1️⃣ AutoML
-
AutoML은 "Automated Machine Learning"의 약자로, 기계 학습 작업을 자동화하는 방법을 말한다.
-
기계 학습은 데이터를 분석하여 패턴을 식별하고 예측 모델을 구축하는 작업이다. 이 작업은 보통 데이터 전처리, 특징 선택, 알고리즘 선택, 하이퍼파라미터 튜닝 등 다양한 단계와 결정 사항을 포함한다.
-
AutoML은 이러한 기계 학습 작업의 여러 단계를 자동화하여 기계 학습 프로세스를 단순화하고 가속화한다. AutoML은 일반적으로 머신 러닝 모델의 성능을 향상시키기 위해 여러 가지 기술과 접근 방식을 사용한다.
-
예를 들어, AutoML은 데이터 전처리 단계에서 결측치 처리, 이상치 탐지, 특징 스케일링 등과 같은 일반적인 전처리 작업을 자동으로 수행할 수 있다. 또한 특징 선택 및 추출 방법, 알고리즘 선택 및 구성, 하이퍼파라미터 튜닝 등과 같은 다양한 모델 구성 요소를 자동으로 최적화할 수 있다.
-
AutoML은 전문적인 기계 학습 지식이 없는 사람들에게도 기계 학습 모델을 구축하고 활용할 수 있는 기회를 제공한다. 이를 통해 비전문가들도 기계 학습을 사용하여 데이터를 분석하고 예측 모델을 구축할 수 있게 된다.
📍 사용 예시 (LazyPredict)
(1) 데이터 불러오기
출처: UCI Machine Learning Repository: Wine Quality Data Set
- 와인 품질 분류 데이터이다.
- 사이트에서 제공되는 Dataset 중 레드와인 데이터만 사용하였다.
- 총 12개의 컬럼과 1599개의 행으로 이루어져 있다.
- Target은 quality 컬럼으로 0~10 사이의 점수로 매겨져 있다.
import pandas as pd
# 다른건 몰라도 sep = ','이건 꼭 넣어야함!! 안넣으면 모든 데이터가 하나의 열로 출력됨
wine = pd.read_csv("winequality-red.csv", header = 0, encoding = "UTF-8", sep = ',')(2) 패키지 설치하기
!pip install scikit-learn==0.23.1
!pip install -q lazypredict- Colab 기준으로는 위 설치가 끝나면 런타임을 다시 시작해줘야 한다.
(3) 데이터 준비하기(train/test 쪼개기)
y_data = wine.pop('quality')
x_data = wine
print(x_data.shape)
print(y_data.shape)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
x_data,
y_data,
test_size=0.2,
random_state=20230215,
stratify=y_data) # 클래스 비율을 동일하게 분할
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)(4) LazyPredict 돌려서 회귀모델 성능 비교하기
from lazypredict.Supervised import LazyRegressor
reg = LazyRegressor(verbose=0, predictions=True)
models, predictions = reg.fit(X_train, X_test, y_train, y_test)
models- 위 코드를 돌리면 자동으로 몇 초 만에 아래의 결과 값이 나온다.
- 무거운 데이터셋을 넣으면 시간이 엄청 오래 걸리고 심지어 코랩에서는 램이 터져버리니 주의하자.
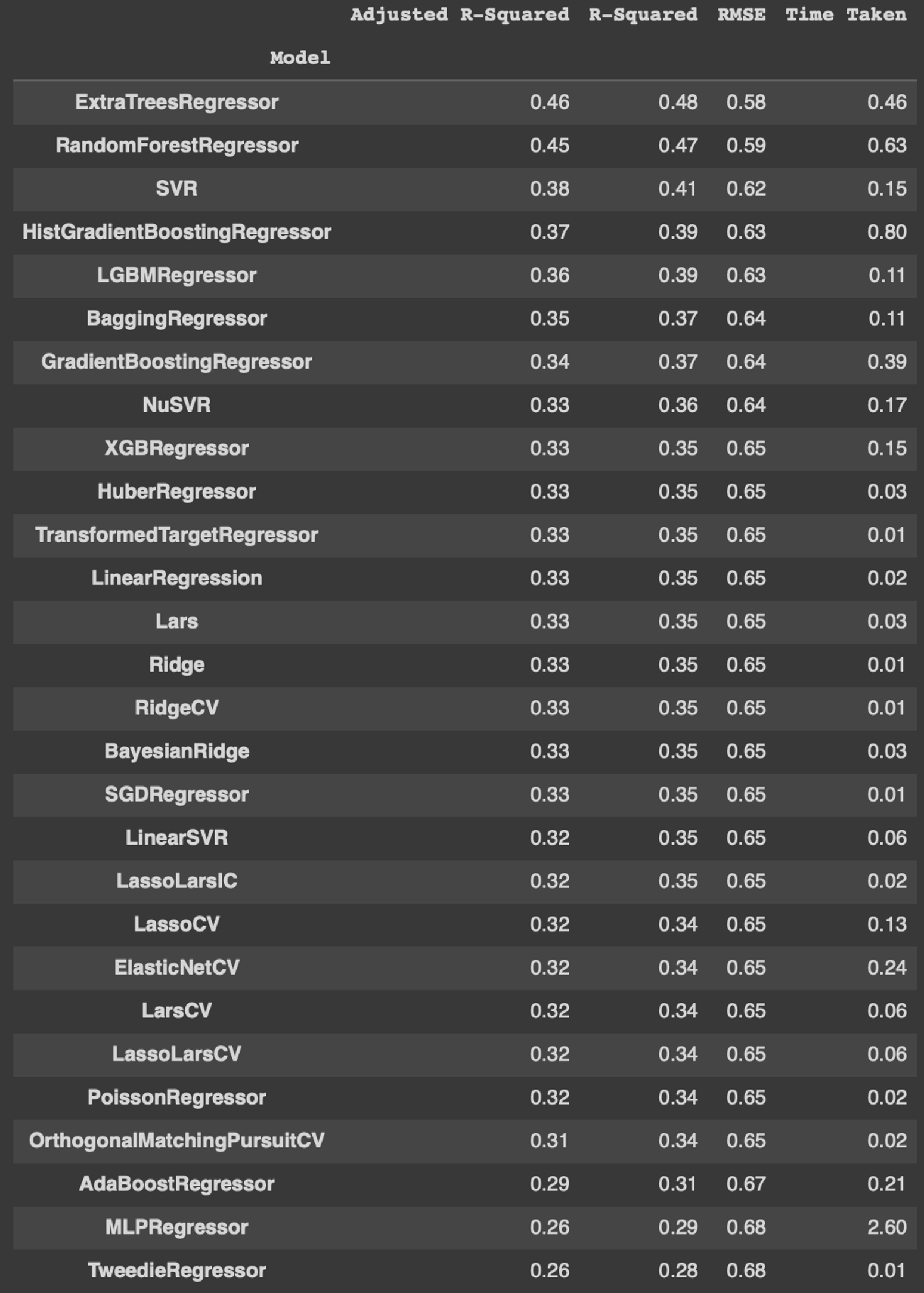
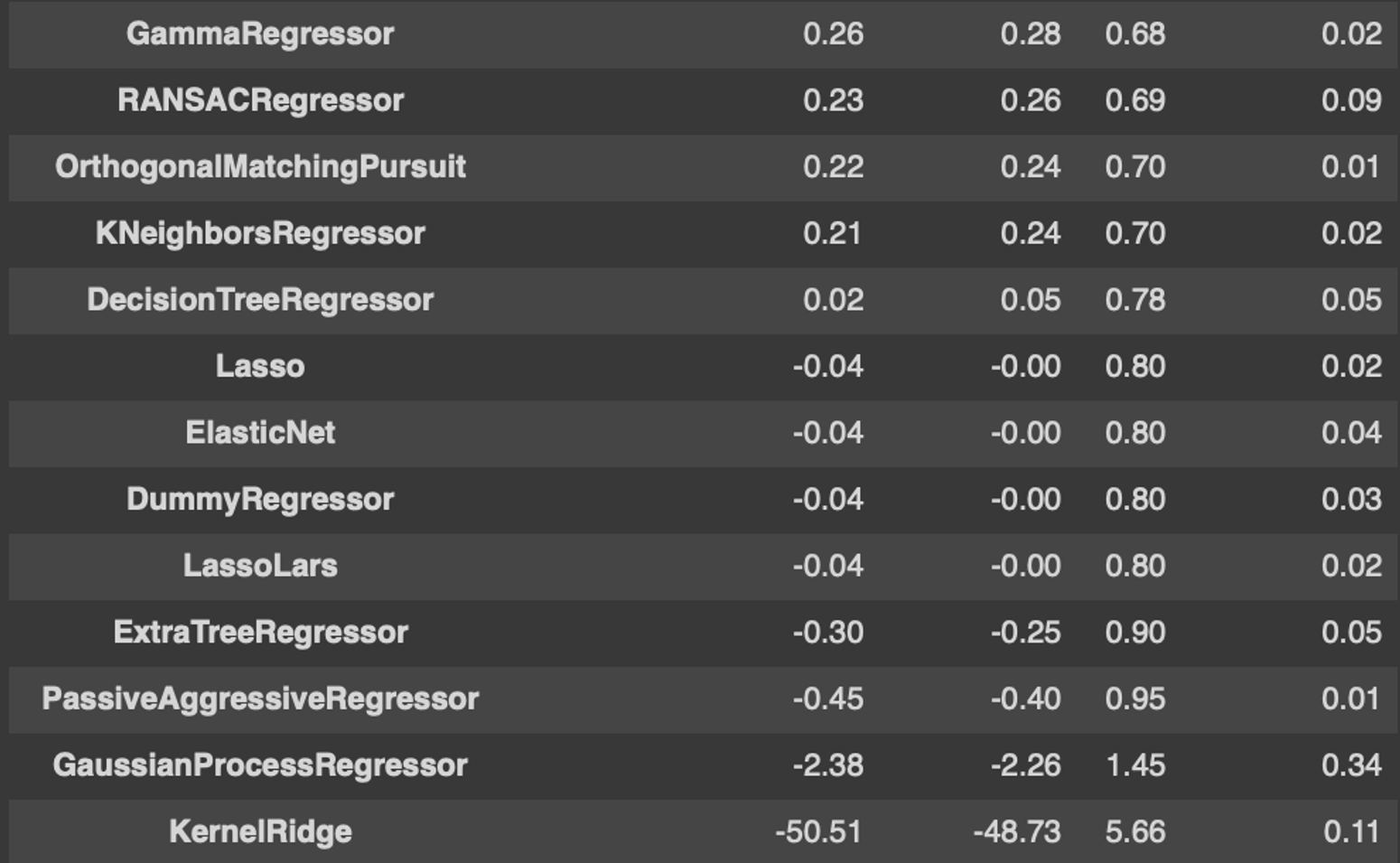
딱 여기까지가 LazyPredict으로 얻을 수 있는 결과이다. 제일 좋은 결과를 낸 모델은 RMSE값이 제일 낮게 나온 'ExtraTreesRegressor'인 것을 알 수 있다.
2️⃣ DownSampling | UpSampling
👩🏻💻 DownSampling
- DownSampling은 이름에서도 알 수 있듯이 Sample의 개수를 줄이는 것이다.
- 딥러닝에서 인코딩을 진행할 때에 데이터의 수를 줄이는 과정이기도 하다.
- DownSampling은 다음과 같은 방법으로 진행할 수 있다.
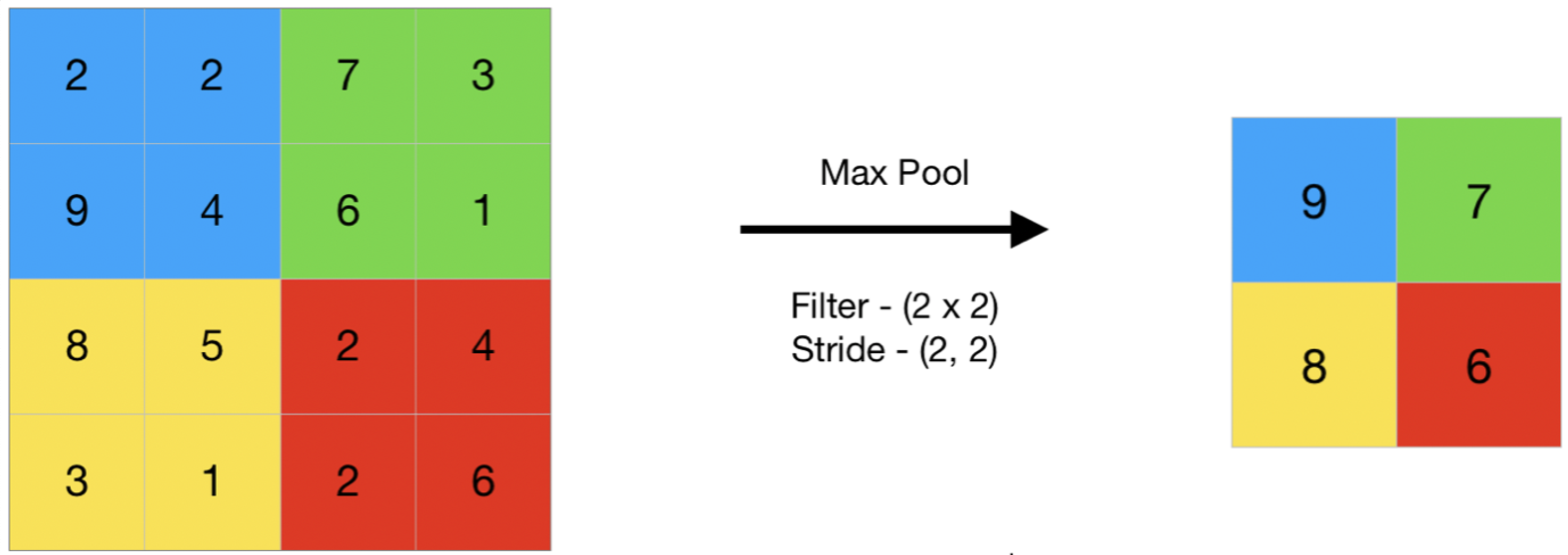
📌 Pooling
- Pooling은 일정한 규칙에 의하여 Kernel 내에서 값을 계산하는 방법이다.
- 일정한 규칙이라 함은 일종의 함수를 말하는데, 구체적인 예시를 통해 살펴보자.
-
위의 그림은 Max Pooling을 그림으로 나타낸 것이다.
-
위 이미지와 같인 해당 Kernel 내에서 최대 값을 추출하여 요약된 데이터를 만들어내는 것이 Max Pooling이다.
-
이외에 평균 값을 계산하는 Average Pooling도 있다.
-
Pooling이 DownSampling의 일반적인 방법이라고 볼 수 있다.
-
대게 Average Pooling에 비해 Max Pooling을 자주 활용한다.
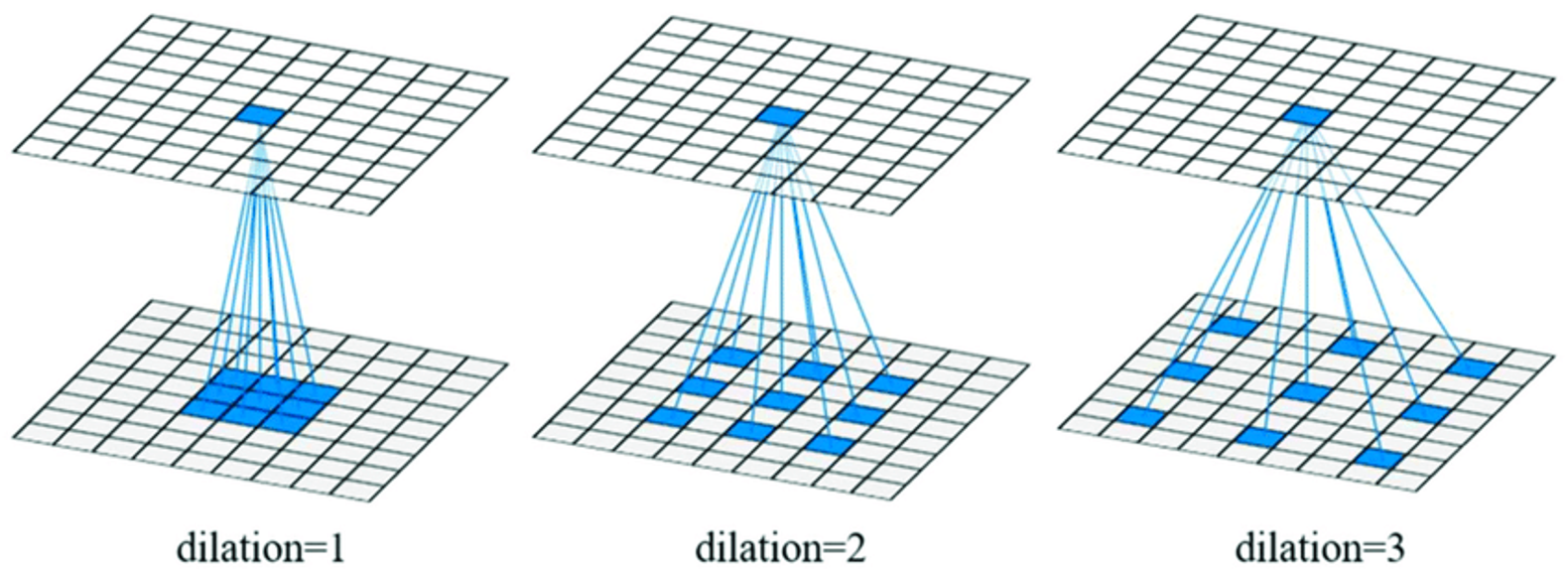
📌 Dilated Convolution
- Convolution은 위의 Pooling과 달리 학습의 과정을 거치기 때문에, 더욱 효과적인 DownSampling이 가능하다.
- 그러나 Receptive Field를 크게 만들기 어렵다는 문제가 발생한다. Receptive Field가 커지면, 학습 파라미터의 수가 무수히 늘어나기 때문이다.
- 이와 같은 단점을 보완하기 위해 등장한 것이 Dilated Convolution이다.
🤔 Receptive Field
: 출력 Layer의 뉴런에 영향을 미치는 입력 뉴런들의 공간 크기이다. 쉽게 말해, 필터가 한 번에 보는 영역을 의미한다.
- Dilated Convolution의 Filter는 일반적인 Convolution Filter 사이에 빈 공간을 넣어 구멍이 뚫려 있는 듯한 구조를 가지게 된다.
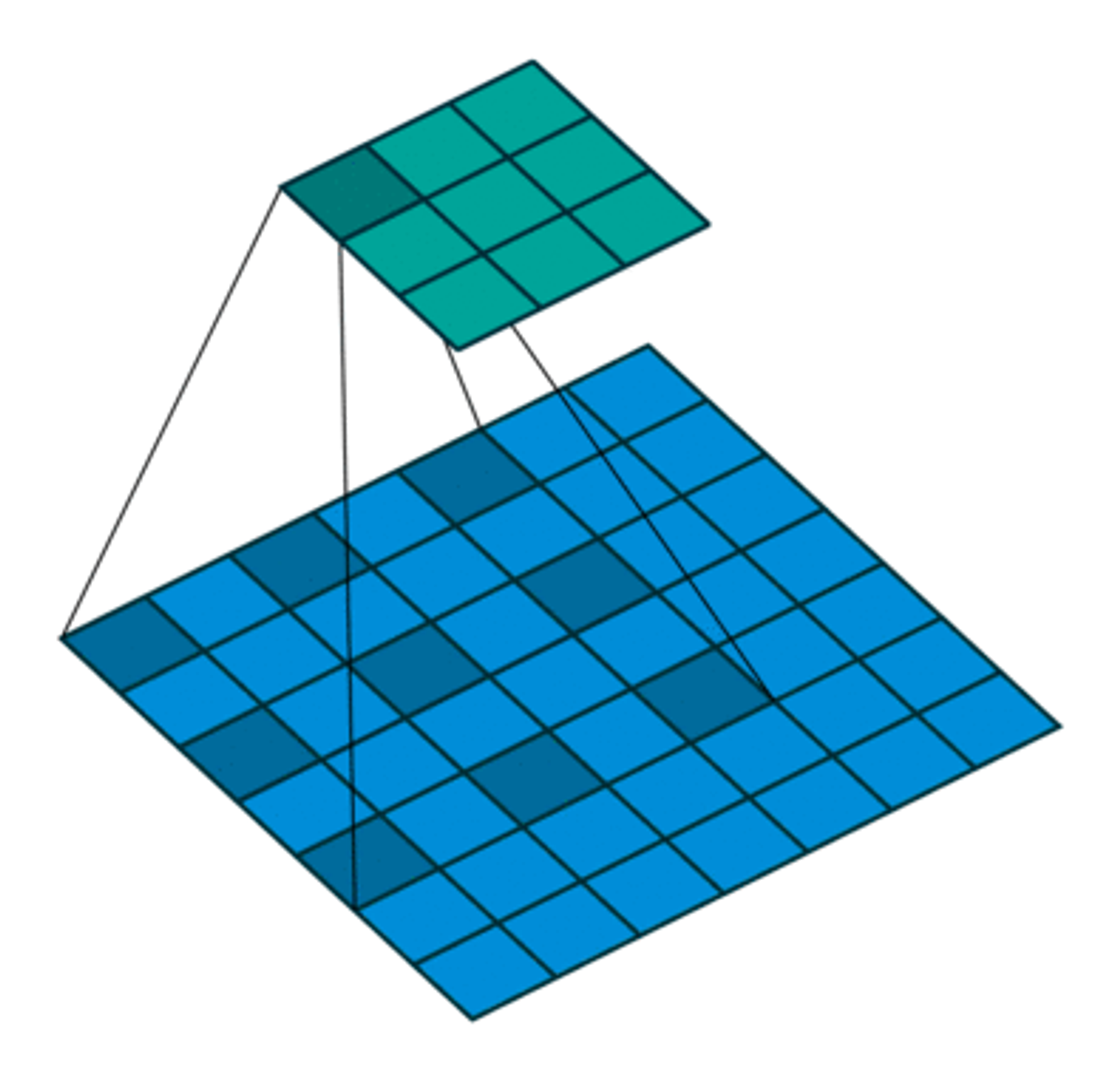
Dilated Convolution을 수행하면 기존 Convolution과 동일한 양의 Parameter와 계산량을 유지하면서도, Receptive Field는 커진다. Dilated Convolution을 시행할 때는 확장비율(Dilation Rate)를 지정하여 Filter 사이에 빈 공간을 얼마나 둘지를 결정한다.
👩🏻💻 UpSampling
UpSampling은 Downsampling의 반대로, 디코딩을 할 때에 데이터의 크기를 늘리는 과정이다. Upsampling의 방법 중 대표적인 방법을 살펴보자.
📌 Unpooling
Unpooling은 Max pooling을 거꾸로 재현하여 주변 픽셀들을 동일한 값으로 채우거나(Nearest Neighbor Unpooling), 0으로 채워주는 방식(Bed of NailsUnpooling)이다.
📌 Max Unpooling
Unpooling 방식에는 한 가지 문제가 있다. 위의 그림처럼 2 × 2 크기의 행렬로 Max Pooling된 데이터가 있다고 하자. 이를 원래 사이즈인 4 × 4 크기의 행렬로 Unpooling 하게 되면 원래 Max Pooled된 값의 위치를 알 수 없다. 이를 개선하기 위해 Max Unpooling이라는 방법을 사용하게 된다.
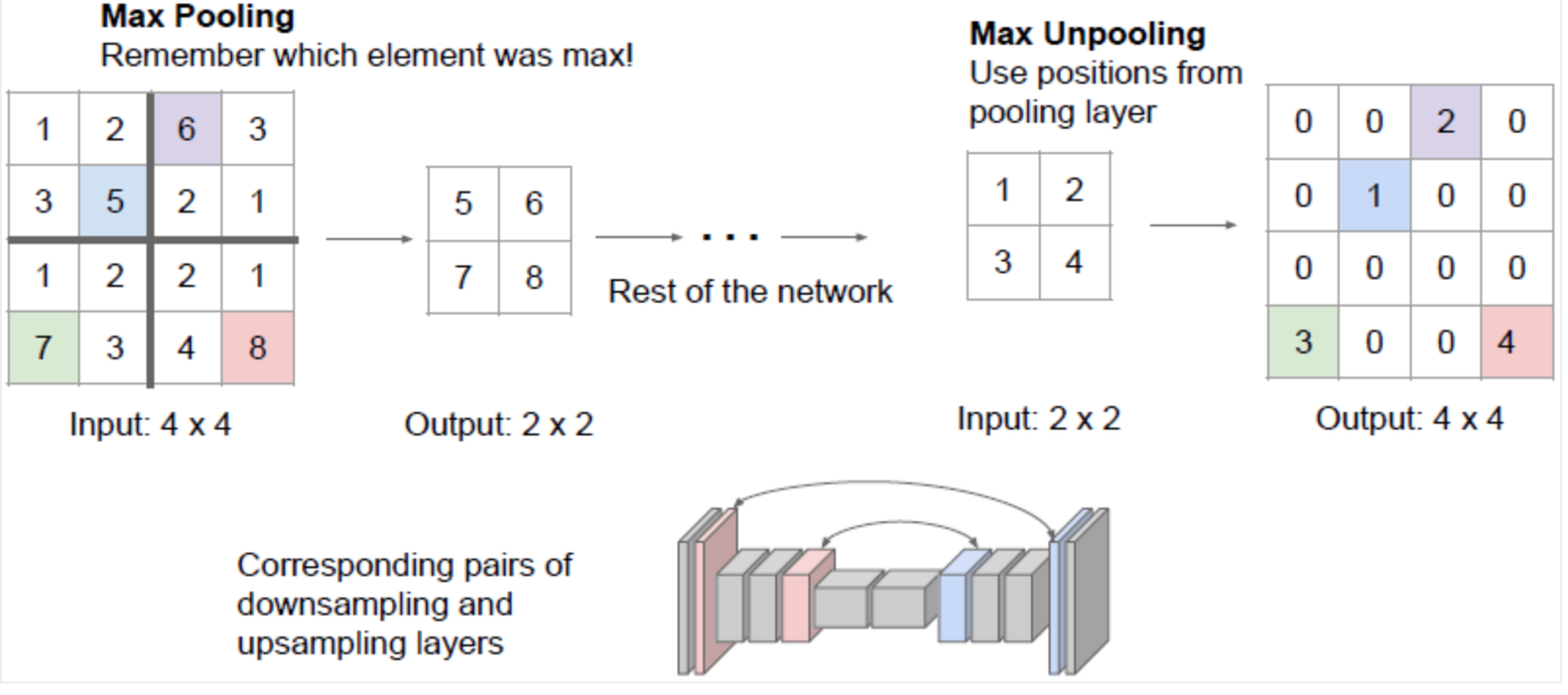
위 그림과 같이 Max Pooling할 때의 선택된 값들의 위치를 기억해 원래 자료의 동일한 위치에 최대값을 위치시켜 Unpooling하는 것이다.
[출처 | 딥다이브 Code.zip 매거진]
