오차 역전파 법은 딥러닝에서 학습을 수행하는데 있어 반 필수적인 방법이다.
backpropagation은 가중치 파라미터에 대한 loss function의 기울기를 손쉽게 구할 수 있도록 해준다.
여기까지가 일반적으로 알고있는 사항이다.
그렇지만 여기서 수식적으로 back propagation이 작동한다는 것인지 궁금했고, '손쉽게'란 말을 더 이해하고자 하였다.
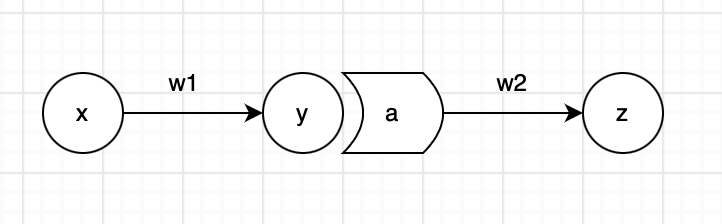
위와 같은 neural net이 있다고 생각해보자.
여기서 activation function은 sigmoid를 사용하였고, loss function은 MSE를 사용하였다.
activation function : sig(x)=1+e−x1
loss function : E=(z−z^)2
여기서 back propagation이 목표하는 바는, 작은 가중치 변화 dw2에 loss function E가 얼마나 민감하게 반응하는 지를 찾아내는 것이다.
Chain rule에 의하여, weight parameter w1,w2에 대한 loss function의 기울기는 다음과 같이 표현할 수 있다.
∂ω2∂E
∂ω1∂E=∂a∂E∂y∂a∂w1∂y
이때 z^=a⋅w2+b2 이므로,
∂a∂E=2(z−w2⋅a)⋅(−w2)
이다. 나머지 도함수도 비슷하게 구할 수 있다.
∂y∂a=sig(y)⋅(1−sig(y))=a⋅(1−a)
∂w1∂y=x
∂w2∂E=2(z−w2⋅a)⋅(−a)
이제 weight parameter w1,w2에 대한 loss function의 기울기를 구했다.
bias에 대한 loss function의 기울기도 마찬가지의 방식으로 얻을 수 있다.
이 의미는 loss function에 대한 parameter의 민감성 혹은 중요도를 알 수 있다는 점이며, learning rate 만큼 움직이려는데 각각의 parameter를 어느 정도 움직여야 하는지를 알 수 있다는 것이다.
