이전 강의에서 배웠던 선형모델은 단순한 데이터를 해석할 때는 유용하지만 분류문제나 좀 더 복잡한 패턴의 문제를 풀 때는 예측성공률이 높지 않습니다. 이를 개선하기 위한 비선형 모델인 신경망을 본 강의에서 소개합니다.
신경망의 구조와 내부에서 사용되는 softmax, 활성함수, 역전파 알고리즘에 대해 설명합니다.
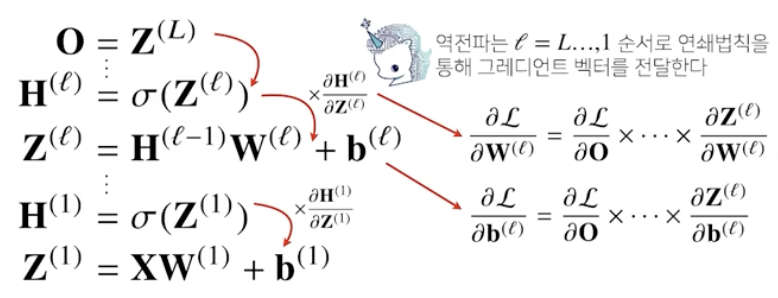
딥러닝은 여러 층의 선형모델과 활성함수에 대한 합성함수로 볼 수 있으며, 이 합성함수의 그래디언트를 계산하기 위해서 연쇄법칙을 적용한 역전파 알고리즘을 사용합니다. 이와 같은 딥러닝의 원리를 꼭 이해하시고 넘어가셨으면 좋겠습니다.
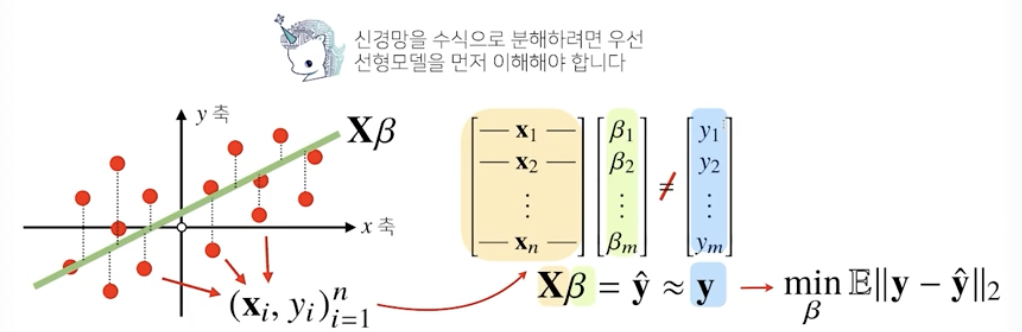
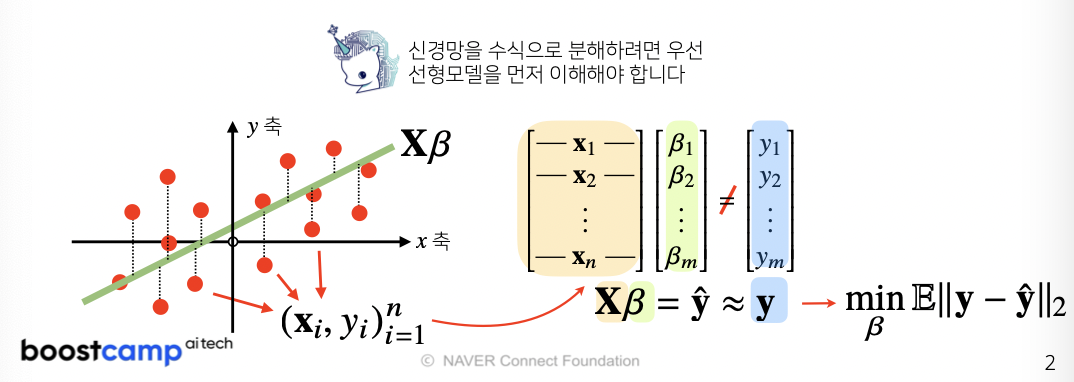
지난 시간까지 데이터를 선형 모델로 해석하는 방법을 배웠으니 이제는 비선형 모델인 neural network에 대해 배워보자
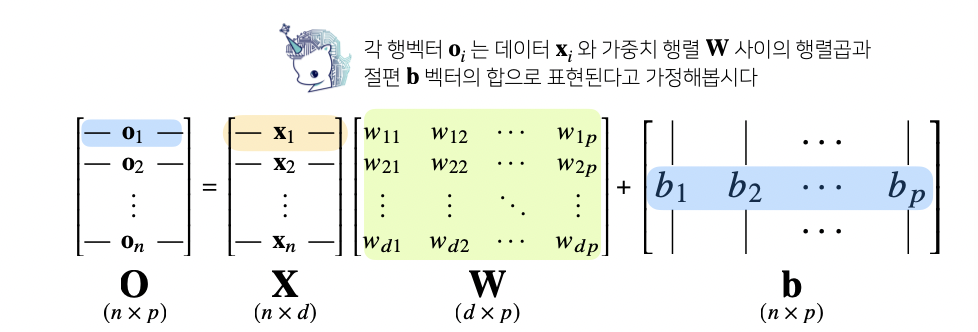
이 때 데이터가 바뀌면 결과값도 바뀌게 된다
출력 벡터의 차원은 d -> p로 변한다
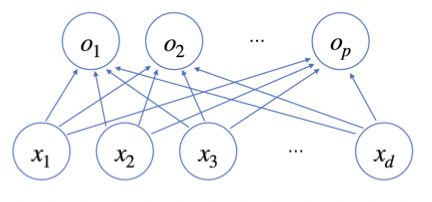
d개의 변수로 p개의 선형 모델을 만들어서 p개의 잠재변수를 설명하는 모델을 상상해보자
신경망을 수식으로 분해해보자

소프트맥스 연산
sofrmax 함수는 모델의 출력을 확률로 해석할 수 있게 변환해주는 연산
분류 문제를 풀 때 선형 모델과 소프트맥스 함수를 결합하여 예측

def softmax(vec):
denumerator = np.exp(vec - np.max(vec, axis=1, keepdims=True))
numerator = np.sum(denumerator, axis=1, keepdims=True)
val = denumerator / numerator
return val
vec = np.array([[1,2,0], [-1,0,1], [-10,0,10]])
softmax(vec)array([[2.44728471e-01, 6.65240956e-01, 9.00305732e-02],
[9.00305732e-02, 2.44728471e-01, 6.65240956e-01],
[2.06106005e-09, 4.53978686e-05, 9.99954600e-01]])그러나 추론을 할 때는 one-hot vector로 최대값을 가진 주소만 1로 출력하는 연산을 사용해서 softmax를 사용하지는 않는다
def one_hot(val, dim):
return [np.eye(dim)[_] for _ in val]
def one_hot_encoding(vec):
vec_dim = vec.shape[1]
vec_argmax = np.argmax(vec, axis=1)
return one_hot(vec_argmax, vec_dim)
def softmax(vec):
denumerator = np.exp(vec - np.max(vec, axis=1, keepdims=True))
numerator = np.sum(denumerator, axis=1, keepdims=True)
val = denumerator / numerator
return val
vec = np.array([[1,2,0], [-1,0,1], [-10,0,10]])
print(one_hot_encoding(vec))
print(one_hot_encoding(softmax(vec)))[array([0., 1., 0.]), array([0., 0., 1.]), array([0., 0., 1.])]
[array([0., 1., 0.]), array([0., 0., 1.]), array([0., 0., 1.])]신경망은 선형모델과 activation function을 합성한 함수
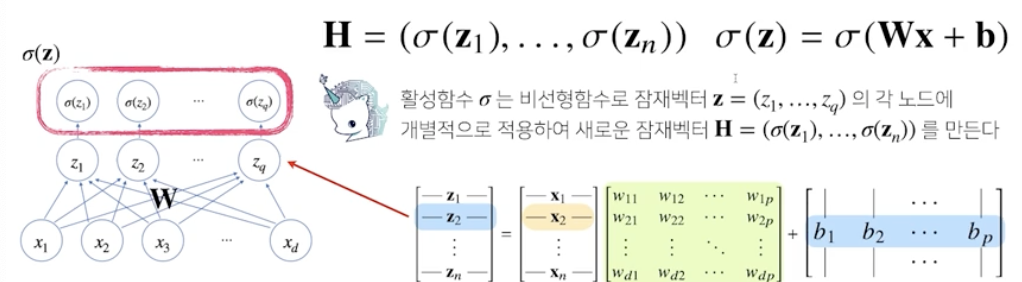
활성함수
활성함수는 R 위에 정의된 비선형 함수로서 딥러닝에서 매우 중요한 개념!
활성 함수를 쓰지 않으면 딥러닝은 선형 모형과 차이가 없음
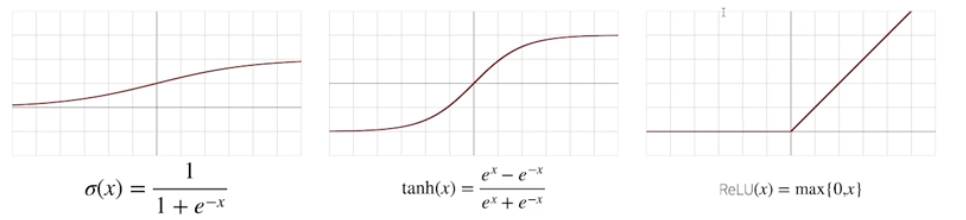
sigmoid 함수나 tanh 함수는 전통적으로 많이 쓰이던 활성함수지만 딥러닝에서는 ReLU가 많이 쓰임
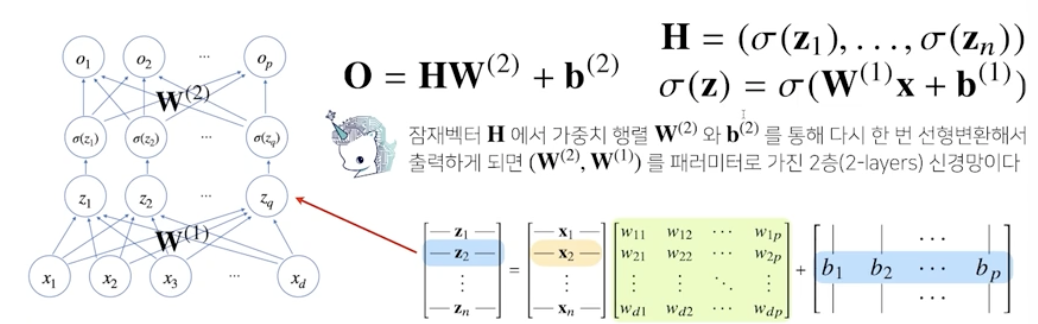
다층 multi-layer 퍼셉트론 MLP는 신경망이 여러층 합성된 함수
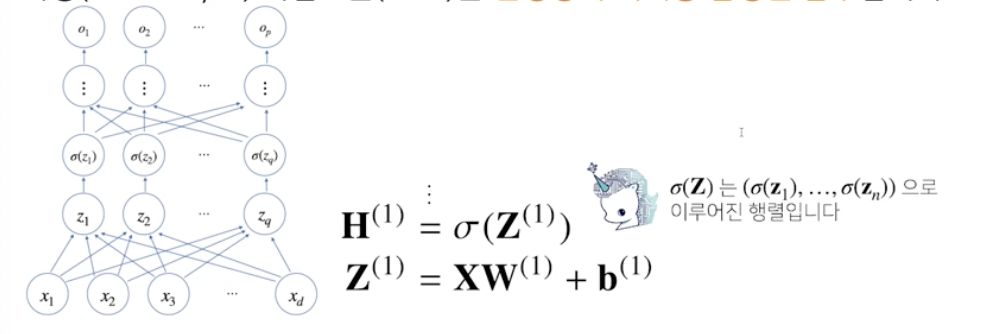
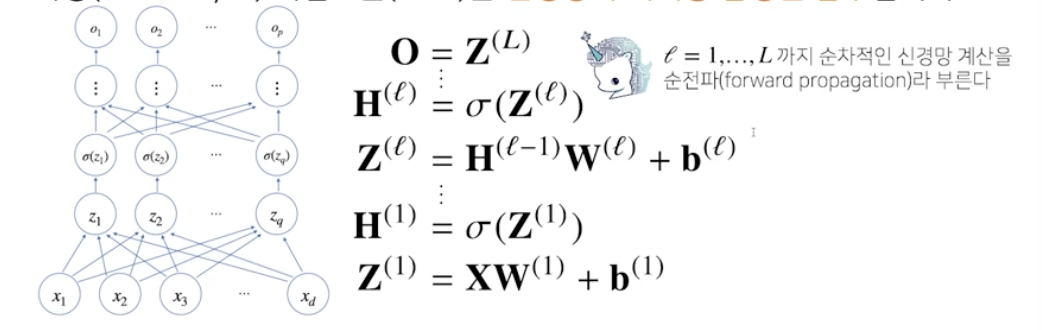
왜 층을 여러개 쌓는지?
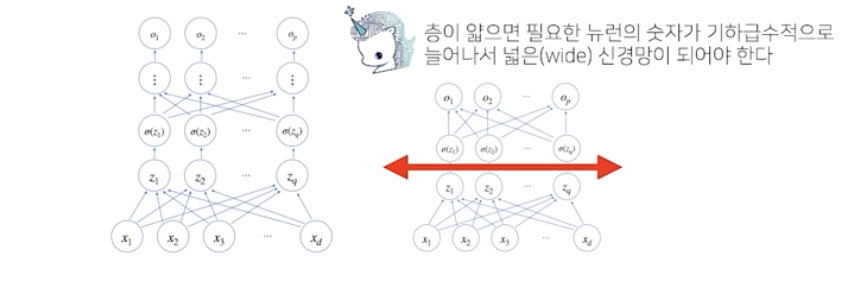
이론적으로는 2층 신경망으로도 임의의 연속함수를 근사할 수 있음 by univeral approximation theorem
층이 깊을수록 목적함수를 근사하는데 필요한 neuron(node)의 숫자가 훨씬 빨리 줄어들어 효율적인 학습 가능!
역전파 알고리즘
딥러닝은 backpropagation 알고리즘을 이용하여 각 층에 사용된 parameter를 학습

역전파 알고리즘은 합성함수 미분법인 연쇄법칙 chain-rule 기반 자동 미분 auto-differentiation 사용
각 층 패러미터의 gradient vector는 윗층부터 역순으로 계산