1️⃣ Data Augmentation
📎 Data Augmentation 등장 배경
- 딥러닝(Deep Learning)은 기본적으로 많은 양의 데이터를 전제로 한다.
- 다양한 상황을 접할수록 모델의 학습 능력이 올라간다.
- 그러나 대량의 데이터를 구축하는 것은 비용과 시간이 많이 필요하며, 어떤 경우에는 데이터 수집하거나 가공하는 것조차 어려운 경우도 많다.
이를 해결하기 위해 기존 데이터를 약간 변형(수평 뒤집기, 무작위 회전 등)하여 새로운 데이터를 생성하고 이를 학습 데이터셋에 추가하는 과정을 데이터 증강(Data Augmentation)이라고 한다.
✼ 특히 컴퓨터 비전 분야에서 학습 데이터셋의 크기와 다양성을 증가시키는 데 자주 사용되는 방법이다.
📎 Data Augmentation 방법
PyTorch에서는 torchvision.transforms 모듈을 사용하여 데이터 증강을 쉽게 구현할 수 있다.
torchvision.transforms 모듈은 이미지 데이터에 적용할 수 있는 다양한 변환 기능을 제공한다.
예를 들어, 다음 코드는 무작위 수평 플립(RandomHorizontalFlip), 무작위 회전(RandomRotation)을 적용시키는 코드이다.
import torchvision.transforms as transforms
# 변환 정의
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(degrees=10)
])
# 데이터셋에 변환 적용
augmented_dataset = original_dataset.transform(transform)
2️⃣ End-to-End Pipeline
어떤 문제를 해결할 때 필요한 여러 단계들을 하나의 신경망을 통해 한 번에 해결하는 과정을 의미
이미지 내부에 존재하는 임의의 객체를 설명해주는 딥러닝 모델을 예시로 들어보자. 이미지를 입력으로 넣어서 그 이미지를 잘 설명하는 문장을 결과로 얻는 과정은 꽤 단순해보인다. 다만, 이 안에는 여러 단계들이 숨어있다. 먼저 이미지에 어떤 물체가 있는지 객체를 인식하고, 해당 정보를 인코딩해서 문장 생성 모델이 처리하기 좋은 형태로 변환해줘야 한다. 이후 문장 생성 모델은 이 정보를 받아서 이미지의 특징을 잘 설명하는 문장을 생성하게 된다.

일반적인 파이프라인은 위의 각 단계별마다 다른 신경망 모델을 활용한다. 이미지의 특징을 추출하는 모델, 그리고 이 결과를 받아 문장을 생성할 모델을 따로 설계해서 각 모델들의 결과들을 이어주는 방식으로 문제를 해결한다.
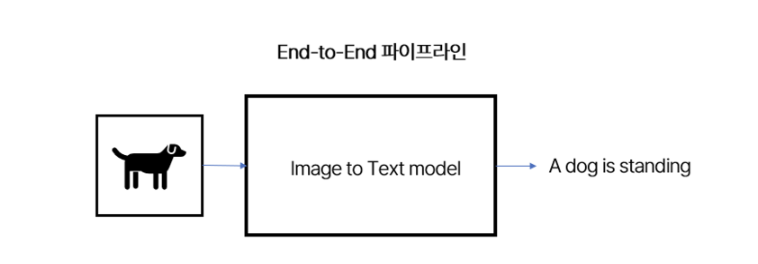
End-to-End 파이프라인은 위의 모든 과정들을 하나의 신경망으로 통합하는 방식이다. 알고리즘이 알아서 입력 이미지를 결과 이미지로 변환해주는 함수를 찾기 때문에, 기존 방식보다 편하고 효율적이다. 다만, 문제를 나눠서 해결하는 것보다 복잡한 문제를 풀어야 되며, 충분한 양의 데이터가 없다면 개별 파이프라인을 설계하는 것보다 안 좋은 성능을 보일 수 있다.
3️⃣ Fourier Transform
📎 푸리에 변환 등장 배경
-
시간에 따라 정의된 데이터를 있는 그대로 분석하는 것은 상당히 비효율적이다.
-
음성 인식, 음성 합성 등 개별 음성의 특성을 세밀하게 분석해야 하는 일들을 수행하기 위해서는 '음색' 에 대한 면밀한 학습이 필요한데, 음색을 분석하기 위해서 기존의 오디오 데이터를 수정하는 과정을 거친다.
📎 오디오 데이터 방법론
Mel Spectrogram, MFCC 등 오디오 데이터의 특징을 효과적으로 표현하기 위한 방법론이 여러 개 있으나 이러한 방법론들은 모두 시간 정의역(Time Domain)의 원본 음성을 주파수 정의역(Frequency Domain)으로 바꾸어주는 푸리에 변환(Fourier Transform)에 기초한다.
📎 푸리에 변환
- 시간 정의역의 원본 음성 데이터를 주파수 정의역으로 옮기는 과정이다.
🤔 이를 직관적으로 이해하기 위해 다음과 같은 예시를 떠올려 보자. 바닷가에 놀러갈 때 해안가에서 우리가 보는 파도는 인근 물고기떼의 헤엄, 멀리서 불어온 바람, 원양 선박의 움직임 등으로부터 복합적인 영향을 받는다. 이러한 파도의 발생 요인들을 개별적으로 규명해 해안가의 파도는 어떻게 만들어졌는지 파악할 수 있게 해주는 수학적인 방법론을 푸리에 변환이라고 할 수 있다.
📎 푸리에 변환의 수학적 이해
이제 푸리에 변환에 대해 수학적으로 이해해 보자.
🤔 은 의 줄임말이다.
모든 시간단위의 음성 신호는 위 수식과 같이 주파수 단위 신호의 가중합으로 분해될 수 있다. 는 지수함수 형태의 함수와 진폭의 선형결합인 셈이다. 분명 주파수 단위의 신호와 가중치(여기서는 Amplitude)의 선형결합으로 이루어져야 할 텐데, 주파수 단위의 신호는 삼각함수의 형태이다. 우리가 이를 지수함수 형태로 쓸 수 있는 것은 오일러 공식(Euler’s Formula) 때문이다. 아래의 오일러 공식 덕에 우리는 삼각함수 형태의 시간 단위 데이터를 지수함수 형태의 꼴로 변환할 수 있게 되었다.
이러한 수학적 변환 과정을 거쳐 시간 단위의 를 라는 주파수 단위를 매개로 하여 정의할 수 있게 해 주는 과정이 푸리에 변환이다.
푸리에 변환은 단순히 오디오 처리에서만 활용되는 방법론이 아니라 전기, 영상 등 신호 처리 영역 전반에 걸쳐 매우 포괄적으로 적용될 수 있는 변환 방법론이기에 그 활용도가 매우 높다.
4️⃣ Overfitting | Underfitting
📎 과적합(Overfitting)
모델이 학습 데이터에 과도하게 맞춰져서 실제로 작동해야 하는 테스트 데이터에서는 성능이 떨어지는 것을 의미
📎 과적합 해결 방법
1. 데이터의 양을 늘린다.
과적합은 편향된 데이터로 인해서 발생하는 문제라고 볼 수도 있으므로, 가장 간단하고 근본적인 해결책은 학습 데이터의 양을 늘리는 것이다. 이에 대한 구체적인 방법으로는 Data Augmentation 사용이 있다.
2. 모델의 복잡도를 줄인다.
위에 Overfitting 모델의 그림에서 볼 수 있듯이, 너무 복잡하고 예민하게 모델을 구성하는 것도 좋지 않다. 따라서 은닉층이나 매개변수의 수를 줄여서 모델을 단순화시키는 것도 과적합 방지 방법이다.
3. 가중치 규제(Regularization)를 적용한다.
L1 규제, L2 규제 같은 방법을 이용해서 모델의 가중치(weight 파라미터)를 규제한다. 예를 들어 모델의 수식이 같은 방식으로 있다면 에 대한 제한을 두어 모델을 단순하하는 것이다.
4. 드롭아웃(Dropout) 사용
신경망 중 일부를 의도적으로 제거해서 모델의 단순화를 돕는다. 학습을 할 때 매 학습마다 사용하지 않는 신경망을 랜덤으로 바꿔가면서 과도한 학습을 막는다. 그렇게 학습을 하고, 최종 모델의 설계에는 모든 신경망을 사용하는 것이 드롭아웃이다.
📎 과소적합(Underfitting)
과적합과 반대 개념인 과소적합은 학습 데이터가 모델에 충분히 반영되지 않았을 때 발생하는 문제이다. 즉 학습 데이터에게도 적합한 모델을 못 만든 상황이라는 것이다. 이는 모델을 위한 학습이 충분이 덜 되었거나, 데이터가 적거나, 모델이 너무 단순할 때 발생한다. 따라서 이를 해결하기 위해서는 학습의 횟수(Epoch)을 늘리거나, 데이터를 더 수집하거나, 모델을 더 복잡하게 만들 수 있다.
6️⃣ Spectrogram
- Spectrogram은 주파수 정보를 활용해 음성을 시각화한 것
- 음성 합성이나 음원 분리 등에 활용되는 대부분의 오디오 딥러닝 분석 모델이나 방법론은 그 데이터의 전처리 과정에서 원본 음성을 Spectrogram 형태로 바꾼 뒤 분석함
음성을 시각화하는 방식은 파형, 스펙트럼 2가지 형태임
1. 파형(Waveform)
- 파형은 시간에 따라 정의된 음량(Amplitude)의 함수
- 주파수와 위상에 대한 정보를 모두 포괄하는 음량의 함수라는 점에서 비교적 저차원적인(Low-Dimensional) 시각화 기법이다.
2. Spectrogram 형태
-
푸리에 변환(Fourier Transform)등의 방법론으로 원본 파형을 여러 정현파(Sinusoidal Wave)의 가중합으로 분리할 수 있고 시간에 따른 주파수 별 세기(Power, dB)의 함수를 만들어 낼 수 있는데 이러한 함수를 시각화한 것이 Spectrogram이다.
-
즉 Spectrogram은 시간에 따른 주파수의 함수이고 위상 정보를 갖지 않는다는 점에서 고차원적이다(High-Dimensional).
파형을 있는 그대로 분석에 활용하면 주파수나 위상 등의 정보를 규명하기 까다롭고 따라서 고품질의 오디오 딥러닝을 구현하기 힘든 경우가 많다. 이에 파형을 주파수 단위로 분리한 Spectrogram과 여타 정보를 함께 활용해서 섬세한 모델링을 수행할 수 있다.
2-1. Spectrogram을 모델링에 활용하는 방식
Linear Spectrogram: 단순한 푸리에 변환으로 나타냄Mel Spectrogram: Mel 변환을 더함MFCC: Mel 변환과 Cepstrum Coefficients 계산으로 정보량을 효율적으로 줄임
7️⃣ Tensor
- Tensor(텐서)는 딥러닝뿐만 아니라 수학, 물리학적 맥락에서도 사용되는 수학적 객체임
- 벡터, 스칼라 및 기타 텐서 간의 관계를 설명하며, 벡터와 행렬을 더 높은 차원으로 일반화한 것에 해당된다.
1차원 텐서가 벡터, 2차원 텐서가 행렬
머신러닝 및 딥러닝 분야에서 텐서는 다차원 배열을 표현하고 조작하는 데 사용되는 기본 데이터 구조이다. Tensorflow와 PyTorch 같은 딥러닝 프레임워크는 훈련과 추론 과정에서 데이터를 효율적으로 계산하고 저장하기 위해 이 텐서를 변형하고 계산하며 처리한다.
텐서의 랭크(Rank)는 텐서가 가진 인덱스의 수를 나타낸다. 단일 수인 스칼라는 랭크 0의 텐서로 간주할 수 있다. 벡터는 인덱스가 하나이므로 랭크 1의 텐서이다. 행렬은 인덱스가 두 개이므로 랭크 2인 텐서이다. 더 높은 등급의 텐서는 더 많은 인덱스를 가지며 더 복잡한 관계를 나타낼 수 있다.
8️⃣ Vocoding
Vocoding은 Voice와 Encoding의 합성어로 전산적으로 인간의 목소리를 합성해 생성해 내는 과정을 의미한다. 조금 더 자세하게는, 시간에 따른 주파수 세기의 함수인 Spectrogram을 음성 파형(Waveform)을 만든다.
작곡, 신호 처리 등 여러 분야에서 Vocoding이 범용적으로 쓰이지만 이 장에서는 딥러닝에서 활용되는 Vocoder인 Neural Vocoder에 대해 알아본다.
⚰︎ TTS(Text-to-Speech)는
- 글을 입력으로 받아 특정 Spectrogram 형태로 Representation을 만든 뒤 다시 이 Spectrogram을 입력으로 받아 원본 음성(Wav)을 예측해 내는 일련의 과정이다.
- Spectrogram을 바탕으로 원본 음성을 만들어 내는 기술이 바로
Neural Vocoding이다. - Spectrogram을 가지고 원본 음성을 합성해 내는 Vocoding은 그 방식에 따라 세 가지로 구분할 수 있는데
the Griffin-Lim Vocoder와 같은 신호처리적 접근부터MelGAN과 같은 비자기회귀 모델(Non Autoregressive Model)까지 다양한 종류가 있다.
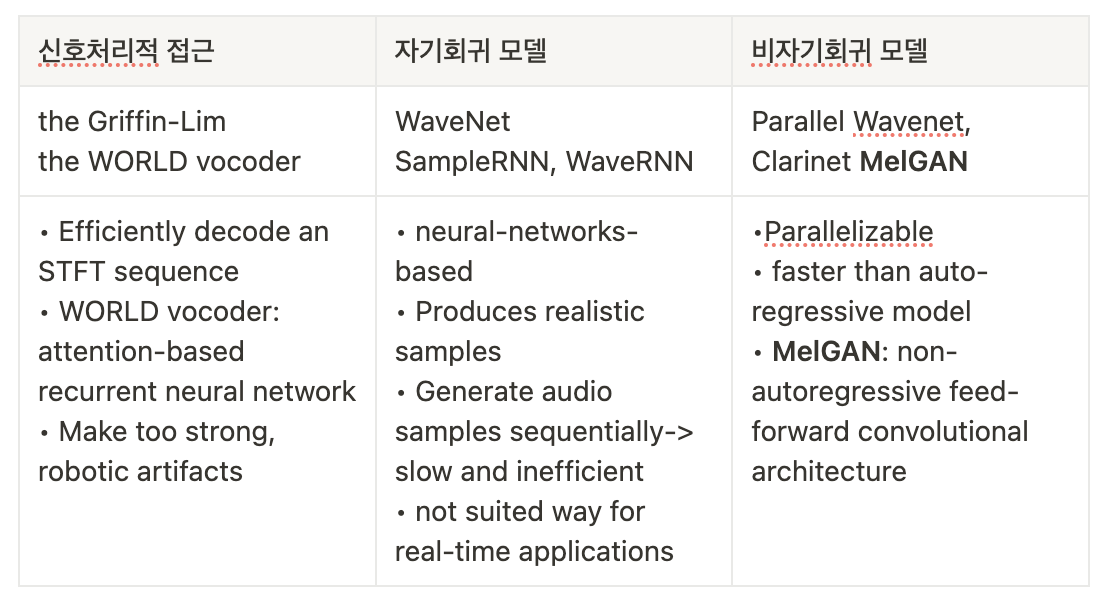
Neural Vocoder의 발전으로 오디오 딥러닝의 여러 영역에서 Neural Vocoder를 활용하는 경우가 많아졌는데, TTS나 Speech Synthesis 등 이미 Neural Vocoder의 적용도가 높은 분야 이외에도 Speech Recognition 등의 분야에서도 활용된다.
[출처 | 딥다이브 Code.zip 매거진]
