
1. 공지사항 & 과제 안내
- Piazza 가입
- 이미 500명 가입, 아직 100명 미가입 → 모든 질문(프로젝트, 중간고사 등)은 Piazza에서 할 것
- SCPD 학생은
@stanford.edu이메일 받아야 가입 가능
- 과제 1
- 오늘 오후 중 업로드 예정(작년 버전도 유사)
- 구현 내용:
- k-NN
- 선형 분류기: SVM, Softmax, 2-layer 신경망
- 툴: Python + NumPy (vectorized 연산 중요 → 튜토리얼 필독)
- Google Cloud 지원
- GPU 포함 VM 사용 가능
- 무료 크레딧 쿠폰 배포 예정 → 과제·프로젝트에 활용
2. k-Nearest Neighbors (k-NN)
- Data-Driven Approach
- 명시적 규칙 대신 데이터 수집 → ML 모델 학습(
train(images, labels) → model,predict(model, image) → label)
- 명시적 규칙 대신 데이터 수집 → ML 모델 학습(
- Algorithm
- Train: 학습 데이터를 저장만 함 (O(1))
- Predict: 테스트할 새로운 이미지와 모든 학습 샘플 간 거리 계산 → 최솟값 K개 선택 → 다수결 투표
(Train 데이터에서 해당 새로운 이미지와 가장 유사한 이미지를 찾아 레이블을 예측하는 과정)
- 거리 척도(Distance Metrics)
- L1 (Manhattan): 픽셀 차이 절댓값 합
- L2 (Euclidean): 제곱합의 제곱근
- 시각화:
- L1 기준 이웃 영역은 축에 정렬된 다이아몬드 모양, L2는 원형
- 선택 기준:
- 특징 벡터 요소가 독립적 의미를 가질 때(L1) vs. 일반적 벡터(L2)
- CIFAR-10 예제
- 10개 클래스, 50,000개 학습 이미지 + 10,000개 테스트 이미지 (32×32×3)

- k=1,3,5 에 따른 결정 경계 시각화 → k가 커질수록 노이즈에 강하고 부드러운 경계
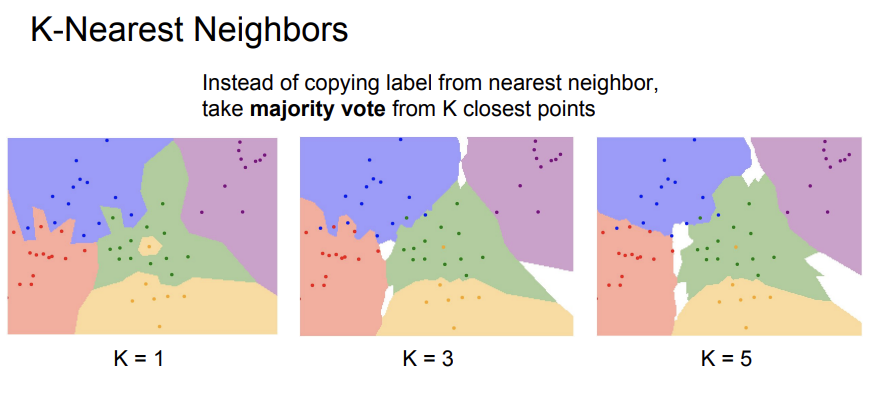
- 10개 클래스, 50,000개 학습 이미지 + 10,000개 테스트 이미지 (32×32×3)
- 단점
- Test Time 느림: 모든 샘플과 비교해야 함
- 지각적 유사성 미반영: L1/L2는 픽셀 단위, 고수준 의미 반영 안 됨
- 차원의 저주: 고차원일수록 공간을 조밀히 덮기 위한 샘플 수가 기하급수적 증가
- 이후 CNN과 다른 신경망: 반대의 현상 - 훈련 시에는 많은 시간을 소모하지만, 테스트 시에는 상당히 빠른 속도를 보임
- 코드

Numpy의 vectorized operations을 활용하면 구현은Pythoncode 한 두 줄이면 충분함- Train: 이미지-레이블을 학습
- Predict: 새로운 이미지를 입력받아 L1 거리 함수를 사용하여 학습 이미지 간의 거리를 계산하여 학습 이미지에서 가장 유사한 이미지를 찾아 레이블을 예측
- 첫번째 과제에서 수행하게 될 내용
3. 하이퍼파라미터 튜닝 & 모델 셀렉션
- 하이퍼파라미터: k, 거리 척도 등
- BAD way
- 학습 데이터 정확도 최대화 → K=1 (과적합)
- 학습/테스트 셋만 둘로 나누고 테스트 성능 기준 선택 (테스트 오염)
- BETTER way
- Train / Validation / Test 분할
- Train: 모델 학습
- Validation: 다양한 하이퍼파라미터 평가 → 최적값 선택
- Test: “한 번만” 최종 성능 측정
- Cross-Validation
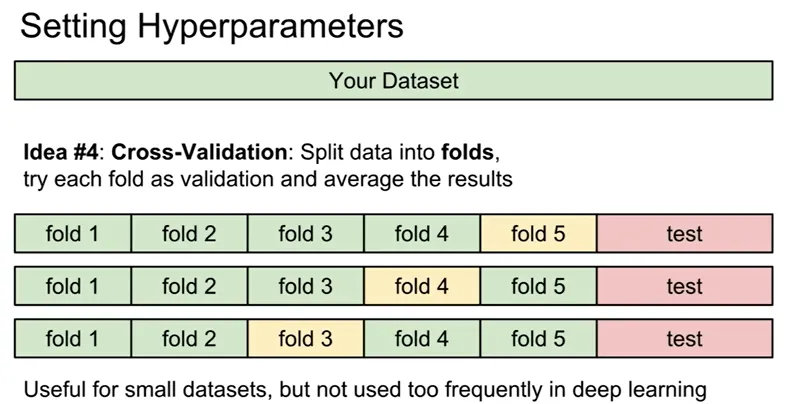
- 작은 데이터셋에 5-fold CV 등 활용 (대규모 딥러닝에는 취약)
- Fold별 성능 분산까지 고려해 안정적인 하이퍼파라미터 결정
- Train / Validation / Test 분할
- i.i.d 가정 및 데이터 분할 주의
- 데이터 수집 순서에 따라 훈련/테스트 분할 시 분포 불일치
- 전체 섞은 뒤 무작위 분할 권장
4. 선형 분류기 (Linear Classification)
4.1 개념 & 수식
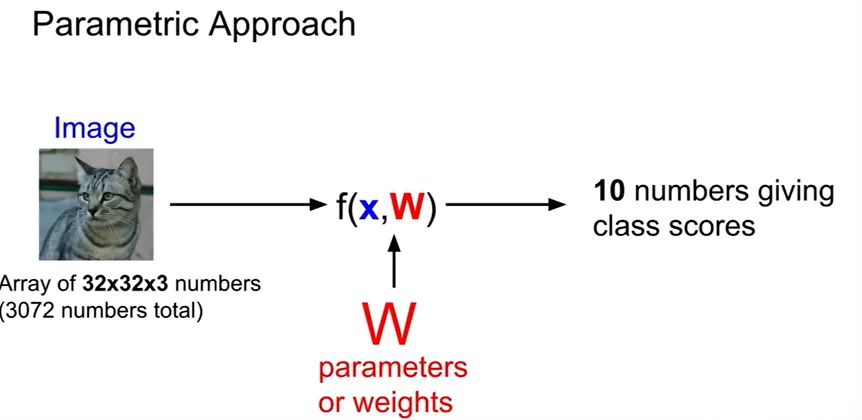
- Parametric Model: 데이터 요약 → 파라미터 (plus bias )
- 모델:

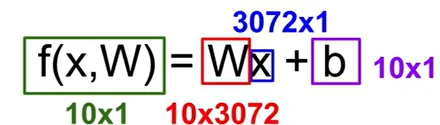
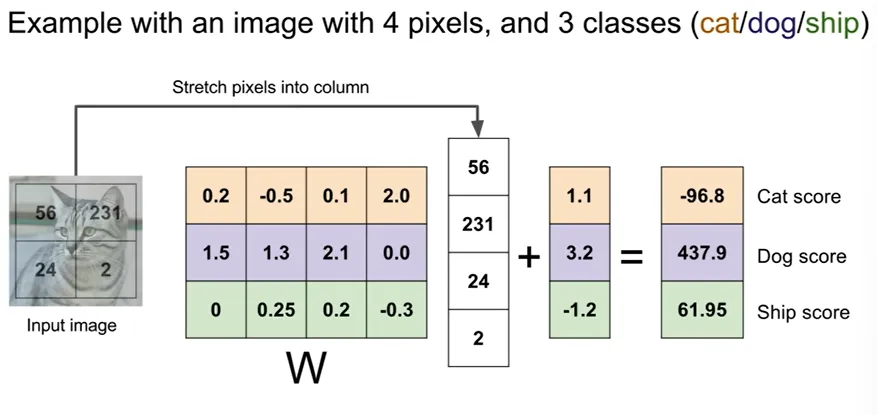
- Interpretation:
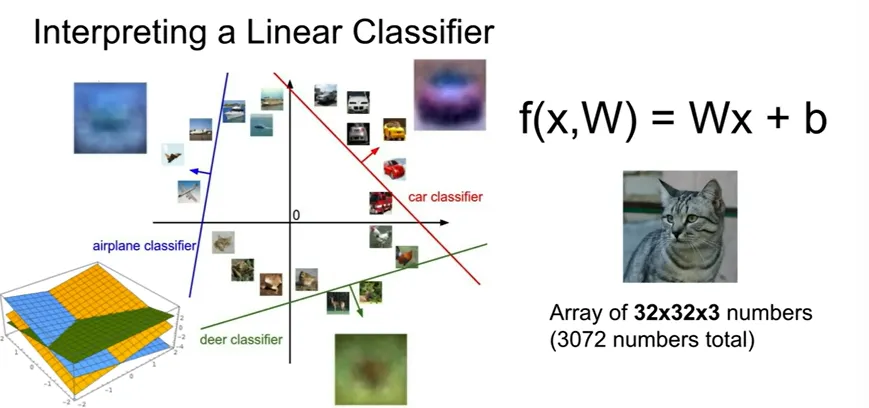

4.2 시각화 예시

- CIFAR-10 학습 후 얻은 각 행을 이미지로 재배열
- “비행기” 템플릿: 푸른 배경 + 중앙 물체 형태
- “자동차” 템플릿: 붉은 중앙 + 푸른 상단(유리)
- “말” 템플릿: 머리가 두 개 → 클래스 내 다양한 모양 평균화 문제
4.3 장·단점
- 장점:
- Test Time에 만 필요 → 경량·고속
- 해석 용이 (템플릿 매칭, 결정 경계)
- 단점:
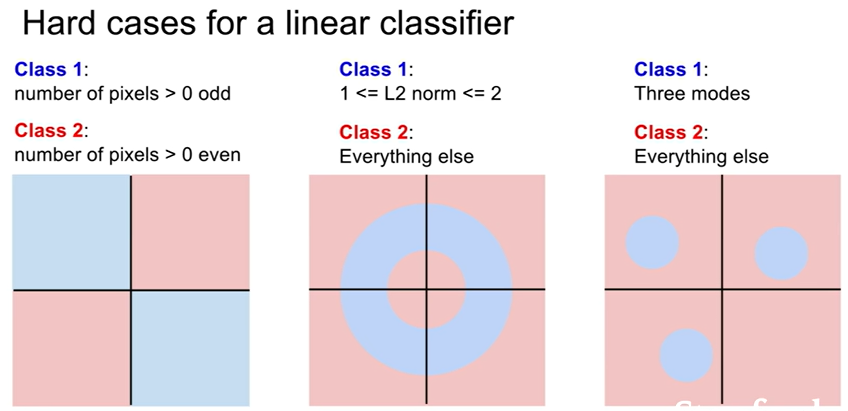
- Parity Problem(역전성): 홀/짝 분류처럼 선형 분리 불가능
- Multimodal Data: 하나의 클래스가 여러 영역(“섬”)에 분포 → 단일 선형 경계로는 구분 불가
- 클래스당 하나 템플릿 → 클래스 내부 다양성 반영 한계
5. 다음 강의 예고
- Loss Function: 적절한 학습을 위한 비용 함수 정의
- Optimization: 경사 하강법 등
- ConvNet: CNN 구조 및 학습
Reference
-
Lecture 2 | Image Classification
➡️ 해당 강의 영상으로, 위 내용과 함께 정리하시면 이해에 도움이 되실 것 같습니다 -
CS231N_17_KOR_SUB/kor/Lecture 2 Image Classification.ko.srt at master · visionNoob/CS231N_17_KOR_SUB
➡️ 해당 강의 영상의 한국어 스크립트입니다

🌻