1️⃣ Diffusion
💡 디퓨전의 원리
디퓨전(Diffusion)은 생성 모델의 일종으로, 그 이름과 같은 ‘확산’ 프로세스를 반복적으로 적용하여 데이터 분포를 모델링한다.
- 디퓨전은 고해상도 이미지를 생성하고, 복잡한 데이터 분포를 포착해 내며, 생성 프로세스를 세밀하게 제어할 수 있다는 점에서 딥러닝 계의 주목을 받고 있다.
- GAN과 같은 다른 생성 모델과도 차이가 있다.
- 병렬 샘플링, 불연속 데이터를 처리할 수 있는 기능, 안정적인 훈련 역학 등의 장점을 제공한다.
디퓨전은 가우시안 노이즈를 첨가하고 제거하는 방식으로 학습함

출처 : Stable Diffusion이 대체 무엇일까?(Latent Diffusion의 작동 원리)
디퓨전이 모델의 분포를 학습하는 방식은 노이즈를 단계적으로 첨가하고, 또 단계적으로 제거하면서 원래의 데이터 샘플과 유사하도록 변환하는 것이다.
- 디퓨전 모델은 고정된 수의 단계에 대해 확산 작업을 반복적으로 적용함으로써 대상 데이터 분포에서 고품질 샘플을 생성할 수 있다.
- 여러 차원에 걸쳐 정보를 확산하고 샘플을 점진적으로 정제함으로써 데이터의 복잡한 종속성과 구조를 포착하는 방법을 학습한다.
💡 디퓨전은 ‘추론’ 과 ‘샘플링’ 과정으로 나눌 수 있다.
1. 추론:
- 추론 단계에서는 데이터의 특징을 포착하는 잠재 변수(Latent Variable)를 추정하는 것을 목표로 한다.
- 이때 주어진 데이터 샘플에서 가우시안 노이즈를 더하는 Forward Process와, 노이즈를 제거해 가는 Reverse Process를 거치며 주어진 이미지, 텍스트, 그래프 샘플들의 공통된 분포를 학습한다.
2. 샘플링:
- 추론 단계가 끝나면 디퓨전 모델은 학습된 조건부 분포를 기반으로 현재 샘플에 랜덤한 섭동(Perturbation)을 적용하여 새로운 상태를 샘플링한다.
- 이 섭동은 현재 샘플에 노이즈를 주입하여 점차적으로 목표 데이터 분포의 샘플로 변환한다.
- 변환된 샘플이 목표 분포의 고밀도 영역에 유지되도록 목표하며 샘플링하게 된다.
💡 활용 예시
디퓨전 모델은 뛰어난 생성 능력과 유연성을 가지고 있기 때문에, 복잡한 데이터 분포를 캡처하거나 새로운 데이터 샘플을 생성해야 하는 광범위한 작업에 적합하다.
⭐️ 1. 이미지 합성
실제 이미지 Dataset에 대해 디퓨전 모델을 훈련하면 Train Dataset과 유사한 새로운 이미지를 생성할 수 있다. 디퓨전 프로세스를 통해 노이즈 벡터를 점진적으로 사실적인 이미지로 변환하여 복잡한 디테일과 텍스처를 포착할 수 있다.
⭐️ 2. 이미지 노이즈 제거
입력 이미지에 노이즈가 있으면 확산 모델은 확산 프로세스를 통해 점진적으로 노이즈를 제거하여 노이즈가 제거된 이미지를 생성할 수 있다. 학습을 통해 이미지의 기본 구조를 포착해 내고, 노이즈를 콘텐츠에서 분리해 낸다.
⭐️ 3. 이미지 인페인팅
이미지에서 누락되거나 손상된 부분을 채우는 이미지 인페인팅 작업에도 사용될 수 있다. 이미지의 구조를 학습하여 누락된 영역을 채울 수 있는 그럴듯한 콘텐츠를 생성하여 시각적으로 일관된 이미지 페인팅을 만든다.
⭐️ 4. 텍스트 생성
말뭉치에서 단어 또는 문자 간의 종속성을 모델링하여 학습 데이터와 유사하며 현실적이고 일관된 텍스트를 생성한다.
⭐️ 5. 비디오 생성
디퓨전 기술은 동영상과 같은 순차적 데이터를 처리할 수 있도록 확장되었다. 여러 프레임에 걸쳐 디퓨전 프로세스를 적용하며, 시간적 일관성을 보이는 새로운 비디오 시퀀스를 생성하고 학습 데이터의 동적 특성을 포착할 수 있다.
⭐️ 6. 이상 감지
이미지, 텍스트, 시계열 등 다양한 유형의 데이터에서 이상 징후를 탐지하는 데 사용되어 왔다. 확산 모델을 정상 데이터 샘플에 대해 훈련함으로써 유사한 인스턴스를 재구성하고 생성하는 방법을 학습할 수 있다. 비정상적인 데이터를 제시하면 재구성 오류가 더 높아지는 경향이 있어 이상 징후를 식별할 수 있다.
2️⃣ Word2Vec
💡 Word2Vec
Word2Vec은 자연어 처리(NLP) 작업에서 단어를 연속적인 벡터로 표현하는 딥러닝 기법이다.
단어를 고차원 벡터 공간에 매핑하여 단어 간의 의미론적, 구문론적 관계를 의미 있는 방식으로 포착하는 것을 목표로 한다.
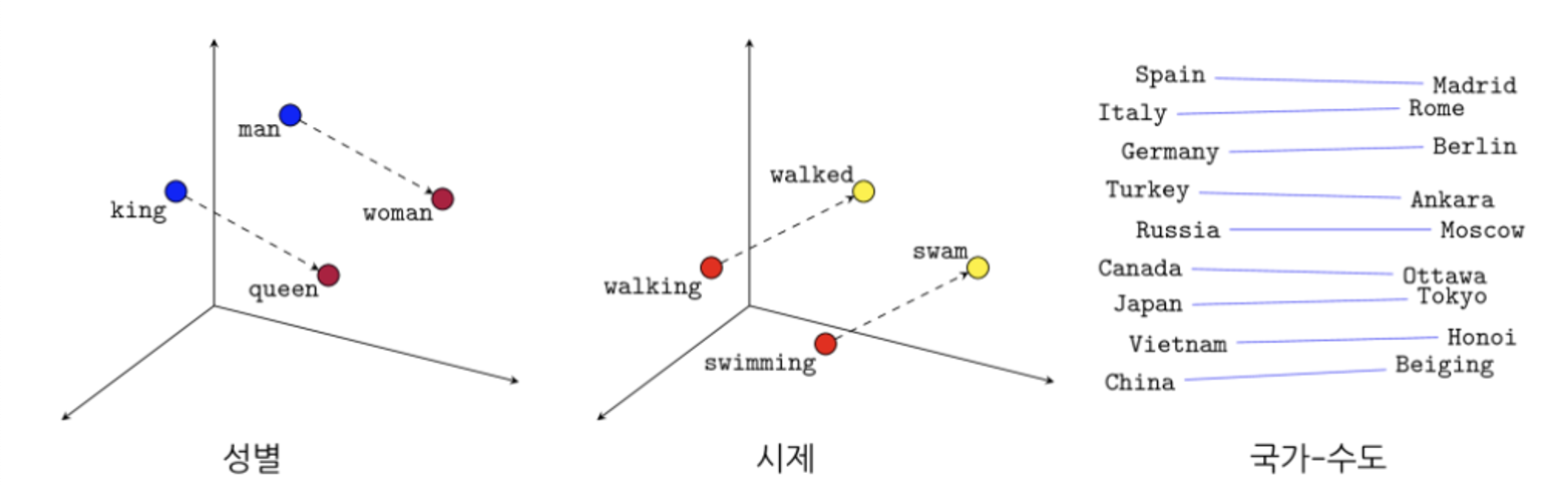
Word2Vec의 핵심 아이디어
- 단어 간의 의미적 유사성을 인코딩하는 워드 임베딩을 학습하는 것이다.
- 워드 임베딩은 단어 간의 의미 관계를 포착한다. 비슷한 의미를 가지거나 비슷한 문맥에 등장하는 단어는 비슷한 벡터 표현을 갖는 경향이 있다.
- 예를 들어, '왕'과 '여왕'과 같은 단어는 의미적 유사성을 반영하여 벡터 공간에서 가까운 벡터를 갖게 된다.
이러한 워드 임베딩은 컴퓨터가 처리할 수 있는 벡터 형태로 나타나며, 레이블이 없는 대량의 텍스트 데이터를 활용하여 학습된다. Word2Vec의 핵심 가정은 비슷한 문맥에 등장하는 단어는 비슷한 의미를 갖는 경향이 있다는 것이다.
💡 아키텍처
CBOW와 Skip-gram 모델은 모두 신경망을 사용하여 학습되며, 일반적으로 단일 계층으로 구성된다. 학습을 통해 목표 단어 또는 문맥 단어를 정확하게 예측하는 모델의 능력을 최적화한다.
⭐️ CBOW(Continuous Bag of Words)
CBOW 아키텍처에서는 문맥 단어를 기반으로 타겟 단어를 예측한다. 문맥 단어란 주어진 창 크기 안에 있는 타겟 단어 주변 단어를 의미한다. 예를 들어 “The cat sits on the mat." 라는 문장이 주어지면 CBOW 모델은 "the", "sits", "on" 및 "mat"를 입력으로 받아 목표 단어 "cat"을 예측할 수 있다.
⭐️ Skip-gram
Skip-gram 아키텍처에서는 CBOW와 반대로, 문맥이 주어졌을 때 목표 단어를 예측하는 대신 타겟 단어를 기반으로 문맥 단어를 예측한다. 동일한 예제 문장을 사용하여 Skip-gram 모델은 대상 단어 "cat"를 가지고 문맥 단어 "the", "sits", "on", "mat"을 예측할 수 있다.
Word2Vec으로 생성된 이러한 워드 임베딩은 자연어 처리 작업에서 다양하게 활용된다. 텍스트 분류, 정보 검색, 감성 분석, 기계 번역 등 다양한 자연어 처리 모델의 성능을 향상시키는 데 사용할 수 있다. 또한 단어를 연속 벡터로 표현함으로써 모델이 단어 임베딩에서 포착한 풍부한 의미 정보를 활용하여 보다 언어를 보다 효과적으로 이해하고 활용할 수 있게 된다.
3️⃣ YAKE
keyword extraction from single documents using multiple local features
- unsupervised learning, lightweight statistical method
이 장에서는 단어의 중요도를 계산하는 부분 위주로 설명할 예정이다.
📍 YAKE 정의
- Keyword Extraction은 개의 단어가 있는 문서를 받아 문서를 포괄적으로 나타낼 수 있는 명사구를 찾는 것이다.
- 머신러닝을 사용한 다른 모델은 학습 데이터랑 다른 언어에는 사용할 수 없는데,
- YAKE!는 다양한 언어에 사용할 수 있으며 긴 학습시간과 레이블 데이터 없이도 쉽게 사용할 수 있다.

- 이러한 각 구문(Phrases)은 문서에서 연속된 단어로 구성되므로 문서에 나타난 모든 후보 구문(Candidate Phrases)에 대한 일반적인 순위를 매기는 문제로 볼 수 있다.
- 따라서 일반적인 키워드 추출 파이프라인은 대상 문서 에 대한 후보구문(Candidate Phrases) Pd를 구성하고, 의 모든 개별 단어에 대한 중요도 중요도 점수(Importance Scores)를 계산하는 것으로 구현된다.
즉, 개별 단어 단위의 점수를 구하는 것이 중요한데, Statistical Method와 Graph-Based Method 두 가지 방법론으로 나눌 수 있다.
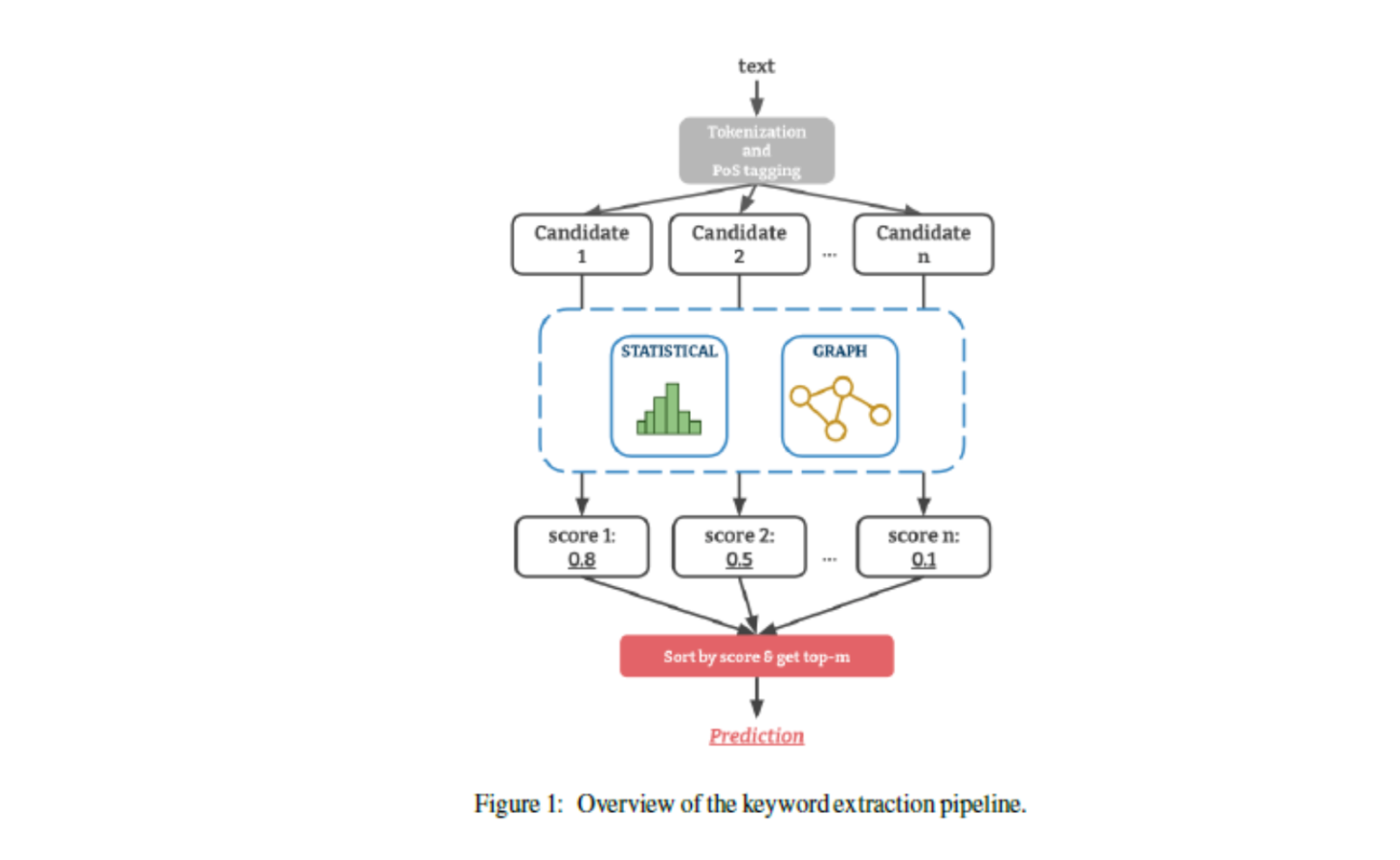
YAKE!는 개별 문서에서 중요한 키워드를 식별하기 위해 단어의 동시 등장 정도(Co-Occurrence) 나 빈도(Term Frequencies)와 같은 지역적인 텍스트 특징와 통계 정보에 의존한다. 대표적으로는 TF-IDF부터 KP-Miner, RAKE 등이 있다. 저자는 YAKE!의 장점을 다음과 같이 말한다.
⭐️ YAKE!의 장점
- 문서에 대응되는 키워드 데이터(정답데이터)가 필요없다(↔ 지도학습)
- 하나의 문서에만 의존하기 때문에 다양한 상황에서 빠르게 사용할 수 있다.
- 한번만 등장해도 중요하다고 판단할 수 있고, 여러 번 등장해도 중요하지 않다고 판단할 수 있다.
- 언어나 학습 데이터에 영향받지 않는다.(↔ 비지도 graph-based methods)
- 다양한 언어나 분야에 쓰일 수 있다.
📍 알고리즘
⭐️ Text Pre-Processing and Candidate Term Identification
-
segtok rule-based sentence segmeter를 이용해 문서를 문장 단위로 나눈다.
-
그리고 segtok segmenter의 web_tokenizer을 이용해 이 문장을 다시 띄어쓰기 단위로 쪼갠 후 토큰으로 쪼갠다.
-
각 토큰들은 다음과 같은 기준으로 분류되어 구획문자 테그가 첨부된다.
-
그 다음, 입력받는 언어에 대해 Static List로 정의된 Stopwords(불용어)를 사용해 잠재적으로 의미 없는 토큰들을 탐지한다.
-
이 전처리 단계의 결과는 문장의 리스트이며, 각 문장은 테그가 달린 부분들로 나뉜다.
[출처 | 딥다이브 Code.zip 매거진]
