
- 전체보기(28)
- Spring(13)
- Huge Traffic Handling(9)
- SpringAI(7)
- transaction(4)
- Java(4)
- LLM(4)
- redis(4)
- JPA(3)
- DDD(2)
- Backend(2)
- msa(2)
- Springboot(2)
- VectorDB(2)
- springMVC(2)
- write-around(1)
- concurrency(1)
- transactional(1)
- Function Calling(1)
- in-memory(1)
- Transaction Rollback Strategies(1)
- Hexagonal Architecture(1)
- dirty read(1)
- IoC(1)
- LomBok(1)
- Smart Filtering(1)
- Cache Aside(1)
- Self-directed_Study(1)
- phantom read(1)
- summarization(1)
- streaming(1)
- rag(1)
- agent(1)
- social network(1)
- springbean(1)
- React(1)
- @supports(1)
- Sliding Window(1)
- SpringService(1)
- HTTP Session(1)
- LLM Context(1)
- JAX-RS(1)
- PRD(1)
- advisor(1)
- write-through(1)
- spring ai(1)
- mongodb(1)
- Transaction Propagation(1)
- nested(1)
- context(1)
- sns(1)
- Pessimistic Lock(1)
- di(1)
- authorization(1)
- Isolation Test(1)
- chunk(1)
- Multimodal(1)
- Plan-and-Execute(1)
- Simultaneous Control(1)
- web.xml(1)
- Optimistic Lock(1)
- External API(1)
- provider(1)
- required(1)
- consistency(1)
- Transaction Isolation Level(1)
- Wirte-Back(1)
- Multi-Agent(1)
- spring security(1)
- Redis Cache(1)
- Embedding(1)
- HttpSession(1)
- CRUD(1)
- Agentic(1)
- ACID(1)
- mapstruct(1)
- REQUIRES_NEW(1)
- Social Network Project(1)
- ttl(1)
- authentication(1)
- session(1)
- OLLAMA(1)
- SpringContainer(1)
- non-repeatable read(1)
- Session Clustering(1)
- MSA Project(1)
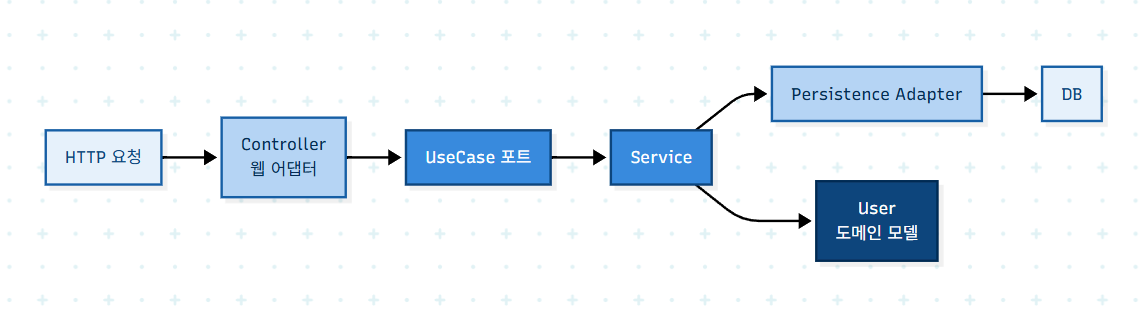
[MSA] DDD패턴을 Hexagonal 폴더에 매핑하기
지난 번에 폴더 구조를 잡았다. 이번엔 그 폴더 안을 실제로 채우기 전에, "어떤 개념이 어디에 들어가는지"를 먼저 정리했다. 코드를 짜다가 "이게 어디 가야 하지?"로 헤매는 시간을 줄이기 위해서다.DDD에는 전략 패턴과 전술 패턴이 있다.전략 패턴은 큰 그림이다.
[MSA] Spring Boot 멀티모듈 골격 잡기
0단계에서 "MSA + 헥사고날 + DDD"로 가기로 했으니, 프로젝트 뼈대를 어떻게 잡을지가 첫 과제였다.결정해야 할 게 생각보다 많았다.Gradle 단일 모듈로 갈지, 멀티모듈로 갈지모듈 이름을 user-service로 할지 user로 할지Spring Initial
MSA로 SNS 처음부터 끝까지 만들어보자!
이 글은 Spring Boot로 SNS 플랫폼을 만들면서 남기는 학습 일지입니다.이런 저런 설계 과정부터 개발, 배포까지 꾸준히 글을 남겨보려고 합니다!경력은 4.X년차인데 솔직히 Spring은 입사 전 포트폴리오를 위해 써본 이후로 거의 사용해 본 적이 없었다. 회사
[JAX-RS/Jersey] @Provider vs web.xml 명시적 등록 비교: 어떤 방식을 선택해야 할까?
최근 동기와 함께 JAX-RS(Jersey) 환경에서 DependencyBinder나 필터(Filter) 등을 등록할 때 어떤 방식이 맞는지 치열하게 고민했다. "간편하게 코드 위에 @Provider 어노테이션 하나만 딱 붙여서 스캔하게 두는 게 맞을까?" "아니면
[Spring] Spring 트랜잭션 롤백 전략과 외부 API 연동
지난 글에서는 트랜잭션 전파 옵션(REQUIRED, REQUIRES_NEW, NESTED 등)을 통해 트랜잭션이 어떻게 전파되고 분리되는지 살펴봤다. 이번 글에서는 한 걸음 더 나아가, 트랜잭션이 실패했을 때 어떻게 처리되는가를 다룬다.이번 글에서 다룰 핵심 질문은 다
[Huge Traffic Handling] 트랜잭션 전파 옵션 — 어디까지를 하나의 작업으로 볼 것인가
지금까지 트랜잭션의 기초(14단계), 격리 수준(15단계), 낙관적/비관적 락(16단계)을 거치면서 트랜잭션이 어떻게 시작되고, 어떻게 서로를 보호하는지 익혔다.이번에는 조금 다른 질문을 다룬다.ServiceA가 ServiceB를 호출할 때, 트랜잭션은 몇 개가 생겨야
[Huge Traffic Handling] 트랜잭션 격리 수준, 코드로 직접 확인해보기
지난 글에서 트랜잭션 격리 수준의 개념을 정리했다. Dirty Read, Non-Repeatable Read, Phantom Read가 각각 어떤 상황에서 발생하는지, 어떤 격리 수준이 이를 막는지 표로 정리했었다.그런데 이론만으로는 뭔가 찜찜하다. 실제로 발생하는지
[Huge Traffic Handling] 낙관적 락과 비관적 락 — 동시성 제어의 두 번째 무기
지난 글에서 트랜잭션 격리 수준으로 동시성 문제를 1차적으로 방어하는 방법을 살펴봤다.그런데 Repeatable Read로 격리 수준을 올려도 여전히 해결되지 않는 문제가 있다.재고가 10개인데 동시에 100명이 주문하면?티켓팅에서 같은 좌석을 동시에 두 명이 선택하면
[Huge Traffic Handling] 트랜잭션 격리 수준 — 동시성과 정합성 사이의 선택
지난 글에서 @Transactional의 동작 원리와 전파 방식을 살펴봤다.트랜잭션이 "하나의 논리적 작업 단위"라는 건 알겠는데, 여러 트랜잭션이 동시에 실행되면 어떤 일이 벌어질까?이번 글에서는 아래 질문들을 다룬다.동시에 100명이 같은 데이터에 접근하면 무슨 일
[Huge Traffic Handling] 트랜잭션과 @Transactional — Spring은 왜 이걸 대신 해주는가
지난 글에서는 Spring AI의 Advisor 패턴과 Function Calling을 다뤘다. 이번 글에서는 잠시 AI 주제에서 벗어나, 백엔드 개발의 가장 기본적인 안전장치 중 하나인 트랜잭션을 짚고 넘어간다.이런 질문들을 생각해보자.트랜잭션이 왜 필요한가?Spri
[Huge Traffic Handling] Redis 영속성과 Spring Security 세션 인증
지난 글에서 Redis가 In-Memory 저장소로서 빠른 속도를 제공하고, 다양한 데이터 타입과 캐싱 전략을 통해 어떻게 시스템 성능을 끌어올리는지 살펴봤다. 그런데 여기서 자연스럽게 의문이 생긴다.Redis는 메모리에 저장하는데, 서버가 꺼지면 데이터는 어떻게 되는
[Huge Traffic Handling] Redis 캐싱 전략 — Cache-Aside부터 Write-back까지
지난 글에서는 Redis의 핵심 데이터 타입을 살펴봤다. String, List, Set, Hash, Sorted Set이 각각 어떤 문제를 해결하는지, 왜 Redis 안에서 직접 처리하는 게 빠른지를 이해했다.이번 글에서는 한 발 더 나아가 Redis를 캐시로 활용하
[Huge Traffic Handling] Redis의 데이터 타입: 왜 String 하나로는 부족한가
지난 글에서는 HTTP Session의 한계와 Redis를 세션 저장소로 활용하는 방법을 살펴봤다. Redis가 세션 관리에 적합한 이유는 In-Memory 저장소 특성상 매 요청마다 조회되는 세션 데이터를 빠르게 처리할 수 있기 때문이었다.이번 글에서는 Redis를
[Huge Traffic Handling] HTTP Session과 Session Clustering
지금까지 Spring MVC 흐름, JPA, 트랜잭션을 공부하면서 서버가 요청을 처리하는 방식을 살펴봤다. 그런데 한 가지 의문이 생긴다. 우리가 매일 쓰는 쇼핑몰에서는 로그인이 유지되고 장바구니도 사라지지 않는다. HTTP는 Stateless라고 했는데, 이게 어떻게
[Spring AI] Agentic Workflow — AI가 스스로 생각하고 행동하는 방법
지난 글에서는 Spring AI의 Advisor 패턴과 Function Calling을 통해 LLM이 외부 도구를 활용하는 방법을 살펴봤다. 그런데 도구를 쓸 수 있다고 해서 에이전트가 되는 건 아니다.이번 글에서는 다음 질문들을 중심으로 Agentic Workflow
[Spring AI] Spring AI Advisor 패턴과 Function Calling
지난 글에서는 RAG(Retrieval-Augmented Generation)를 통해 LLM이 외부 문서를 참조해서 답변하는 방법을 배웠다. 이번 글에서는 한 단계 더 나아간다.이런 질문들을 생각해보자.대화 기록 저장, 욕설 필터링 같은 공통 로직을 매번 Service
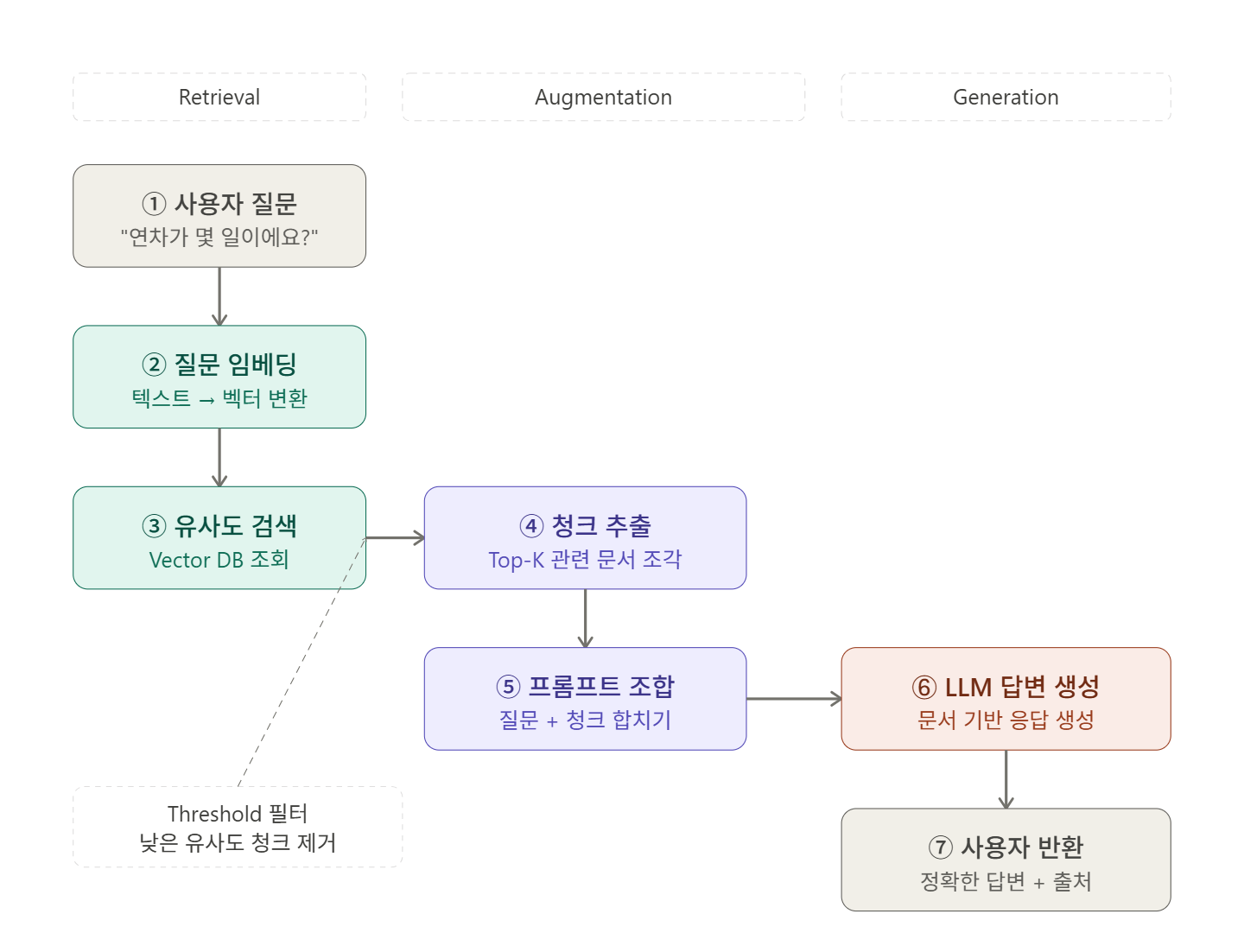
[Spring AI] Spring AI와 RAG — LLM에게 참고서를 쥐어주는 법
지난 글에서는 Vector DB와 임베딩을 다뤘다. 텍스트를 숫자 배열로 변환해서 의미 기반 유사도 검색을 할 수 있다는 것, 그리고 기존 LIKE 검색이 왜 의미 파악에 한계가 있는지를 살펴봤다.이번 글에서는 그 Vector DB를 실제로 활용하는 패턴인 RAG를 다
[Spring AI] Vector DB와 Spring AI
10단계에서 LLM은 Stateless하기 때문에 매 요청마다 컨텍스트를 직접 전달해야 한다고 배웠다. 그런데 컨텍스트가 길어질수록 토큰 비용이 폭증하고, 필요한 정보만 골라서 전달해야 한다는 문제가 남아 있었다.이번 글에서는 그 해결책의 핵심인 Vector DB를 다
[Spring AI] 로컬에서 AI 모델 돌리기 — Spring AI + Ollama 연동
지금까지 Spring AI로 Gemini와 OpenAI 같은 클라우드 API를 연동해봤다.ChatClient 하나로 다양한 모델을 추상화해서 쓸 수 있다는 것도 확인했다.그런데 이런 의문이 생길 수 있다.클라우드 API를 쓰면 데이터가 외부 서버로 나가는데, 민감한 정
[Spring AI] LLM 컨텍스트 관리와 멀티모달
지난 글에서는 LLM과 대화를 설계하는 방법을 다뤘다. System / User / Assistant 세 가지 메시지 타입을 이해하고, 히스토리를 어떻게 구성해야 AI가 맥락을 잘 이해하는지 살펴봤다.그런데 히스토리를 쌓다 보면 자연스럽게 이런 의문이 생긴다.대화가 1