한다는 뜻이다.
- 우리가 어떤 데이터나 네트워크를 다루는 과정에서 다루려는 데이터가 특정 값에 치우쳐 있거나 공통적 특성을 가질 때 이를 편향되었다고 한다.
- 대부분의 머신러닝, 딥러닝 네트워크는 특정한 상황을 가정하고 개발되며, 상황은 네트워크의 구조, Dataset의 특성 등이 있을 수 있다.
- 상황에 맞는 일반적인 가정을 네트워크 설계 과정에 반영한다면 더 높은 성능을 얻을 수 있을 것이며, 여기서 말하는 가정은 다루려는 상황에 대한 특성이 된다.
- 즉, 상황에 대한 가정을 추론하여 발생한 편향을 Inductive Bias라고 하며 이는 네트워크의 성능을 향상시키는데 큰 영향을 미친다.
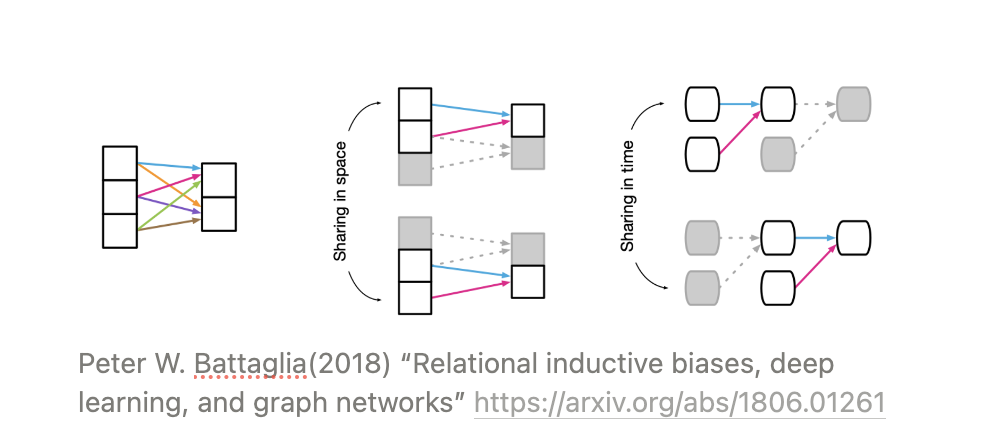
💡 Locality
Locality는 유사한 요소들이 가까운 위치에 있다는 특성이다. 위 그림에서 CNN의 계산 과정을 보면, 모든 입력이 모든 출력에 영향을 미치는 FCN과 다르게 가까운 위치의 픽셀들 사이의 가중합만이 출력에 영향을 미친다. 이는 가까운 위치에 유사한 요소들이 있다는 가정에서 비롯된 연산이다.
💡 Translation Invariance
Translation Invariance는 특정 패턴의 위치가 옮겨져도 같은 특성을 가진다는 것이다. 강아지가 있는 그림에서 강아지의 위치가 왼쪽 아래에서 오른쪽 위로 이동하더라도 강아지라는 대상의 속성은 변하지 않는다. 이러한 특성을 반영하기 위해 커널을 한 부분에만 적용하지 않고 이동시키며 이미지 전체에 대해 연산을 수행하는 것 역시 CNN의 Inductive Bias를 반영한 연산이다.
CNN에 이미지의 공간적 특성에 따른 Inductive Bias가 적용되었다면 , RNN에는 시간에 따른 Inductive Bias가 적용된다. RNN은 주로 시간에 따라 변화하는 음성이나 실시간 데이터를 처리하는데 사용되기 때문이다.
RNN은 Sequential과 Temporal Invariance라는 Inductive Bias를 가진다. Sequential은 입력이 순차적인 특성을 가진다고 가정하는 것이며, Temporal Invariance는 시간에 따라 네트워크의 출력이 변하지 않는다는 가정이다. Sequential을 반영하기 위해 네트워크의 입력을 순차적으로 넣게 되며 Temporal Invariance 특징에 따라 시간에 따른 출력을 얻게 된다.
[출처 | 딥다이브 Code.zip 매거진]
