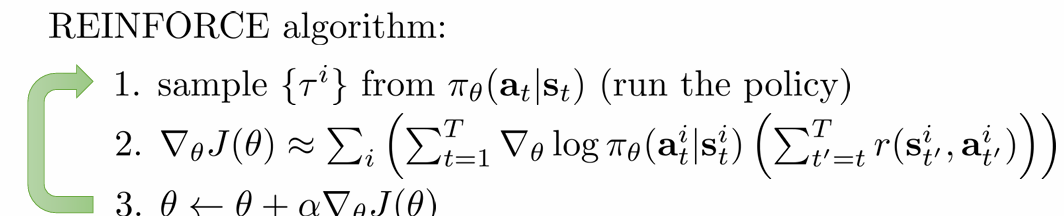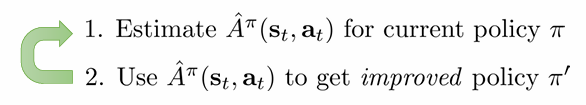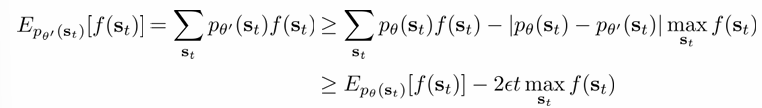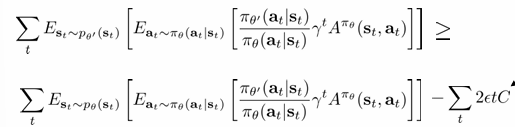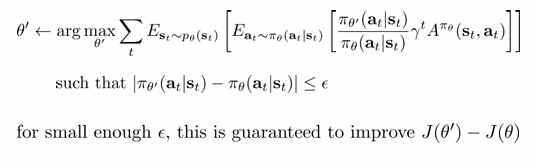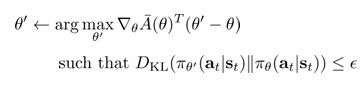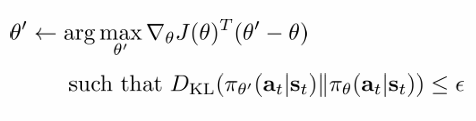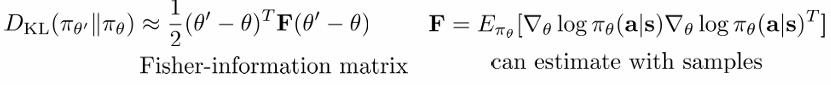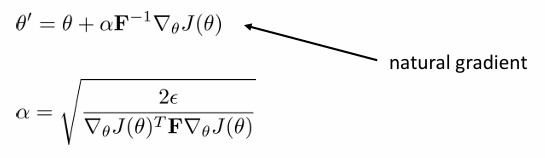제 나름의 지식을 많이 덧붙여 틀린 부분이 있을 수 있습니다. 발견하시면 댓글로 지적 부탁드립니다!
이해가 안되는 경우 질문도 환영입니다!
Ch9. Advanced Policy Gradients
Policy Gradients as Policy Iteration
recap: policy gradient
다시 policy gradient로 돌아갑니다. policy gradient의 알고리즘은 위와 같았습니다. Policy를 direct하게 θ로 매개화하고, objective function J(θ)를 이용해 gradient ascent로 update합니다. 여기서 reward를 어떻게 estimate하느냐, baseline으로 무엇을 쓰느냐에 따라 알고리즘이 달라졌었습니다.
policy gradient를 advantage function으로 update하는 아래 식을 보겠습니다.
이 식은 다음과 같이 정리할 수 있습니다.
Advantage function을 추정해서 policy를 improve합니다. 이는 policy iteration과 정확히 같은 방식이죠. 그러나 policy iteration은 π를 hard하게 최선의 policy 하나만을 선택하도록 update하는 데에 반해, policy gradient는 soft하게 좋은 정책의 확률을 늘리고 나쁜 정책의 확률을 줄이는 방향으로 업데이트 됩니다.
그런데 policy gradient는 이론상 맞긴 한데, learning rate α의 미세한 차이에 따라 gradient step이 너무 커지기도, 너무 작아지기도 하는 불안정한 문제가 있습니다. 이에 반해 policy iteration은 Bellman Operator의 contraction 성질(ch7의 마지막에서 살펴보았습니다)에 의해 유일해로 수렴한다는 것을 잘 알고 있습니다. 따라서 이 챕터에서는, policy gradient를 policy iteration의 방식으로 나타내어 policy gradient가 잘 작동하는 것을 목표로 합니다. 이러한 개념은 TPRO나 PPO와 같이 잘 작동하는 알고리즘으로 이어집니다.
policy gradient as policy iteration
policy gradient 식을 policy iteration처럼, advantage의 argmax로 update 하는 꼴로 나타내보겠습니다.
그러기 위해서는 policy의 improvement를 다음과 같이 정의하겠습니다.
J(θ′)−J(θ)=J(θ′)−Es0∼p(s0)[Vπθ(s0)]
이는 이전 policy parameter θ와 변화한 policy parameter θ′에 의한 objective function의 차이로 이루어져 있죠. 이를 전개해보면 아래와 같이 정리됩니다.
두번째 등호는 initial state의 marginal distribution이 변하지 않기 때문에 성립합니다. 그 뒤 약간의 trick을 써서 정리해준 것 뿐이죠. 정리된 식은 다음과 같습니다.
J(θ′)−J(θ)=Eτ∼pθ′(τ)[t=0∑∞γtAπθ(s0)]
기존의 parameter는 θ이니 이에 대한 식으로 나타내기 위해 다음과 같이 improvement를 전개합니다.
부등호는 두 probability의 차이는 2 이하이기 때문에 성립합니다. 또한 1−ϵt≤(1−ϵ)t를 이용하였습니다.
arbitrary distribution
이 식을 일반화하겠습니다. 아래와 같은 lemma 때문에 위의 식이 일반적인 policy에 대해 성립합니다.
bounding the objective value
∣pθ′(st)−pθ(st)∣≤2ϵt
이 식에 의해 다음이 성립합니다.
이를 원래의 식에 적용해보면 다음과 같습니다.
이는 즉 우리가 원하는(구할 수 있는) Aˉ(θ)을 최대화하면 기존 improvement의 bound가 최대화되니 improvement가 최대화되는 효과를 낳을 수 있다는 것입니다. 즉 우리는 우리가 구할 수 있는 위 식의 왼쪽 부분을 argmax하면 policy iteration처럼 policy gradient가 잘 작동하게 만들 수 있습니다. 제한된 영역 하에서 improvement를 최대화한다. 이것이 기본 아이디어가 되는 것입니다.
KL divergence는 미분가능 등 policy gradient에서 더 쉽게 유용할 수 있는 장점이 있기 때문입니다.
이를 최적화 관점에서 Lagrange multiplier를 이용해 나타내면 위와 같습니다. 이를 dual gradient descent라고 합니다.
Natural Gradient
그렇다면 이 식을 어떻게 최적화할까요? 최적화 방법 중 가장 간단한 natural gradient를 소개합니다.
우선 식은 위와 같았습니다. 이를 1차 taylor expansion을 이용하면 다음과 같습니다. θ≈θ′인 구간에서 gradient를 estimate하면 기존 policy gradient와 같아지는 것을 알게됩니다.
그러면 식은 다음과 같이 정리됩니다
KL divergence는 second order taylor expansion에 의해 다음과 같이 정리됩니다.
따라서 update 식은 다음과 같아집니다. 이것이 natural gradient입니다.
이로서 ch9에 대한 포스팅이 끝났습니다. 틀린 부분이나 이해가 안된 부분이 있다면 댓글 주세요!