CRAFT 논문은 ?
- 2019년 CLOVA AI에서 발표한 Text Detection 모형
- 개별 문자 단위의 약한 지도학습(Character-level weakly supervised learning)을 적용
- 기존 Text Detection의 한계점을 새로운 학습방법을 통해 극복 시도
최근 한글 OCR 관련 프로젝트를 진행하게 되어, Text detection 과정에서 활용 가능한 모델을 찾게 되었다. 아래 소개할 CRAFT는 그러던 중 발견하게 된 모델이다. 발표시기는 2019년으로 약 2년 정도 되었지만, 여전히 Text detection 분야에서 높은 성능으로 상위에 랭크되어있고, 무엇보다 CRAFT가 의도하는 새로운 접근 방식에서 좋은 Insight를 많이 배워 자세히 살펴보게 되었다.
- References (official implementation code & paper)
(Github) CRAFT: Character-Region Awareness For Text detection
(Paper) Character-Region Awareness For Text detection (2019)
CRAFT를 발표한 CLOVA AI에서는 Github에서 test가능한 코드를 공개하고 있다. 또한, 논문에서 CRAFT의 Model architecture와 고안한 방법들에 대해 상세히 설명하고 있어, 관심있는 분들은 위 논문을 참조해보시길 바란다. 그 외로 CRAFT에 대해 상세히 리뷰를 남겨주셔서 참고하는데 도움이 되었던 포스트들을 아래 링크에 함께 소개한다. 자세한 모형의 Training 과정에 관심있는 분들은 아래 리뷰들을 참조해보시면 좋을 듯 하다.
이 글에서는:
1. CRAFT에서 소개하는 모형의 특징에 대해 간략히 소개
2. 공개된 코드로 간단한 test 수행하고
3. Test 결과로 생각해볼 부분 정리
1. 개요 Introduction
-
CRAFT model의 목적 : → Scene text detection
-
Scene text detection은, 어떤 시각 데이터 (e.g. image, video clips etc.) 內 문자(text)의 위치를 식별(detection)하고 지역화(localization) 하는 것이 주 목적
-
최근 이 분야에서, 신경망 기반으로 뛰어난 성능을 보여주는 알고리즘들이 많이 등장
→ 하지만, text의 배치가 다양한 형태로 변형(')된 경우, 제한적인 변별력을 보이는 경우 多 -
이런 text detector의 취약점은, 단어-수준(word-level)의 경계 상자(bounding box)를 학습하는, 데이터의 내생적 특징이 큰 원인 중 하나로 작용
-
이에, 해당 모형은 개별 문자-수준(Character-level)의 문자 식별을 통해, 다양한 형태의 문자열에도 높은 변별력을 갖는 방안을 제시
-
CRAFT는, 개별 문자-수준의 지도학습을 위해 크게 아래와 같이 두 가지 방법을 제시
→ 1. 약한-지도 학습 Weakly-supervised learning
→ 2. 지역 점수와 친밀도 점수 Region score & Affinity score(')변형된 경우: 다양한 방향성(arbitrarily oriented), 곡선형(curvy), 기형적(deformed) 형태 등.

CRAFT 결과 sample, (https://github.com/clovaai/CRAFT-pytorch)
2. 모델 성능 탐색 Model Performance
2.1 테스트 결과 Test Results
- 주변에서 찍은 사진으로
(아주 간단한)test를 해보고, 특징 탐색 - Test : 주변에 보이는 다양한 text 구조를 찍은 3가지 Image로 모형에 적합

(사진 1.) 직선 방향의 문자 영역 사례

- 사진 내 모든 문자열에 대해 Localization 성공
- (*cf. ) [자-동-조-리] vs [데][우] [기]
Region score를 통해서 각 글자 하나씩 detection 성공,
Affinity score에서 차이를 보이며, word chunk를 서로 다르게 인식
(사진 2.) 곡선 방향의 문자 영역과 큰 간격 사례
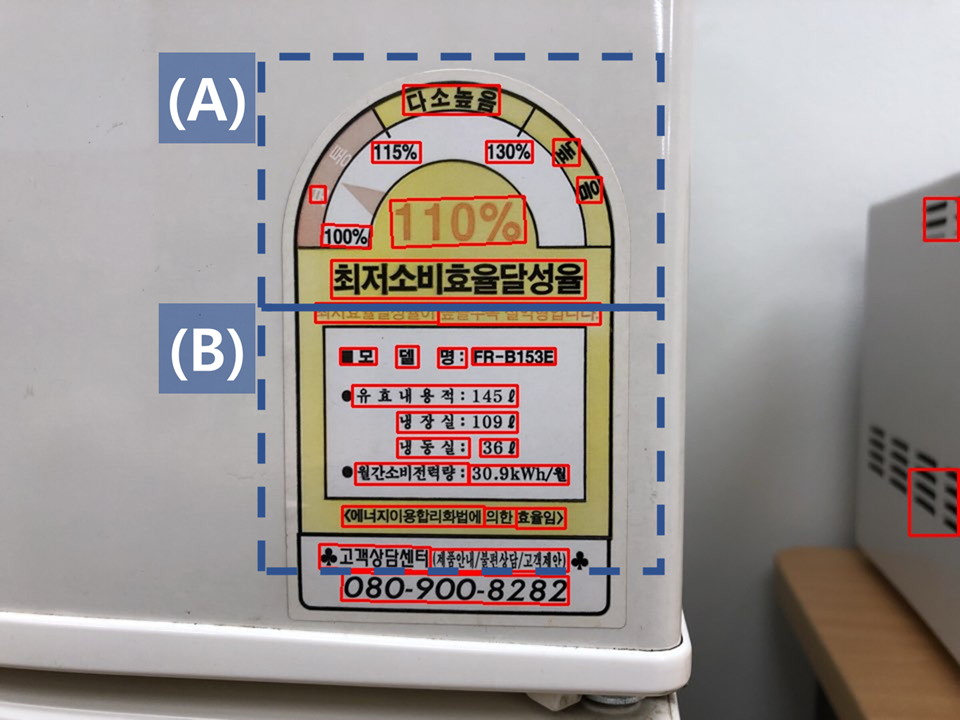
(A) 상단부
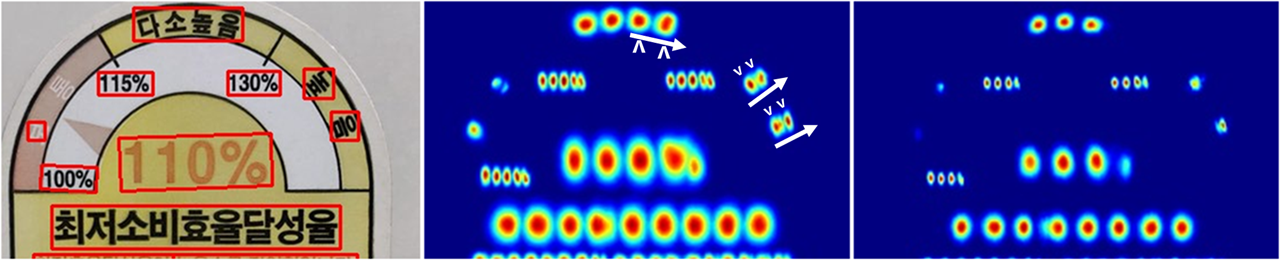
- [높-음]-vs-[높][음]
→ 같은 문자열 "높음"에 대해, 가운데 "다소높음"은 (비교적)정-방향에다가, 글자간 간격이 매우 밀접해서, "높음" 각각 한 글씨로 인식한 것을 볼 수 있고,
→ 그 옆에 눕힌 "높음"은 이와 반대로, 간격도 매우 넓어 (글자 크기보다 간격이 더 크고), 오히려 '각 문자 하나' 안에서 두 문자가 우상향 방향으로 적힌 글씨로 판단한 것을 볼 수 있음.
- [보] - '통'
→ "보통"에서 '통'은 인식이 안된 것도 확인 가능
(B) 하단부

- 문자 크기 대비 자간 크기 → '유효내용적'은 같은 텍스트 박스로 인식 했지만, 위에 '모델명'은 단일 단위로 인식.
(사진 3.) (~)곡선 형태의 문자 영역

- 개별 문자의 크기가 서로 다르고, 복합적인 곡선 방향을 갖는 경우 → 해당 text area를 유연하게 잘 감지하는 것이 확인, 'e', 'g' 와 같이 개별 문자의 크기의 차이가 큰 경우도 개별 문자로 인식하는데 효과적,
2.2 성능 Performances
: CRAFT의 성능 지표
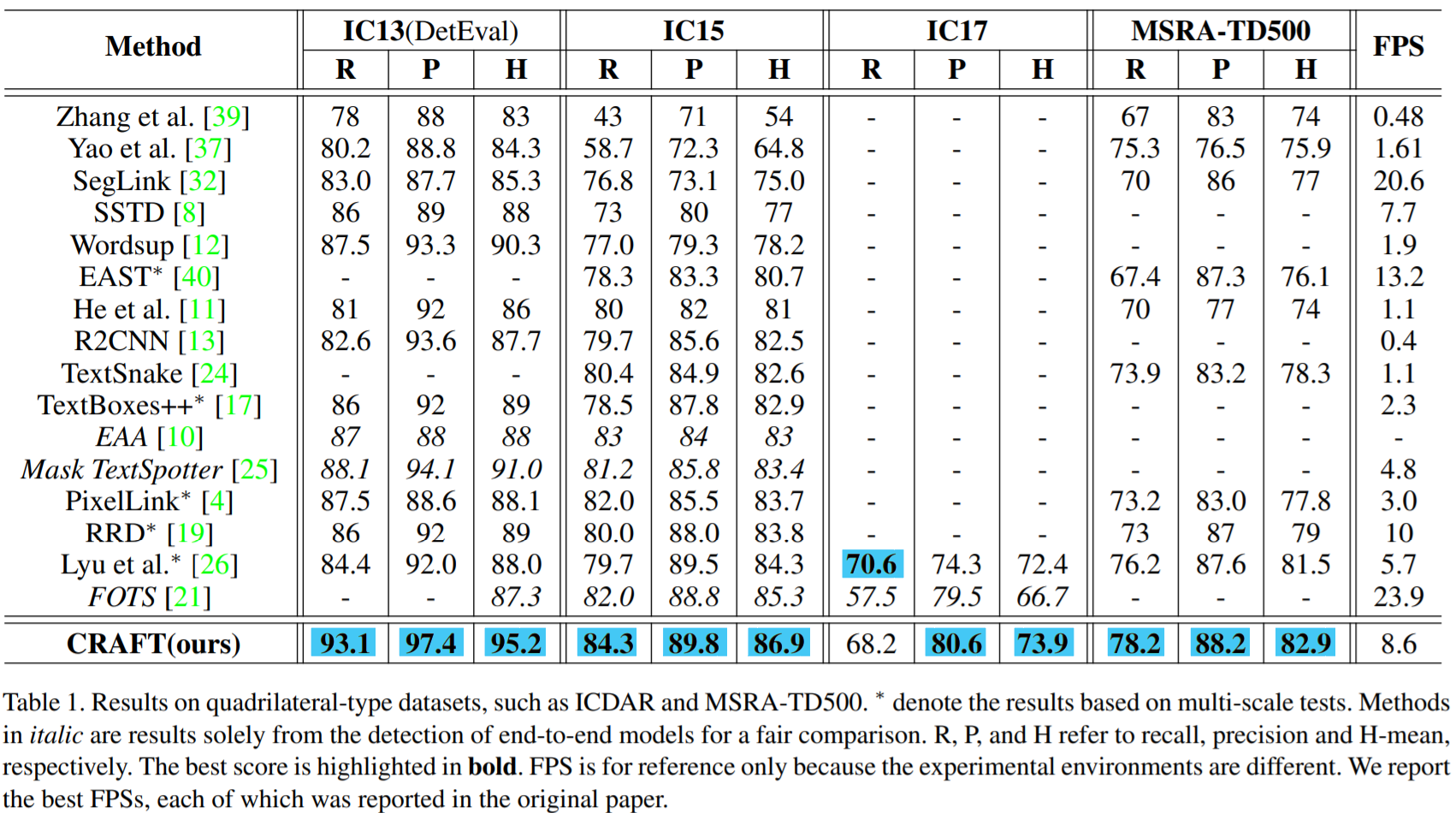
: 발표 당시 (2019), 여러 text detection challenge에서 우수한 성능 기록
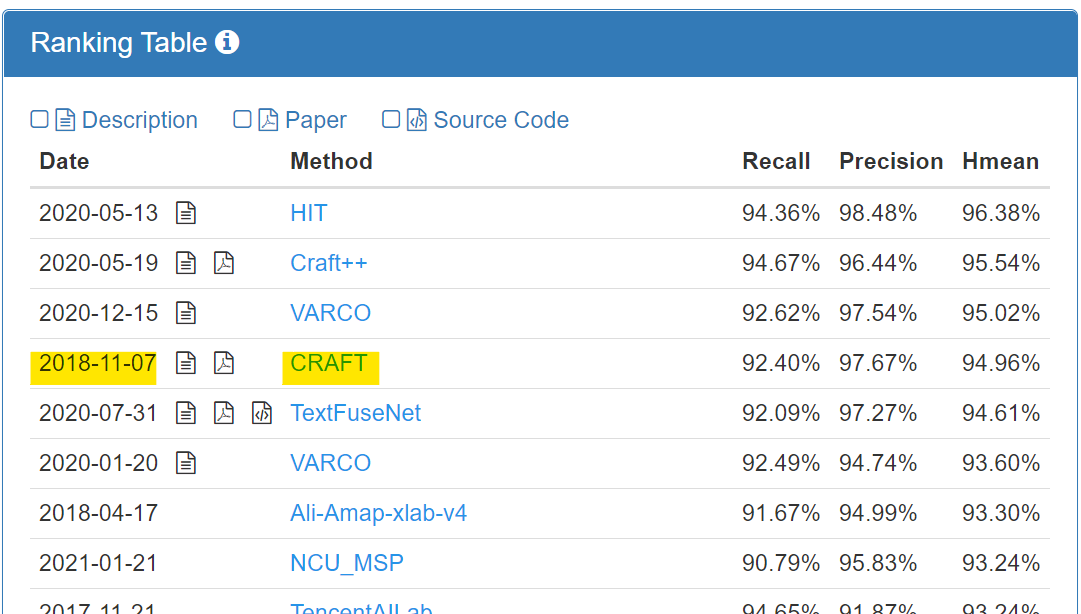
ICDAR2013 Ranking Table 캡쳐 화면. (2021.09.27 기준)
- cf.) Quantitative comparison among the recent text detection methods. (Jun. 2020)
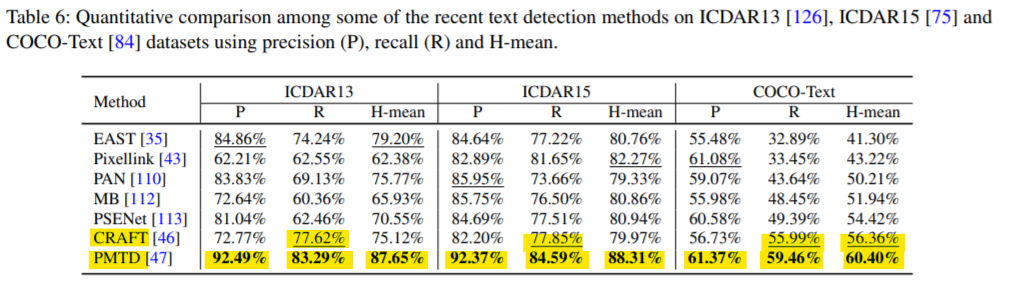 Text Detection and Recognition in the Wild: A Review (Jun. 2020, https://arxiv.org/abs/2006.04305)
Text Detection and Recognition in the Wild: A Review (Jun. 2020, https://arxiv.org/abs/2006.04305)
💡 2020.06 발표된 Text Detection 모형 간 비교 연구에서도, CRAFT는 -
1. 여러 dataset에서 전반적으로 우수한 성능을 기록
→ 편향적이지 않고 일반적인 속성을 추출함에 우수한 평가
3. 구조 Architecture
: CRAFT 모형의 main Architecture
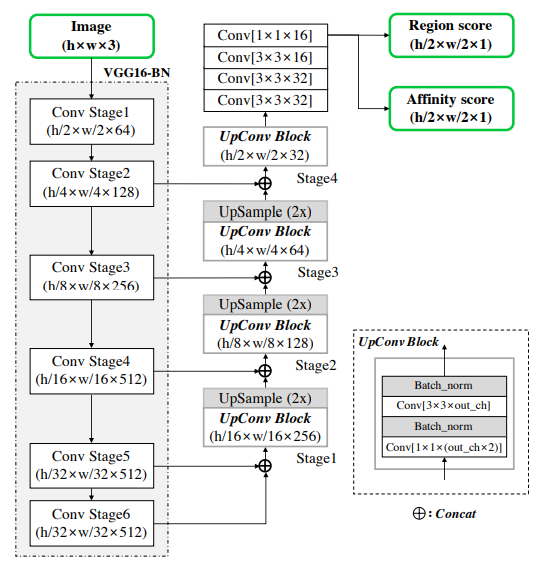
Schematic illustration of CRAFT Y. Baek, Character Region Awareness for Text Detection (2019)
( 참고: Conv Stage6와 Conv(1x1x16) 부분은, 제시된 figure와 약간 다름, 관련 포스트)
CRAFT architecture
| Specification | Detail |
|---|---|
| Main-architecture | U-Net |
| Backbone | VGG-16 |
| Detection-Target | Character, Word, Text |
| Output | 2 Channel, Pixel-wise, Gaussian expression |
→ FCN, U-Net 구조와 유사
→ Batch normalization 적용
→ 2 channel Output : pixel-wise [Region score, affinity score]
Text Detection and Recognition in the Wild: A Review (Jun. 2020, https://arxiv.org/abs/2006.04305)
4. 특징 features
CRAFT에서 제안하는 주요 방법론
Weakly-Supervised Learning + Region score & Affinity score
4.1 약한-지도학습 Weakly-Supervised Learning
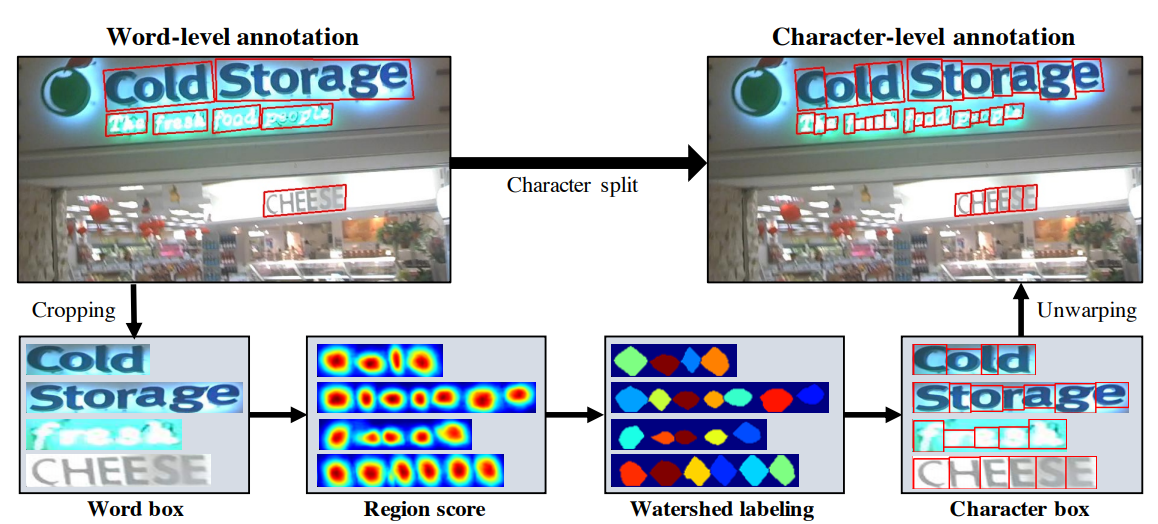
Character split procedure for achieving character-level annotation from word-level annotation: 1) crop the word-level image; 2) predict the region score; 3) apply the watershed algorithm; 4) get the character bounding boxes; 5) unwarp the character bounding boxes.
-
왜 '약한-지도학습' 인가?
→ 개별 문자 단위 annotation을 학습하면, 개별 문자 수준의 Detection이 가능
⇒ 하지만, "개별 문자 단위 annotation은 비용이 많이 든다."
→ '단어 수준' label에서 '문자 수준' label을 추정하는 문제로 바꿔 접근 -
Word-level 대비, character-level 학습의 이점
→ 개별 character 하나 하나를 찾을 수 있다면, 다양한 구조의 text에도 높은 판별력 기대
→ Word-level 경계 상자의 경우, 경계 상자 內 character의 수에 따라 그 크기가 다양한 반면,
Character-level 경계 상자는 상대적으로 균일한 범위 내 직사각형을 유지
⇒ Receptive field가 상대적으로 작아도 general한 특성에 대해 학습이 가능
4.2 지역 점수와 친밀도 점수 Region Score & Affinity Score
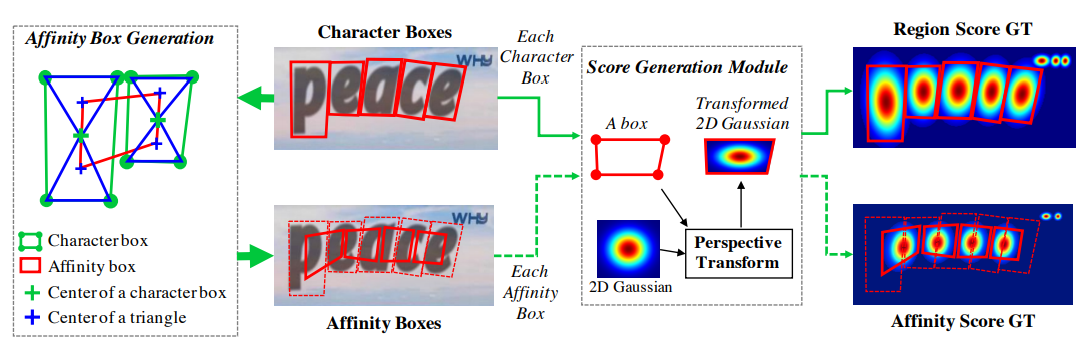
Figure 3. Illustration of ground truth generation procedure in our framework. We generate ground truth labels from a synthetic image that has character level annotations.
-
이 픽셀은 문자Character에 해당하는가? Region score
→ 개별 문자에 대한 경계 상자 예측을 위해, pixel-wise Gaussian 확률 값으로 변환 후 학습
⚠️ binary or categorical value 대신, continuous한 Probability 값을 사용하여 학습 -
바로 옆 문자와 같은 chunk에 해당하는가? Affinity score
→ 개별 문자 수준의 예측 후, 주변 글자들과의 관계를 파악할 수 있는 value가 필요
⇒ 얼마나 인접 문자와 관계가 밀접한가? → 친밀도 점수 Affinity score
5. 시사점 Discussion
이점 Pros
-
규모 편차에 대한 견고함 Robustness to Scale Variance
: 이미지 내 문자 영역(text area)는, 그 크기가 모두 제각각
→ 이미지 크기에 대한 견고성(robustness)이 높았다고 평가
⇒ 이는, word-level처럼, 글자 수에 따라 경계 상자 크기가 제각각인, annotation을 쓰는 대신
한 글자 단위로 학습하는 방법을 사용함으로써, 상대적으로 작은 receptive-field 에서도
판별력(discriminative power)이 높은 모습을 보였다고 평가 -
일반화 능력 Generalizaton ability
: fine-tuning 없이 3가지 다른 Dataset challenge에서 높은 성능 달성
→ 과적합 되기보다, 보다 일반적인 특성을 찾기에 적합한 알고리즘으로 평가
더 생각해볼 부분 Cons
- 다국어 문제 Multi-language issue
: 아랍어 같은 다른 언어 이미지 데이터도 ICDAR2017 에 소수 반영 됨
→ 이런 언어의 문자는, curvy, cursive 한 특징 + 문자의 간격이 균일하지 않은 특징이 있음
⇒ 이런 경우, Character-level annotation 과정의 의사-GT(Pseudo-GT) 제약으로, 쉽게 감지해내지 못한 제약이 제시 됨
