딥러닝에서 활성화 함수(Activation Function) 란, 모델이 복잡한 비선형 관계를 학습할 수 있도록 하기 위해 사용 하는 함수이다.
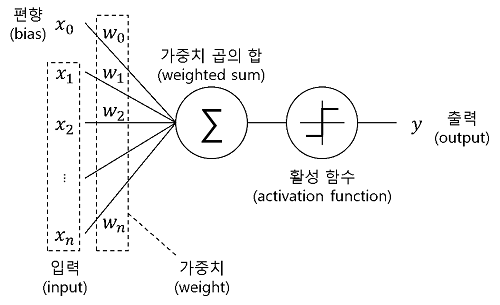
그림처럼 입력으로 들어온 데이터를 활성 함수를 거쳐서 출력을 하게 되는 흐름을 가진다.
그 종류로는 시그모이드, 하이퍼볼릭 탄젠트, ReLU(Rectified Linear Unit)와 그 변형들이 널리 사용되고 있다.
활성화 함수의 종류와 활용에 대해서 더 자세히 알아보자
🏹 활성화 함수
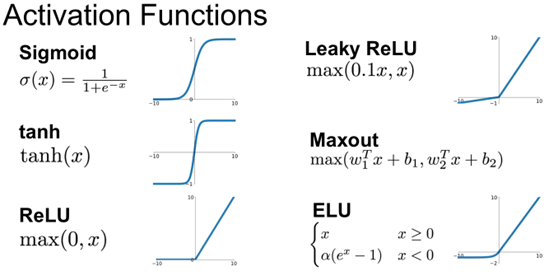
🔗 비선형성
- 활성화 함수는
인공신경망(ANN)에서 입력신호의 가중치 합을 변환해서 출력 신호로 생성하는 함수이다. - 활성화 함수는 신경망에
비선형성(Non-Linearity)을 추가하기 위해 활용된다. - 활성화 함수 덕분에 신경망이 데이터 내의 복잡한 패턴을 파악하고 표현할 수 있다.
- 선형적인 세계에서는 아무리 복잡한 값을 갖는 함수들을 합성하더라도, 그 차원을 벗어나지 못한다.
- 비선형성을 추가하게 되면 공간 자체를 왜곡 가능 하다
📂 ReLU
🔗 ReLU 개념
ReLU(Rectified Linear Unit) 함수는 입력이 0보다 크면 입력을 그대로 출력하고, 입력이 0보다 작으면 0을 출력합니다. ReLU 함수는 기울기가 항상 양수이기 때문에 학습이 빠르다는 장점이 있습니다.
*Rectified: 바로 잡은
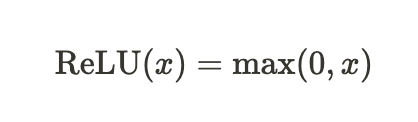
# 파이썬 내장함수로 구현한 ReLU
def relu(x):
return max(x, 0)
# PyTorch로 구현한 ReLU
import torch
def relu(x):
return torch.max(x, torch.zeros_like(x))- 음수일때의 0이하의 뉴런을 버리고, 양수의 뉴런만을 활성화 시킴
- 이로 인해 출력값이 희소(Sparse)해지고, 일부 뉴런만이 활성화
- 이는 더 적은 파라미터와 계산으로 효과적인 모델을 구축할 수 있게 하지만, 많이 버림
한계 극복을 위해
Leaky ReLU,Parametric ReLU등 변환된 ReLU 함수 활용
🔗 ReLU 코드 예제
(1) 가상의 입력 데이터 정의
import torch.nn as nn
import matplotlib.pyplot as plt
# 입력 데이터 정의
input_data = torch.tensor([-3.0, -2.0, -1.0, 0.0, 1.0, 2.0, 3.0])
# ReLU 활성화 함수 정의
relu = nn.ReLU()
# 입력 데이터에 ReLU 적용 -> output_data로
output_data = relu(input_data)
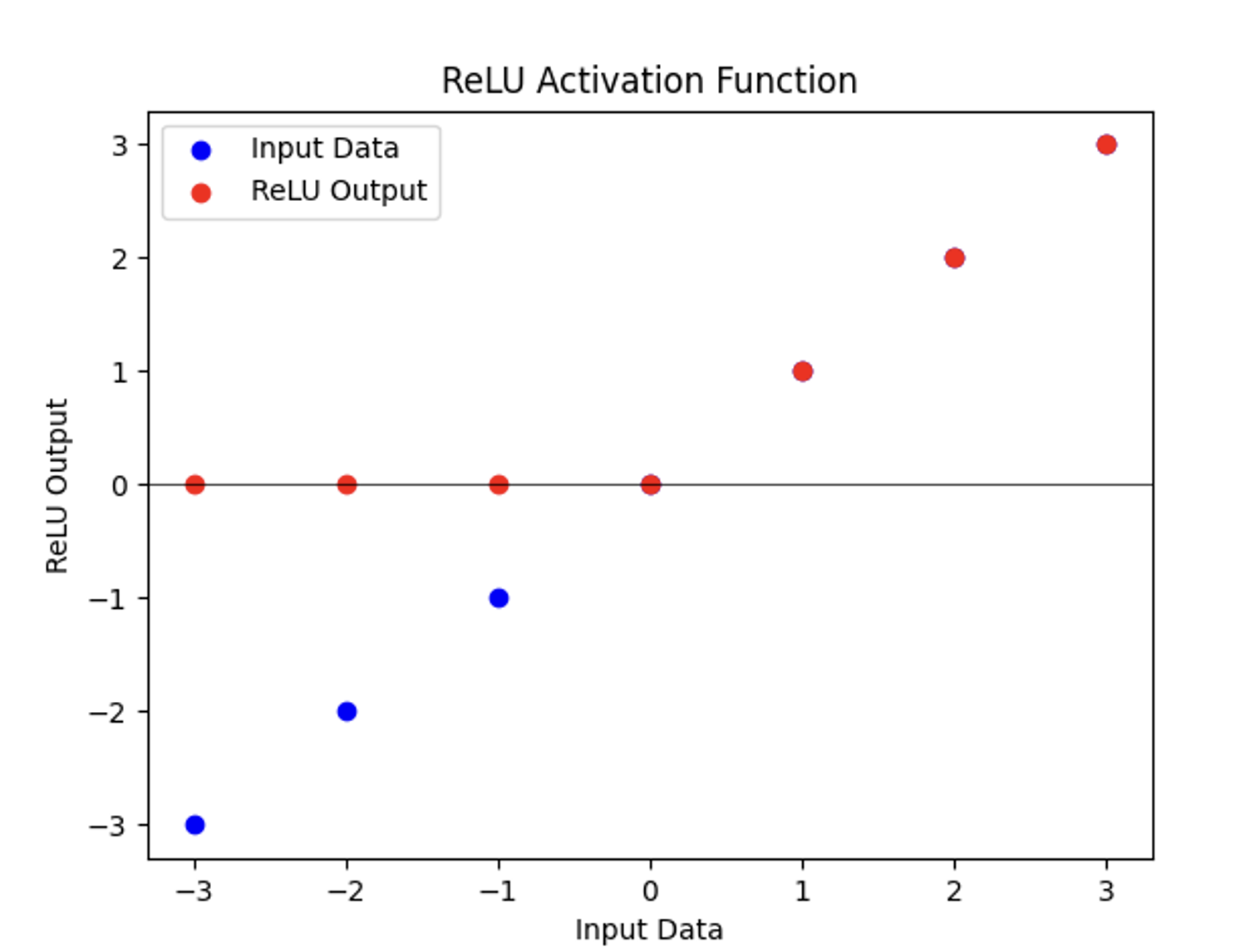
(2) ReLU 시각화
# 입력 데이터와 ReLU 출력 플롯
plt.scatter(input_data.numpy(), input_data.numpy(), color='blue', label='Input Data')
plt.scatter(input_data.numpy(), output_data.numpy(), color='red', label='ReLU Output')
plt.axhline(0, color='black', linewidth=0.5) # y=0에 수평선 추가 (참고용)
plt.xlabel('Input Data')
plt.ylabel('ReLU Output')
plt.legend()
plt.title('ReLU Activation Function')
plt.show()
📂 Sigmoid
🔗 Sigmoid 개념
- 이진 분류에서 사용되는 활성화 함수
- 입력받은 값은 0과 1사이의 값으로 출력
- 입력받은 값이 무한대로 커질수록 출력값은 1에 가까워짐 (0~1)
- 이진 분류에서 사용되는 중요한 활성화 함수
- 입력 받은 값이 클래스 1일 확률을 계산하는데 사용
# 넘파이(Numpy)로 구현한 Sigmoid
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))# PyTorch로 구현한 Sigmoid
import torch
def sigmoid(x):
return 1 / (1 + torch.exp(-x))🔗 Sigmoid 코드 예제: 비만 여부 예측
- 가상의 height와 weight를 생성하여, 키와 몸무게로 비만 여부를 예측하는 모델 만들기
- 가중치를 학습을 통해 이미 계산하였고, 반올림하여 나타냄
(1) 가상의 데이터 생성
- 비만 여부 예측 예제
# 예제: 비만 여부 예측
# 입력 특성
height = np.array([160, 172, 155, 168, 180]) # 키 (단위: cm)
weight = np.array([58, 63, 52, 70, 85]) # 몸무게 (단위: kg)
# 이진 레이블
labels = np.array([0, 0, 0, 1, 1]) # 0: 정상, 1: 비만
# 가중치와 편향
weights = np.array([-0.7, 1.7]) # 키와 몸무게에 대한 가중치
bias = 0.65 # 편향 항
# 가중합 계산
weighted_sum = np.dot(np.column_stack((height, weight)), weights) + bias
# 시그모이드 함수를 적용하여 예측 확률 계산
predicted_probs = sigmoid(weighted_sum)가중합 계산 코드
- np.column_stack((height, weight))
-> 키와 몸무게를 열로 쌓아 2차원 배열을 만듦- np.dot 함수
->이 배열과가중치 배열 weights를 곱하고, 편향 bias를 더하여 가중합을 계산
(2) Sigmoid 함수 그래프 시각화
import torch.nn as nn
import matplotlib.pyplot as plt
# 입력 데이터 정의
input_data = torch.tensor([-3.0, -2.0, -1.0, 0.0, 1.0, 2.0, 3.0])
# ReLU 활성화 함수 정의
relu = nn.ReLU()
# 입력 데이터에 ReLU 적용 -> output_data로
output_data = relu(input_data)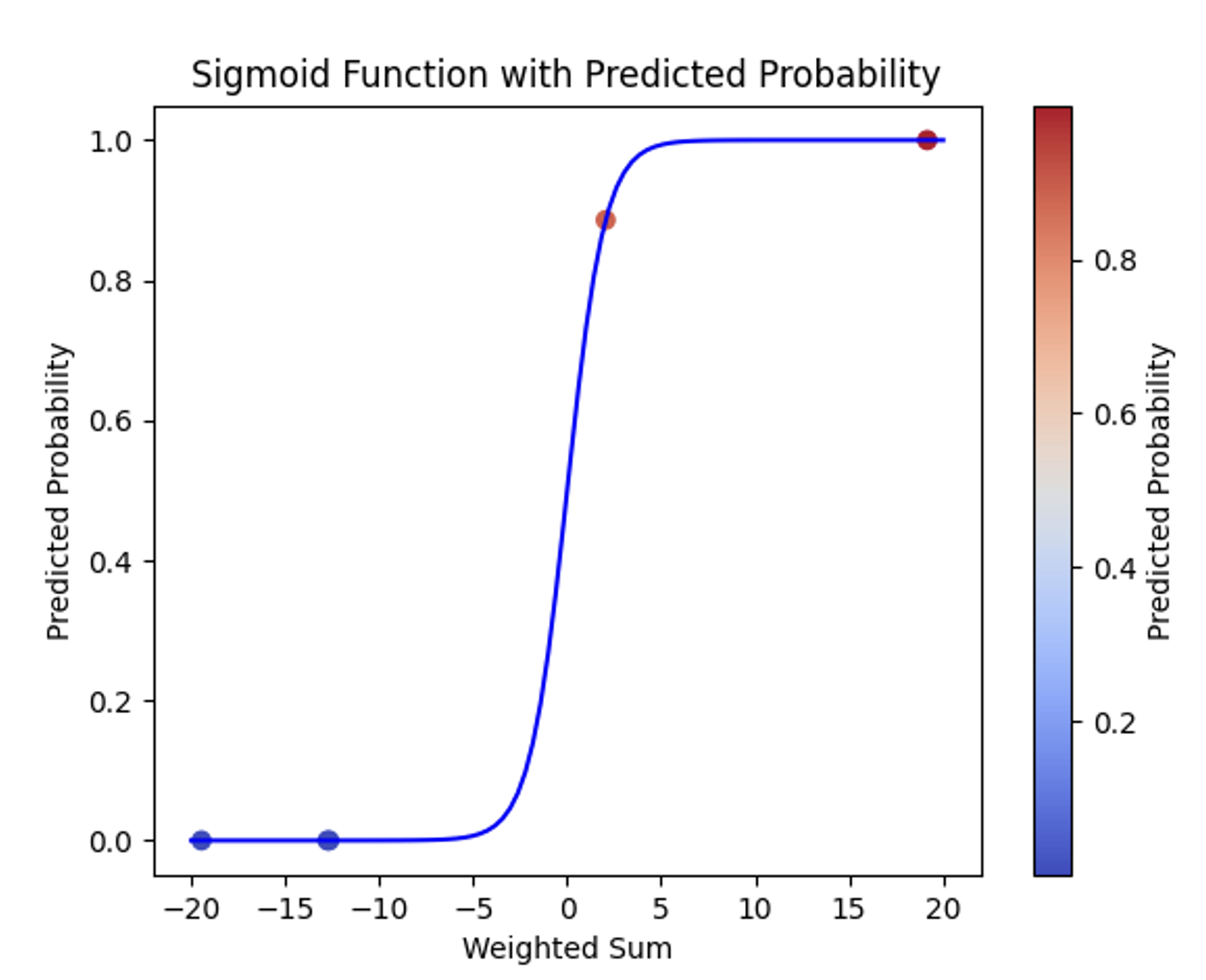
➡️ 출력값이 0.5보다 크면 비만으로, 0.5보다 작으면 비만이 아닌 것으로 분류
📂 Softmax
🔗 Softmax 개념
- Softmax 함수는 입력값을 0~1 사이의 값으로 정규화하고, 그 값들의 합이 1이 되도록 하는 함수
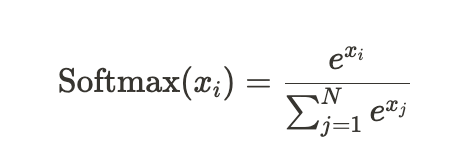
-
수식에서, 지수함수(e^x, Exponential Function)를 무시하고 보면 여러 값들의 합 중에 하나의 값이 차지하는 비율을 의미함
➡️ 전체값 중에서
x_i가 갖는 확률값을 의미
- softmax 함수는 신경망 모델이 마지막 단계에서 출력한 값을 확률값으로 계산할 때 주로 사용
softmax 함수는
다중분류문제에서 각 클래스가 정답일 확률을 추정하는데 주로 사용
🪻 Numpy로 구현한 Softmax
# 넘파이(Numpy)로 구현한 Softmax
import numpy as np
def softmax(x):
exp = np.exp(x)
sum_exp = np.sum(exp)
return exp / sum_exp
🪻 Pytorch로 구현한 Softmax
# PyTorch로 구현한 Softmax
import torch
def softmax(x):
"""
입력 텐서에 소프트맥스 함수를 계산합니다.
입력:
x: (batch_size, num_classes) 형식의 텐서
출력:
(batch_size, num_classes) 형식의 소프트맥스 확률을 담은 텐서
"""
x = x - x.max()
exp_x = torch.exp(x)
return exp_x / exp_x.sum(dim = 1, keepdim = True)
🤔 .sum() 에 dim = 1, keepdim = True를 할당한 이유
(1) 랜덤한 값을 갖는 4x4 크기의 2차원 텐서를 생성
a = torch.randn(4, 4)
>>> a
tensor([[ 0.0569, -0.2475, 0.0737, -0.3429],
[-0.2993, 0.9138, 0.9337, -1.6864],
[ 0.1132, 0.7892, -0.1003, 0.5688],
[ 0.3637, -0.9906, -0.4752, -1.5197]])
(2) torch.sum() 함수를 통해 텐서 값들을 더할 수 있음
dim = 1의 2차원 값들끼리 더하라는 의미 (= 리스트 안에 있는 리스트를 기준으로 더함)dim = 0으로 설정한다면, 1차원을 기준으로 더함 (= 같은 열끼리 더하기)- 차원을 지정하지 않으면, 텐서 내 모든 값을 더하게 된다.
>>> torch.sum(a, dim = 1)
tensor([-0.4598, -0.1381, 1.3708, -2.6217])(3) keepdim = True 는 처음에 생성했던 차원을 유지하고 싶을 때 설정
>>> torch.sum(a, 1, keepdim=True)
tensor([[-0.4598],
[-0.1381],
[1.3708],
[-2.6217]])🔗 Softmax 코드 예제
- Softmax는 분류에서 자주 활용되기 때문에, 손실함수인
nn.CrossEntropy()에 포함되어 있음 - Softmax만 단독으로 활용하는 경우는 많지 않음
로짓 텐서 (Logit Tensor)
- 로짓텐서 -> 일반적으로
다중 클래스 분류 문제에서 사용되는 용어- 각 클래스에 속할 확률을 변환하기 전의 값
- 로짓은 소프트맥스 함수를 통과하기 전의 출력값임
import torch.nn.functional as F
# 임의의 로짓 텐서
logits = torch.tensor([[2.0, 1.0, 0.1],
[0.5, 2.0, 1.0],
[0.2, 1.0, 3.0]])
# 소프트맥스 활성화 함수 적용
probabilities1 = softmax(logits)
probabilities2 = F.softmax(logits, dim=1)
# 확률 출력
print('직접 정의한 Softmax 확률값:\n', probabilities1)
print('PyTorch Softmax 확률값:\n', probabilities2)
>>>
직접 정의한 Softmax 확률값:
tensor([[0.6590, 0.2424, 0.0986],
[0.1402, 0.6285, 0.2312],
[0.0508, 0.1131, 0.8360]])
----------------------------------------
PyTorch Softmax 확률값:
tensor([[0.6590, 0.2424, 0.0986],
[0.1402, 0.6285, 0.2312],
[0.0508, 0.1131, 0.8360]])
➡️ 직접 정의한 Softmax 확률값 & PyTorch Softmax 확률값 동일
➡️ Softmax의 출력 결과 내 각 리스트의 합은 1이 되고, 각 확률의 크기 순서(0.6590 > 0.2424 > 0.0986)는 원래 값의 크기 순서(2.0 > 1.0 > 0.1)가 그대로 유지됨을 알 수 있음
➡️ 여러 활성화 함수를 넣어보고 비교하면서 가장 좋은 결괏값을 내는 함수를 선택
[출처 | 딥다이브 Code.zip 매거진]
