
머신러닝 모델은 데이터를 통해 직접 학습한다. 그렇기 때문에 예측력 있는 데이터는 머신러닝 모델 훈련에 필수적이다. 이 절에서는 데이터 엔지니어링과 피처 엔지니어링이라는 두 가지 필수 프로세스를 사용하여 어떻게 고품질의 데이터를 모델에 입력할 것인지 살펴볼 예정이다. 각 프로세스의 중요한 측면을 다룰 것이다.
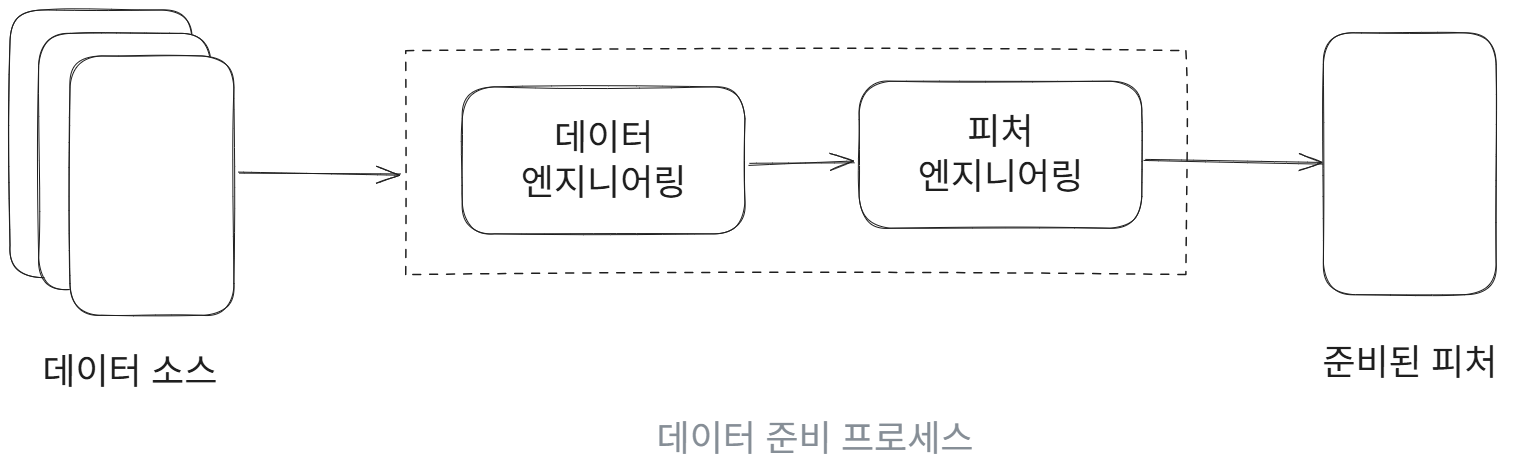
데이터 엔지니어링
데이터의 수집, 저장, 검색 및 처리를 위한 파이프라인을 설계하고 구축하는 작업이다.
데이터 엔지니어링 기본 사항
- 데이터 소스
- 데이터 저장소
- ETL(추출, 변환 및 적재)
- 데이터 유형
- 데이터 소스 : 다양한 소스의 데이터를 사용한다. 데이터 수집은 누가 하나? 데이터가 얼마나 깨끗한가? 데이터 소스를 신뢰할 수 있나? 사용자가 생성한 데이터인가 아니면 시스템이 생성한 것인가? (예: 데이터베이스, 로그, 플랫 파일)
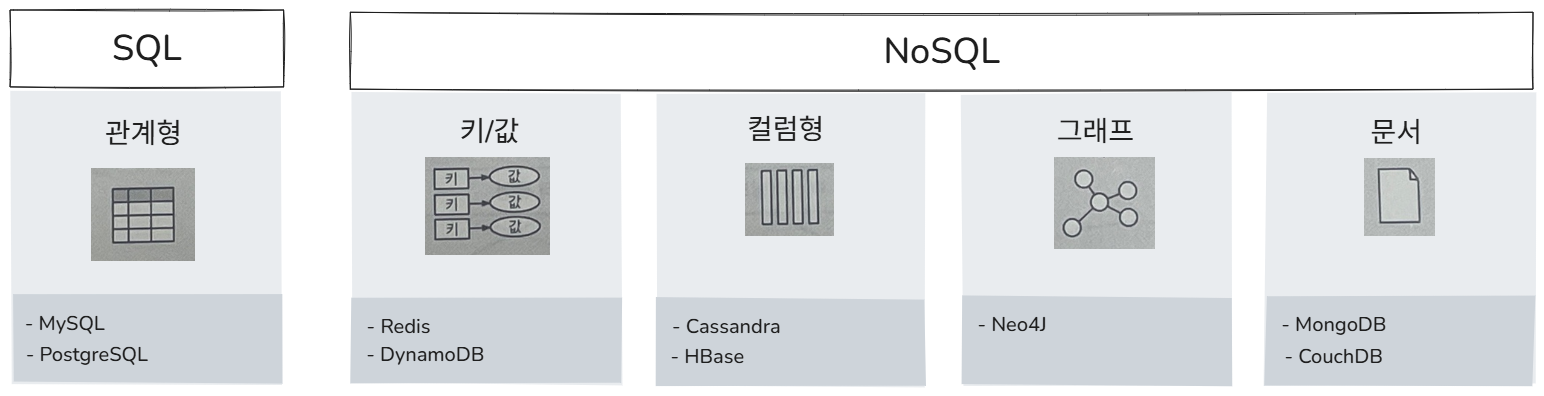
- 데이터 저장소 : 데이터를 상시로 저장하고 관리하기 위한 데이터베이스이다. 사용 사례별로 서로 다른 데이터베이스가 구축되므로 각 데이터베이스가 작동하는 방식을 높은 수준에서 이해하는 것이 중요하다. 일반적으로 머신러닝 시스템 설계 면접 중에 데이터베이스 내부에 대한 상세 질문은 나오지 않는다.
- ETL(추출, 변환 및 적재) : 추출 -> 변환 -> 적재
추출: 다양한 데이터 소스에서 데이터를 추출한다.
변환: 이 단계에서 요구사항에 맞게 데이터 정제, 매핑 및 특정 형식으로 변환한다.
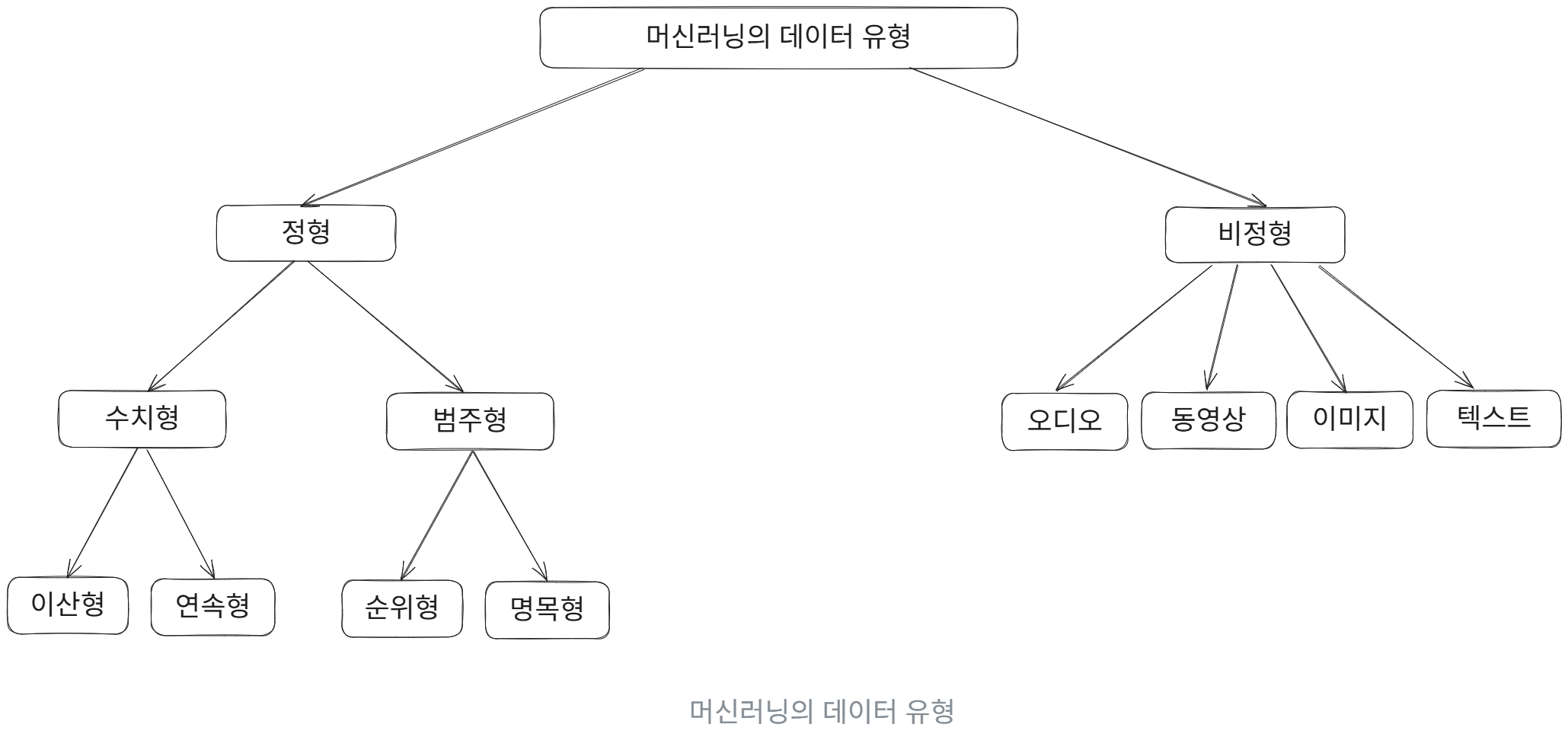
적재: 변환된 데이터를 타깃 저장소(파일, 데이터베이스 또는 데이터 웨어하우스)에 적재한다. - 데이터 유형 : 크게 정형 데이터와 비정형 데이터 두 가지로 나뉜다.
피처 엔지니어링
두 가지 프로세스
- 도메인 지식을 사용하여 원시 데이터(raw data)에서 예상 피처를 선택하고 추출
- 예측한 피처를 모델에서 사용할 수 있는 형식으로 변환
머신러닝 모델을 개발하거나 학습시킬 때 중요한 결정 중 하나는 적절한 피처를 선택하는 것이다. 가장 가치 있는 피처를 선택하는 것이 필수적이다. 이 피처 엔지니어링 프로세스에는 주제별 전문 지식이 필요하고 진행 중인 작업에 따라 결과가 많이 달라질 수 있다. 피처를 예측하여 선택한 후에는 다음에 살펴볼 피처 엔지니어링 작업을 통해 적절한 형식으로 변환해야 한다.
- 피처 엔지니어링 작업
- 피처 스케일링
- 이산화(버키팅)
- 범주형 피처 인코딩
- 피처 엔지니어링 작업 : 누락데이터 처리(삭제, 대체), 왜곡된 분포가 있는 값 조정, 범주형 피처 인코딩
- 피처 스케일링 : 정규화, 표준화, 로그 스케일링
- 이산화(버키팅) : 연속형 피처를 범주형 피처로 변환하는 프로세스이다. 이렇게 하면 모델이 무한한 수의 가능성을 학습하는 대신 몇 가지 범주만 학습하는 데 집중할 수 있다.
- 범주형 피처 인코딩 : 정수 인코딩, 원-핫 인코딩, 임베딩 학습
실습
Kaggle 대회 링크 : 데이터 전처리에 집중한 자전거 수요예측하기 (for beginner)

🌻