1️⃣ 자기회귀 모델 (Autoregressive Model)
📎 자기회귀 통계적 의미
- 통계학에서 자기회귀(Autoregressiveness)란 이후 값이 이전 값에 선형 의존 (Linearly Dependent)한다는 의미임
- 현재 시점의 데이터 는 시점 이전의 데이터 들의 선형결합과 라는 White Noise으로 이루어져 있음.
- 여기서 는 시점 이전의 데이터에 곱해지는 가중치로, 자기회귀 모델에서 학습가능한 파라미터임
📎 자기회귀 활용분야
- 1) 시계열 분석에서의 ARIMA(Autoregressive Integrated Moving Average)
- 2) 딥러닝의 RNN(Recurrent Neural Network)
- 3) 자연어처리 분야의 N-gram
- 4) 오디오 처리 분야에서의 Wavenet
🤔 ARIMA 모델은 모델의 특정 파라미터(AR 차수, 차분의 차수, MA 차수)로 결정
- 자동회귀(AR: AutoRegressive)
- 누적이동평균(I: Integrated): 데이터의 차분값(differencing)
(현재값과 이전값간의 차이)- 이동평균(MA: Moving Average): 시간에 따른 평균값의 변화를 나타내는 모델입니다. 이동평균은 일정 기간 동안의 관측값들의 평균을 계산하여 경향을 파악합니다.
📎 자기회귀 동향
-
최근 자기회귀를 기반으로 한 모델들의 인기가 떨어진 것은 병렬 연산이 불가능하다는 점 때문이다.
-
GPU 등의 현대 연산 유닛은 병렬 연산에 최적화된 구조를 가지고 있는데 자기회귀 기반 모델들은 특정 시점의 데이터가 이전 시점의 데이터에 의존하기 때문에 직렬적인 연산을 수행하고, 이에 GPU나 TPU 등의 이점을 십분 활용하지 못한다.
최근, Transformer 등 Attention을 기반으로 한 병렬 연산 모델들이 주목을 받고 있음
📑 Autoregressive Model | ARIMA 모델 예시
📌 라이브러리 임포트 및 예제 데이터 생성
import numpy as np
import matplotlib.pyplot as plt
import statsmodels #통계학 패키지
# 예제 데이터 생성
np.random.seed(0)
temperature = []
for i in range(30):
temperature.append(10 + i / 2 + np.random.randint(-3,1)) # 랜덤한 변동 포함📌 자기회귀 모델 구축 및 학습
# 입력 특성과 타깃 변수 준비
X_train = []
y_train = []
for i in range(3, len(temperature)):
X_train.append(temperature[i-3:i])
y_train.append(temperature[i])
# 자기회귀 모델 구축 및 학습
model = statsmodels.tsa.ar_model.AutoReg(y_train, lags=3)
result = model.fit() # 최대 3개의 이전 시점 값을 사용
# 다음 날의 온도 예측
next_day = temperature[-3:]
next_temperature = result.predict(start=len(y_train), end=len(y_train) + 2)📌 시각화
# 온도 그래프 플로팅
plt.plot(range(len(temperature)), temperature, label='Actual Temperature')
plt.plot(range(len(temperature), len(temperature) + len(next_temperature)), next_temperature, 'ro', label='Predicted Temperature')
plt.xlabel('Day')
plt.ylabel('Temperature')
plt.title('Temperature Changes')
plt.legend()
plt.savefig('AR.png')
plt.show()- lags = 3으로 설정한 것은 이 페이지 상단에 소개했던 수식 속의 = 3이라는 것을 의미함
- 즉 이 모델은 이전 3개의 시점의 데이터를 바탕으로 다음 시점의 데이터를 예측하는 것
- AutoReg 모델이 가중치 파라미터를 학습해 시각화 그림 속 빨간 점들을 예측함
2️⃣ CNN
📎 합성곱 신경망(Convolutional Neural Networks , CNN)
- 기존 Fully Connected Neural Network의 입력 데이터는 1차원 배열 형태로 한정됨
- 따라서 이미지 데이터로 신경망을 학습시켜야 할 경우, 3차원 이미지데이터(RGB)를 1차원으로 평면화(Flatten) 시킨 후 모델에 입력해야했음
- 이 과정에서 이미지의 공간적 정보가 손실되어, 모델의 특징 추출 및 학습이 비효율적이고 정확도의 한계가 발생함.
-따라서 이미지를 그대로 입력 받음으로써 공간적/지역적 정보를 그대로 유지한 상태로 학습을 가능하도록 한 모델CNN이 제안됨
⚑ 구조 ⚑
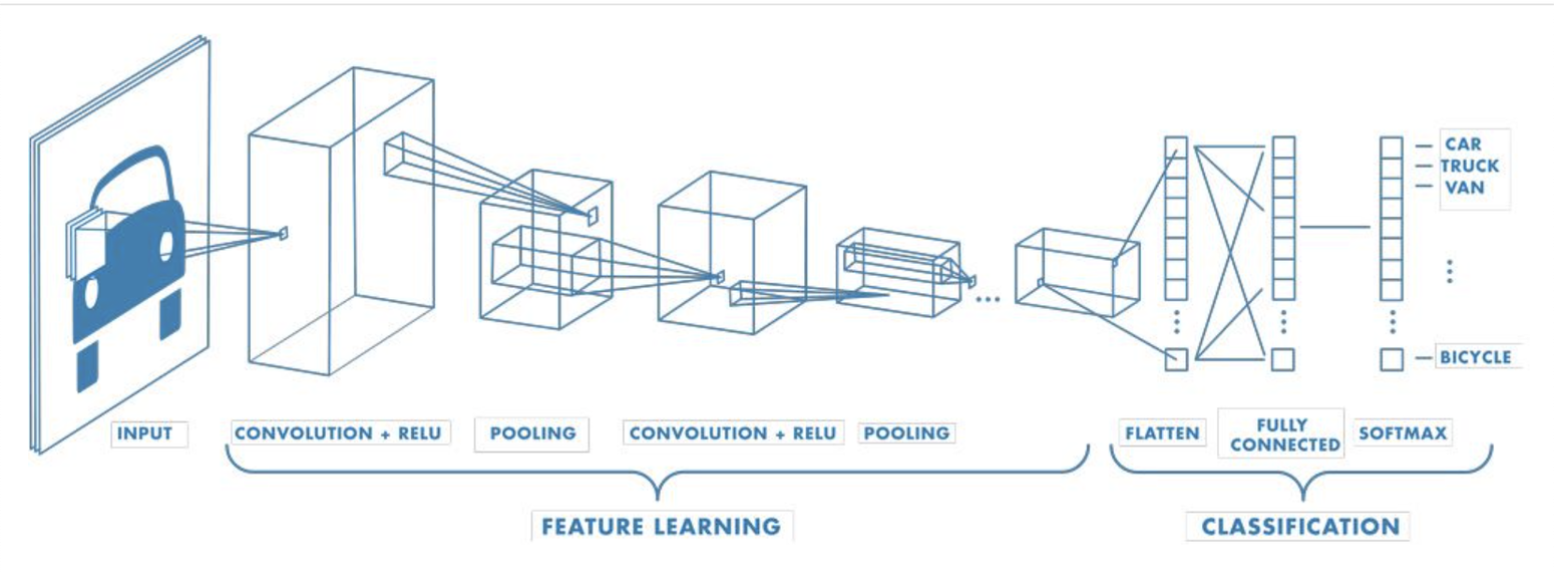
- CNN 은 위 이미지와 같이 이미지의 특징을 추출하는 부분과 클래스를 분류하는 부분으로 나눌 수 있음
- 특징 추출(Feature Extraction) 영역은 Convolution Layer, Pooling Payer를 여러 겹 쌓는 형태로 구성됨
- CNN의 마지막 부분에는 이미지분류(Classification)를 위한 Fully Connected Layer를 적용한 후 softmax를 적용해주면 클래스 별로 분류되는 확률이 최종 출력값으로 나오게 됨
⚑ Convolutional Layer(합성곱 계층) ⚑
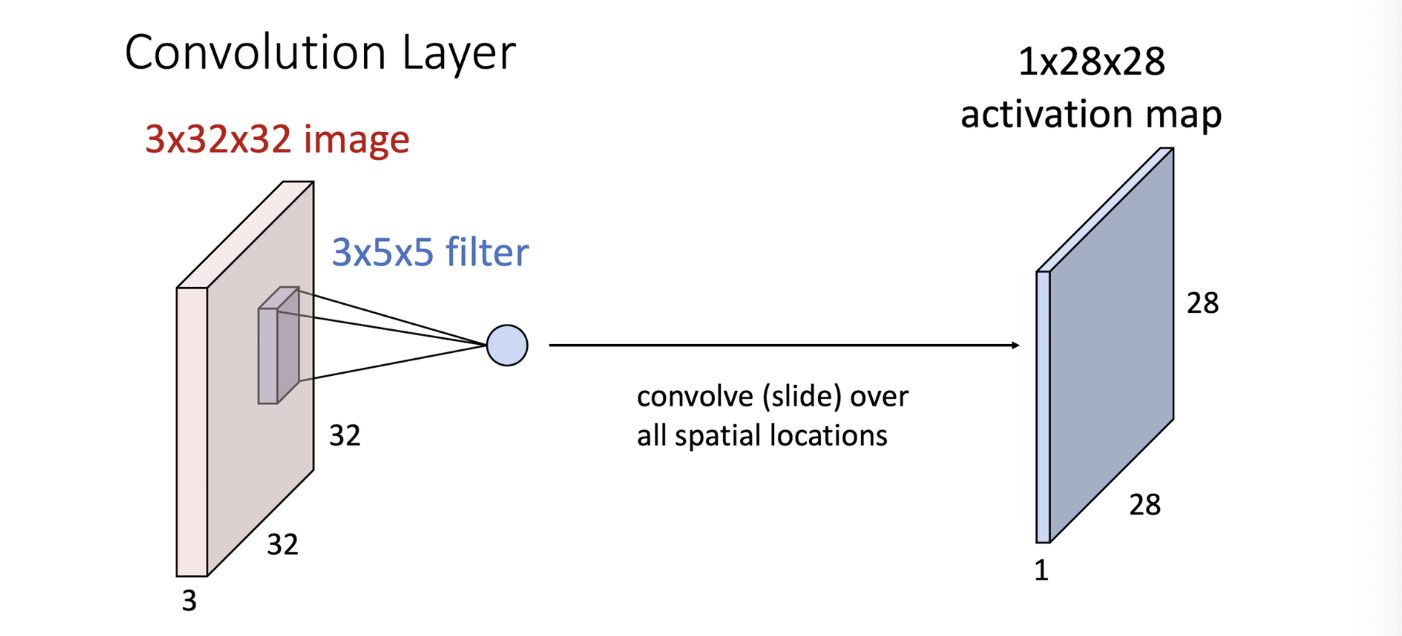
- 이 계층에서는 이미지에 필터를 적용하여 Feature Map을 얻음
- 위 그림에서는 3 ✕ 32 ✕ 32 크기의 이미지에 3 ✕ 5 ✕ 5 크기의 필터를 적용하여 1 ✕ 28 ✕ 28 크기의 Activation Map을 생성함
- 여기서 3은 채널 수(Channel 혹은 Depth)이며, 이미지가 RGB 이기 때문에 3이고, 흑백인 경우 1이 된다.
쉽게 말해서, 필터를 이미지의 맨 왼쪽 위에 가져다 댄 후 내적하면 숫자 하나가 나오고 그 값이 Activation Map 의 맨 왼쪽 위의 값으로 들어가게 된다. 그래서 결과로 나오는 Activation Map 의 크기가 32 - 5 + 1 = 28 이 되는 것이다.
이러한 결과 값을 Feature Map 또는 Activation Map 이라고 부른다. 이 때, 특징을 여러 개 뽑기 위해서 여러 개의 필터를 사용하고, 여러개의 Activation Map 이 생성된다.
✜ Stride
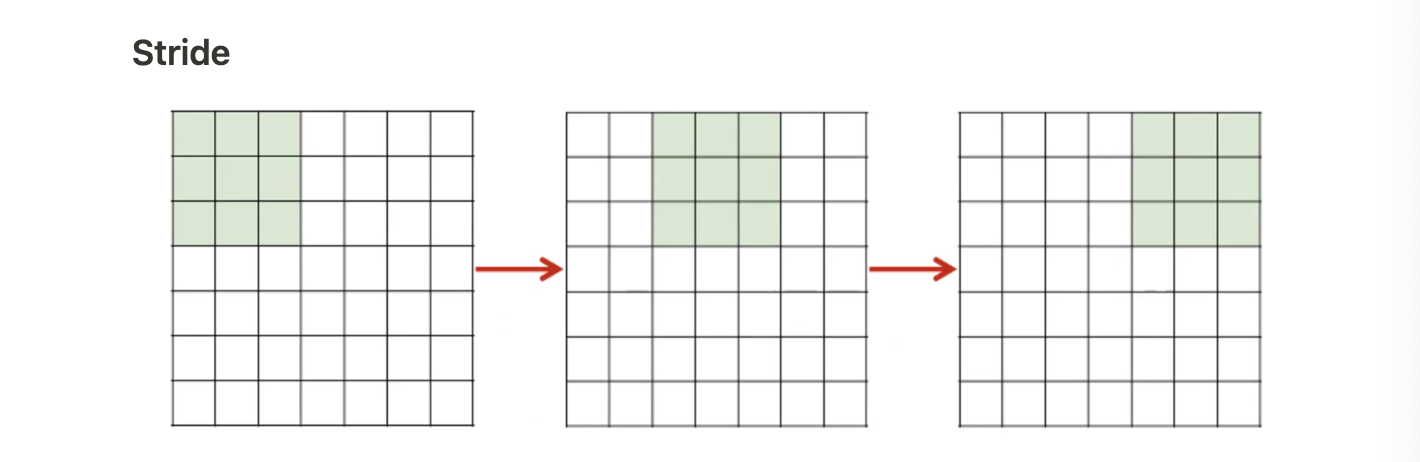
-
보통은 필터가 이미지 기준으로 한 칸씩 이동하며 계산을 하지만 여러 칸씩 이동이 가능하다.
-
그 이동의 보폭을 Stride라고 하며 위 그림에서는 두 칸씩 이동하면서 연산하도록 파라미터를 통해 조절했으므로 Stride는 2가 된다.
✜ Padding
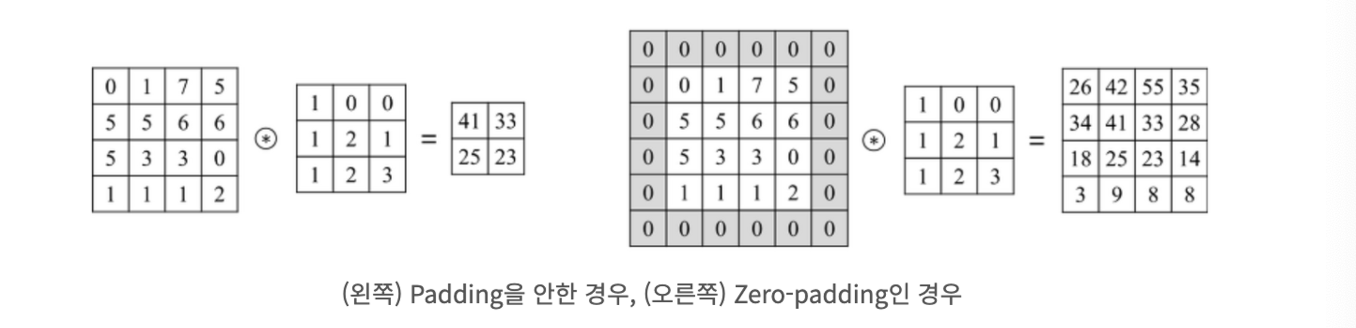
입력 이미지의 가장자리에 측정 값으로 설정된 픽셀들을 추가함으로써 입력 이미지와 출력 이미지의 크기를 같거나 비슷하게 만드는 역할을 수행한다. 0의 값을 갖는 픽셀을 추가하는 것을 Zero-Padding 이라고 하며, CNN 에서는 주로 Zero-Padding 이 사용된다.
Pooling Layer
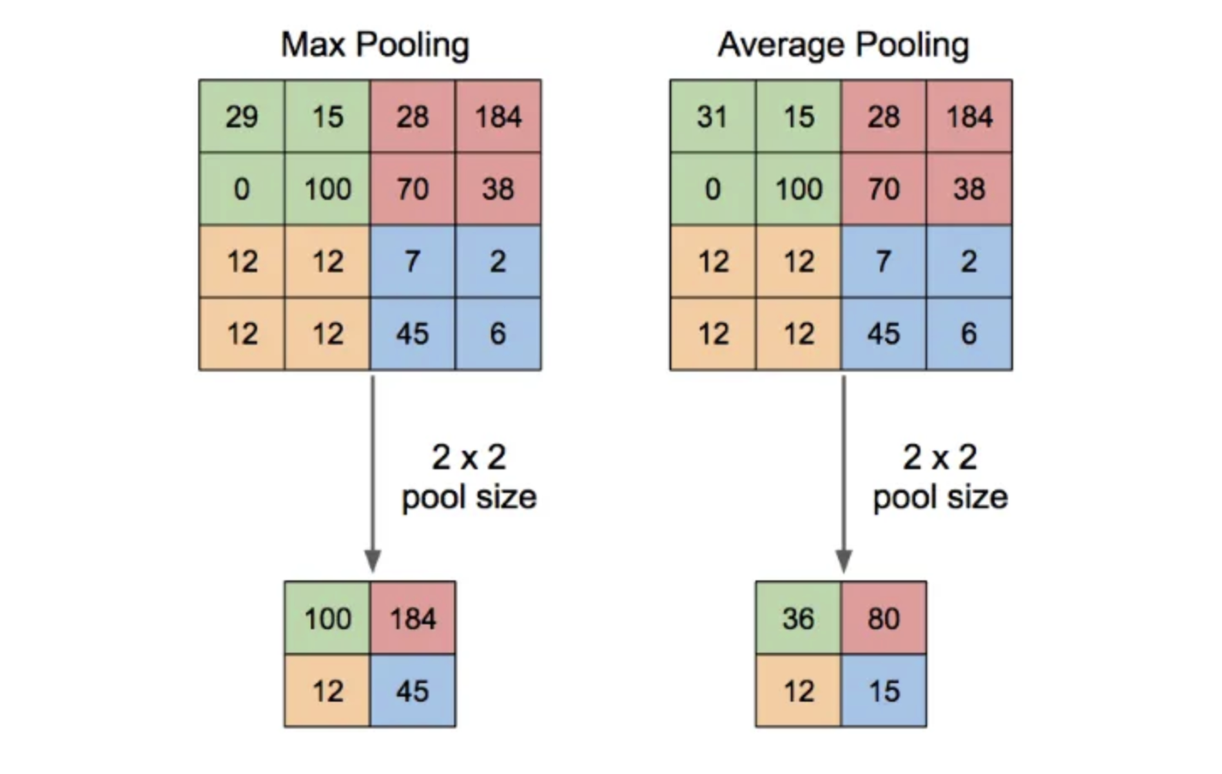
-
Pooling 계층에서는 이전 합성곱 과정을 통해 생성한 결과(Feature Map)에서 비교적 상관관계가 낮은 부분은 삭제함으로써 차원을 줄이는 과정을 수행한다.
-
Pooling 에는 대표적으로
Max Pooling과Average Pooling이 있다. -
위 이미지와 같이 선택 영역의 크기가 2 ✕ 2인 경우,
- Max Pooling은 해당 크기의 행렬에서 가장 큰 값(Max)을,- Average Pooling은 평균값(Avaerage)을 취해서 Feature Map의 크기를 반으로 줄인다.
선택 영역의 내부에서는 객체의 이동이나 회전에 의해 픽셀의 위치가 변경되더라도 출력값이 동일하기 때문에 객체가 이동이나 회전하더라도 같은 객체로 인식할 수 있다. 또한 모델이 처리해야 하는 이미지의 크기가 줄어들기 때문에 모델 파라미터 수가 줄어들어 학습시간을 크게 절약할 수 있다.
✜ Fully Connected Layer(전결합층)
Fully Connected 계층에서는 앞에서 얻은 다차원 벡터의 행렬을 1차원 배열로 만들고 softmax 함수를 통해 이미지를 이미 정의된 분류 라벨 중에 하나로 분류한다.
💡 따라서 요약하자면, CNN은 합성곱과 Pooling 을 반복적으로 사용하면서 특징을 찾고, 그 특징을 입력데이터로 Fully Connected Layer 에 보내서 카테고리 중에 하나로 분류하는 작업을 한다.
3️⃣ RNN
💡 메모리셀(RNN 셀) : 은닉층에서 활성화 함수를 통해 결과를 내보내는 역할을 하는 노드, 이전의 값을 기억하려고 하는 일종의 메모리 역할을 수행한다.
은닉상태(hidden state) : 메모리 셀이 출력층 방향 또는 다음 시점의 메모리셀에 보내는 값을 의미한다.
📎 순환 신경망 (Recurrent Neural Network, RNN)
-
RNN은 자연어 처리 분야에서 많이 쓰이는 딥러닝의 가장 기본적인 시퀀스 모델임
-
예를 들어 자연어 처리 모델을 통해 한국어-영어 번역을 한다고 하자. 입력으로 주어지는 한국어 문장도 단어의 시퀀스이고 출력으로 나와야 하는 번역된 영어 문장도 시퀀스라고 할 수 있다. 이러한 시퀀스들을 처리하기 위해 고안된 모델을 시퀀스 모델이라고 한다.
RNN 구조
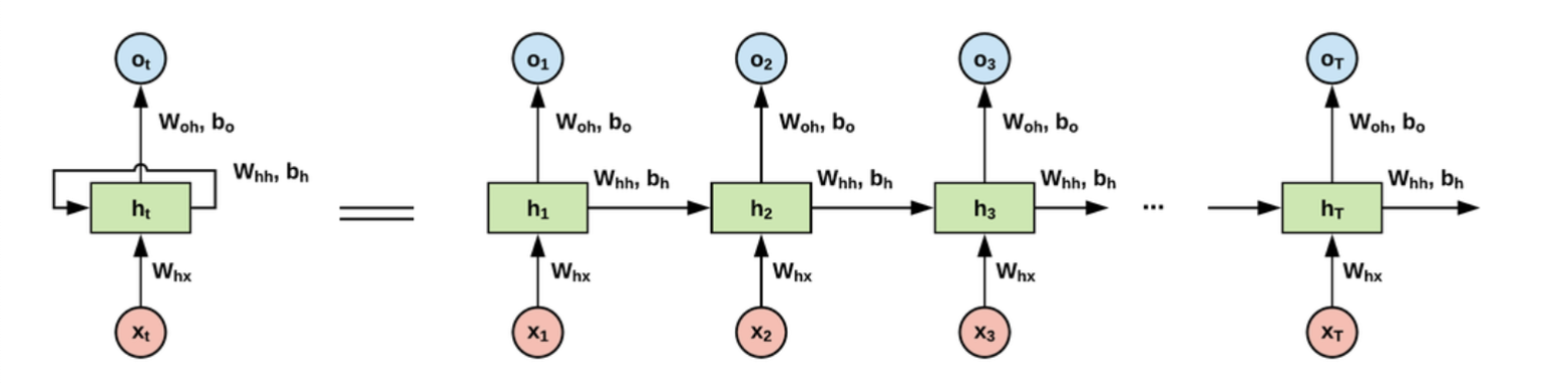
- RNN은 일반적으로 위 그림의 좌측처럼 화살표로 사이클을 그려서 재귀 형태로 표현하기도 하고,
- 우측처럼 여러 시점으로 펼져서 표현하기도 한다.
- 우측을 자세히 보면 이전 시점의 은닉 상태값이 다음 시점의 메모리셀에 입력값으로 사용된다.
RNN 수식
은닉층 :
출력층 :
현재 시점의 은닉상태 값은 라고 할때, 이 값은 이전 시점 에서의 은닉상태 값, 그리고 현재 시점의 입력층 에서 을 받아서 갱신된다.
이전 시점의 은닉상태와 현재 시점의 입력값은 각각 를 학습을 위한 가중치로 가진다. 각 가중치와 입력값을 곱하고 편향 를 더한 뒤 활성함수 Tanh 에 넣으면 현재 시점의 은닉상태 값 을 구할 수 있다.
RNN 활용
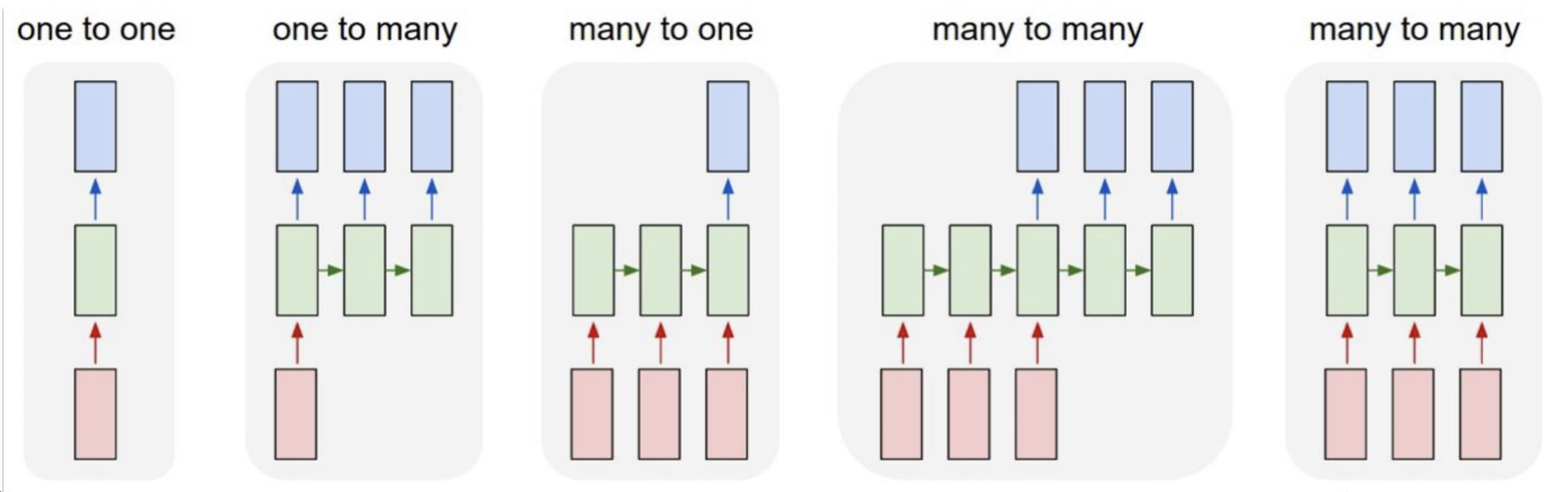
RNN은 입력과 출력의 길이가 고정되어 있지 않아서 설계에 따라 다앙한 용도로 사용할 수 있다.
-
일대다 모델 (one-to-many)
하나의 입력에 대해 여러개의 출력을 하는 모델로, 하나의 이미지 입력에 대해 사진의 제목을 출력하는 이미지 캡셔닝에 사용 가능하다. 사진의 제목은 단어들의 나열이므로 시퀀스라고 할 수 있다. -
다대일 모델(many-to-one)
단어 시퀀스에 대해 하나의 출력을 하는 모델로, 입력 문서가 긍정적인지 부정적인지를 판별하는 감성분류 , 메일이 정상메일인지 스팸메일인지 분류하는 스팸 메일 분류 등에 사용할 수 있다. -
다대다 모델(many-to-many)
사용자가 문장을 입력하면 대답문장을 출력하는 챗봇과 입력문장으로부터 번역된 문장을 출력하는 번역기, 또는 품사 태깅 같은 작업이 속한다.
[출처 | 딥다이브 Code.zip 매거진]
