Abstarct
SPADE는 일반적으로 일부만 레이블이 지정된 이상 탐지 문제에 사용되며, 레이블이 지정된 데이터와 레이블이 지정되지 않은 데이터가 동일한 분포에서 나온다는 가정에 제한받지 않습니다.
하지만 위와 같은 방식은 기존의 딥러닝 모델에 가정과 상충되는 부분이 많습니다. 예를 들어, 레이블이 지정된 데이터로 학습을하게되고 다른 분포인 레이블이 지정되지 않은 값들로 Test를 하게된다면 Task를 잘 수행하지 못할것입니다.
SPADE는 의사 레이블러로 구성된 앙상블을 활용하여 의사 레이블링을 통한 분포 불일치 문제의 강건성을 향상시킵니다.
제한된 레이블이 있는 경우에는 검증 데이터 없이 의사 레이블링에 필수적인 중요한 하이퍼파라미터를 자동으로 선택하기 위해 부분 일치 방법이 제안됩니다.
SPADE는 Tabular 및 이미지 도메인의 분포 불일치를 가진 다양한 시나리오에서 Sota의 이상 탐지 성능을 보여줍니다.
모델이 새로운 유형의 레이블 즉 지정되지 않은 이상 값 (분포가 다른경우)에 직면하는 일반적인 실제 환경에서 SPADE는 5%의 AUC 성능 향상을 보입니다.
Introduction
이상 탐지는 제조 결함, 네트워크 보안 위협 및 금융 사기 등 다양한 실제 응용 분야가 있습니다. 기존 논문들은 이상 탐지를 다양한 Setting에서 실험을 합니다.
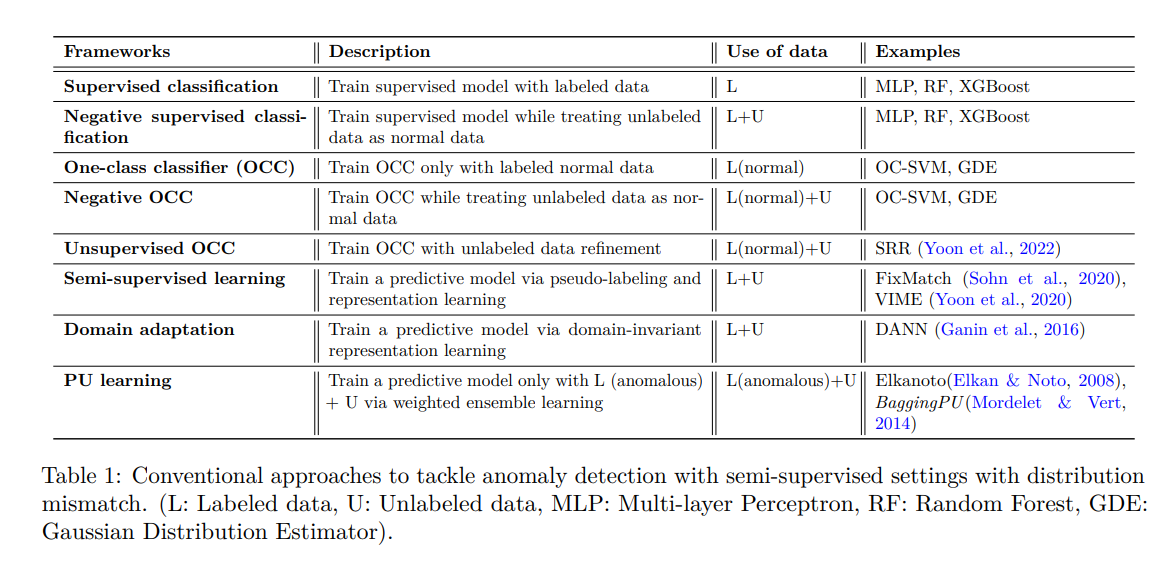
1. 지도 학습 설정으로, 모든 샘플에 대한 레이블이 정상 및 이상 샘플에 대해 모두 제공됩니다. 이 설정은 일반적으로 데이터 불균형에 대한 특화된 접근 방식으로 처리됩니다. 예를 들어, 가중 손실 함수나 재샘플링 방법 등이 사용될 수 있습니다.
2. Semi-Supervised 방식으로 정상 레이블만 지정되 있는경우. 이 경우, OCC 또는 오토인코더와 Isolation Forest가 주로 사용됩니다.
3. Unsupervised Learning 방식으로 이 설정에서는 레이블링 비용을 완전히 제거할 수 있지만, Supervised 방식과 비교하여 성능 저하가 큽니다.
해당 논문은 한정된 레이블링으로 높은 성능을 달성하기 위해 반지도식 이상 탐지 설정에 초점을 맞추고자 합니다.(Semi-Supervise방식) 반지도식 이상 탐지에 대한 이전 연구들에서는 양성-미지정 설정(정상만 레이블되어있는 경우)에 중점을 둔 경우도 있었으며, 다른 경우에는 One-Class Classifier나 반지도 학습에 적대적 훈련을 활용하였습니다.
하지만 대부분의 Semi-Supervised 학습 방법은 레이블이 지정된 데이터와 레이블이 지정되지 않은 데이터가 동일한 분포에서 나온다는 가정을 가지고 있습니다. 그러나 실제로는 이 가정이 종종 성립하지 않습니다. 레이블이 지정된 데이터와 레이블이 지정되지 않은 데이터가 서로 다른 분포에서 나오는 분포 불일치 문제가 흔하게 발생합니다.
그러나 그 외에도 Fig. 1에서 보여지는 것처럼 더 일반적인 실제 시나리오가 있습니다. 첫째, 양성-미지정(PU) 또는 음성-미지정(NU) 설정은 레이블(양성 또는 음성)과 미지정(양성 및 음성 모두) 샘플 간의 분포가 다른 경우가 일반적입니다(Fig. 1(왼쪽))
둘째, 레이블링 이후 추가적인 미지정 데이터를 수집할 수 있으며, 이로 인해 분포 변화가 발생할 수 있습니다. 예를 들어, 제조 공정은 계속 진화하고 따라서 해당 결함은 변경될 수 있으며, 레이블링에서의 결함 유형과 미지정 데이터의 결함 유형이 다를 수 있습니다(Fig. 1(가운데)).
마지막으로, 사람들은 쉬운 샘플에 대해 더 자신감을 가집니다. 따라서 쉬운 샘플은 레이블이 지정된 데이터에 더 자주 포함되고, 어려운 샘플은 레이블이 지정되지 않은 데이터에 더 자주 포함됩니다(Fig. 1(오른쪽)). 예를 들어, 일부 크라우드소싱 기반 레이블링 도구에서는 레이블에 대한 일치도 측정값으로써 일부 합의된 샘플만 레이블이 지정된 집합에 포함됩니다.

Contribution
-
분포 불일치 문제에 대처합니다.
-
Semi-Supervised 학습 프레임워크인 SPADE를 제안합니다. SPADE의 구성 요소들은 강건한 반지도 학습을 가능하게 합니다. 이를 위해, SPADE는 OCC(One-Class Classifier)의 앙상블을 사용한 의사 레이블링 메커니즘과 지도 및 자기-지도 학습을 조합하는 방법을 도입합니다. SPADE는 소수의 레이블링 및 의사 레이블링된 샘플로 예측기를 훈련함으로써 레이블링 데이터에 대한 의존성을 감소시킵니다.
-
검증 세트 없이 하이퍼파라미터를 선택하기 위해 부분 일치 방법을 활용하는 새로운 접근 방식을 제안합니다. 이 혁신적인 방법은 제한된 레이블 데이터를 가진 실제 환경에서 일반적으로 사용할 수 없는 검증 세트에 의존하는 전통적인 하이퍼파라미터 선택에 중요합니다.
-
일반적인 실제 시나리오를 대표하는 여러 설정에서 SPADE의 최첨단 반지도식 이상 탐지 성능을 보여줍니다. SPADE의 AUC 개선은 표 데이터에서 최대 10.6%, 이미지 데이터에서 3.6%까지 나타납니다.
-
분포 변화로 인한 사기 탐지와 같은 중요한 실제 기계 학습 도전에 초점을 맞춥니다. 환경의 적대적 특성으로 인해 시간에 따라 분포가 변하는 상황에서 SPADE가 기존 방법보다 일관된 우수한 성능을 보여줍니다.
Related Work
Distribution mismatch.
최근 연구 중 일부는 레이블이 지정된 데이터와 레이블이 지정되지 않은 데이터 간의 분포 불일치를 직접 다루고 있습니다. (Chen et al., 2020b; Saito et al., 2021)는 레이블이 지정된 데이터는 테스트 데이터의 분포가 동일하지만, 레이블이 지정되지 않은 분포가 다른 샘플이 포함된다고 가정합니다.
이 두 논문은 모두 레이블이 지정되지 않은 데이터에서 분포 밖 샘플을 제거하여 레이블이 지정된 데이터와 레이블이 지정되지 않은 데이터 간의 분포를 일치시키는 데 초점을 맞추고 있습니다.
반면, SPADE에서는 테스트 분포가 레이블이 지정된 데이터와 레이블이 지정되지 않은 데이터의 합집합이며, 레이블이 지정된 데이터의 분포는 테스트 분포와 다릅니다. Pang et al. (2019)는 SPADE의 PU 시나리오에서 포지티브하게 레이블이 지정된 샘플의 존재를 가정합니다. Pang et al. (2021)은 또한 레이블이 지정되지 않은 데이터에서 새로운 이상 형식을 가정하며, 이 논문에서도 해당 내용을 다루고 있습니다(5.1절 참조).
Domain Adapatation
훈련 분포와 테스트 분포가 다른 문제를 해결하기 위한 방법들입니다. 이러한 방법들은 종종 도메인에 무관한 표현을 학습하여 다른 분포를 가진 테스트 세트에 대해 더 좋은 일반화를 목표로 합니다. Domain Adapatation에서는 테스트 데이터의 특징에 액세스할 수 있다고 가정한다면 (도메인 적응에서 일반적인 가정), 도메인 적응 문제를 반지도 학습 문제로 간주할 수 있습니다. 이 경우, 훈련 데이터는 레이블이 지정된 데이터로 취급되고 테스트 데이터는 레이블이 지정되지 않은 데이터로 취급됩니다. 그러나 도메인 적응 설정에서는 소수의 레이블이 지정된 데이터로 모델을 훈련하므로, 훈련된 모델의 성능은 소수의 소스 데이터에 제한될 수 있습니다.
Positive-Unlabeled (PU) learning.
특별한 시나리오 중 하나는 양성 샘플만 레이블로 가지고 있고, 레이블이 지정되지 않은 데이터에는 양성과 음성 샘플이 모두 포함된 경우입니다. 이 경우, 레이블이 지정된 데이터의 분포는 레이블이 지정되지 않은 데이터와 분명히 다릅니다. 이는 분포 불일치를 가진 반지도식 이상 탐지의 특별한 경우로 볼 수 있습니다.
두 가지 일반적으로 사용되는 접근 방식이 있습니다:
(i) 첫 번째 단계에서 확신 있는 음성 레이블을 찾고, 두 번째 단계에서 양성 레이블과 확신 있는 음성 레이블을 사용하여 지도 학습 모델을 훈련합니다. (ii) 모든 레이블이 지정되지 않은 데이터를 음성 샘플로 취급하고 클래스 레이블에 노이즈를 포함하는 편향 학습
(i)의 단점은 의심스러운 양성 샘플을 레이블이 지정되지 않은 데이터에서 배제한다는 점이고,
(ii)의 단점은 모델 훈련에 영향을 주는 레이블이 지정되지 않은 데이터의 오염입니다. 이러한 방법들은 PU 설정의 특수한 경우에 적용되며, 일반적인 반지도 학습 설정에 적용할 때는 최적이 아닙니다.
Proposed Method
수식정의
Dl = {(xl_i, yl_i)} -> 라벨링된 데이터 ∼ P_lX
Du = {xu_j} -> 라벨링X 데이터 ~ P_uX
기존 방법론들은 P_lx = P_ux 임.
제안하는 방법은 P_lx =/ P_ux 임.
Desiderate
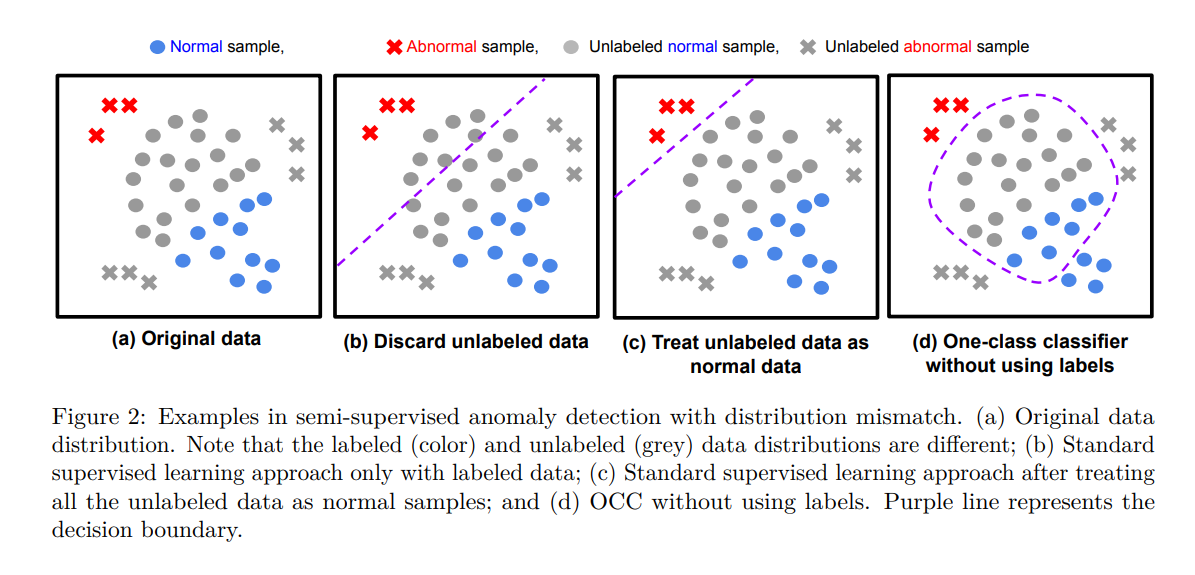
저희 프레임워크인 Semi-supervised Pseudo-labeler Anomaly Detection with Ensembling (SPADE)의 핵심 아이디어는 최근 반지도 학습의 발전을 따른 자기 학습(self-training)에 기반합니다. 저희는 레이블이 지정된 데이터와 가상 레이블 데이터로부터 반복적으로 학습하여 정상 데이터와 이상 데이터를 구분할 수 있는 이진 분류기를 훈련하는 것을 목표로 합니다. 이에 따라, 핵심 구성 요소는 레이블이 지정되지 않은 데이터에 바이너리 레이블을 할당하는 가상 레이블러입니다. 가상 레이블링에 훈련된 이진 분류기를 사용하는 것은 일반적이지만, 우리는 이것이 분포 변화를 가진 이상 탐지에는 최적이 아닐 수 있다고 주장합니다. 이는 바이너리 분류기의 결정 경계가 작은 레이블 데이터에 의해 강하게 편향될 수 있기 때문입니다. 그림 2(b, c)에서 보여지듯이, 이는 레이블이 지정된 데이터와 레이블이 지정되지 않은 데이터의 분포가 일치하지 않을 때 부정적인 영향을 미칠 수 있습니다. 대신, 저희는 가상 레이블러를 훈련된 바이너리 분류기와 분리하고 OCCs로 구성합니다. 이는 바이너리 분류기와 같이 레이블이 지정된 양성 데이터를 활용할 수는 없지만, 작은 양의 레이블 데이터에 대한 과적합을 방지하고 그림 2(d)에서 보여지는 것처럼 분포 변화에 더 견고할 수 있습니다.
Building blocks
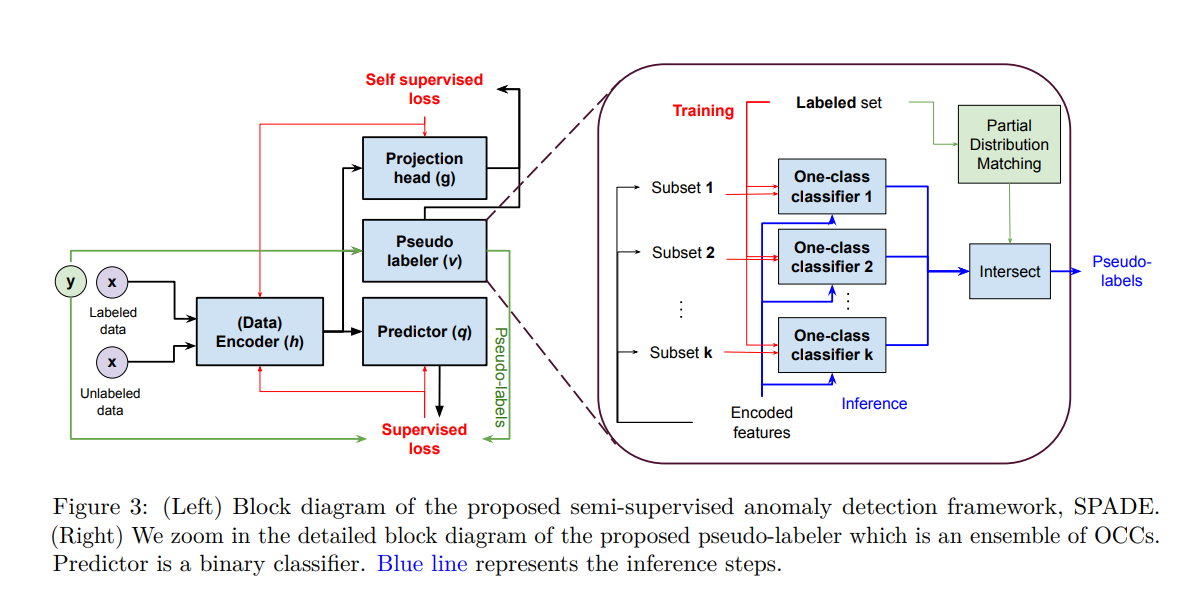
그림 3은 SPADE 프레임워크의 네 가지 구성 요소를 보여줍니다:
(i) 인코더
(ii) 예측기
(iii) 가짜 레이블러
(iv) 투영 헤드
(1) 먼저, 인코더: h : X → H는 입력 특성 x를 잠재 표현 r = h(x)으로 매핑합니다.
인코더로는 어떤 신경망 아키텍처든 사용할 수 있습니다.
해당 실험에서는 테이블 데이터에는 다층 퍼셉트론 (MLP)을 사용하고 이미지 데이터에는 합성곱 신경망 (CNN)을 사용했습니다.
(2) 예측기 q : H → Y는 학습된 표현 r을 사용하여 이상 점수 q(r)를 출력합니다. 이상 점수는 인코더 (h)와 예측기 (q)에 의해 다음과 같이 결정됩니다: q(h(x)).
(3), (4) 가짜 레이블러와 투영 헤드는 인코더와 예측기의 훈련을 돕습니다.
가짜 레이블러 v : H → {0, 1, -1}는 OCCs의 앙상블을 사용하여 레이블이 지정되지 않은 데이터 x_u의 가짜 레이블을 결정합니다.
v(h(x_u)) = 1/0/-1은 가짜 이상/가짜 정상/레이블이 지정되지 않음을 나타냅니다.
마지막으로, 투영 헤드 g : H → G는 인코더의 표현 학습을 돕는 블록입니다. 대조적 학습이나 사전 텍스트 작업 예측 (예: 마스크된 오토인코더)과 같은 표현 학습 방법을 포함하여 어떤 표현 학습 방법이든 사용할 수 있습니다.
Pseudo Labeler (v) (가짜 레이블러)
Step1. Labeled 된 데이터로만 각 One Class Classifier 학습.
Step2. 학습이 완료된 개별 Onc Class Classifier에 UnLabelled Data Inference.
Step3. Unlabelled 데이터가 ηp를 넘으면 1로
Step4. Unlabelled 데이터가 ηn보다 작으면 0으로 반환
Step5. 모든 Sub OCC(k개)에서 1을 반환하면 해당 UnLabelled Data는 1로 Pseudo Label 생성.
Step6. 반대로 모두 0을 반환하면 해당 UnLabelled Data는 0으로 Pseudo Label 생성.
Step7. 애매한 경우 -1로 반환
Determining ηp, ηn using partial matching
SPADE 프레임워크에서, 임계값 η_p와 η_n은 중요한 매개변수입니다. 하나의 옵션은 이들을 사용자가 정의한 하이퍼파라미터로 고려하고, 하이퍼파라미터 최적화를 통해 결정하는 것입니다. 그러나 하이퍼파라미터 튜닝은 추가적인 검증 데이터를 필요로 하며, 이는 레이블이 지정된 훈련 세트에서 가져와야 합니다.
부분 일치 방법을 적용하여 이 매개변수를 학습합니다. 이 방법은 레이블이 지정되지 않은 데이터의 주변 분포를 알려진 하나의 클래스 (양성 또는 음성) 분포와 일치시켜서 추정하는 데 사용됩니다. 그 근본적인 아이디어는 정상 샘플이 다른 정상 샘플에 더 가깝고, 이상 샘플이 다른 이상 샘플에 더 가깝다는 것입니다. 우리의 경우, 우리는 양성 레이블이 지정된 데이터의 이상 점수 분포를 레이블이 지정되지 않은 데이터의 이상 점수 분포와 일치시켜 주변 분포를 추정하고 η_p를 결정합니다. 음성 레이블이 지정된 데이터를 사용하여 η_n을 결정하는 데에도 동일한 방식이 적용됩니다. η_p와 η_n의 수식은 아래에 나와 있습니다.
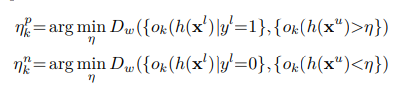
-> 처음에 특정 임계값 보다 큰 언라벨 데이터를 그 디스탄스를 작게하고 가장작은 임계값
->
-> 가장 처음 임계값은 몇으로???
Loss functions and optimization
해당 이상 탐지 모델 q(h(·))을 세 가지 손실 함수를 사용하여 훈련합니다:
(i) 레이블이 지정된 데이터에 대한 이진 교차 엔트로피 (BCE),
(ii) 가상 레이블된 데이터에 대한 BCE, 그리고
(iii) 전체 데이터에 대한 자기 지도 학습 손실. 자기 지도 모듈 g (예: 재구성 손실을 위한 디코더, 대조 손실을 위한 MLP 투영 헤드)은 보조적인 자기 지도 학습 손실과 함께 공동으로 훈련됩니다.
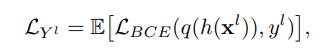
Pseudo-Labeled BCE Loss
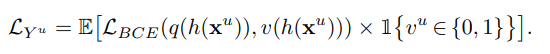
인코더 (h)의 품질을 향상시키기 위해, 우리는 다양한 사전 텍스트 작업에 따라 보조적인 자기 지도 학습 손실을 활용합니다. (Reconstruction Error를 활용하여)
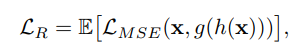
최종 Loss
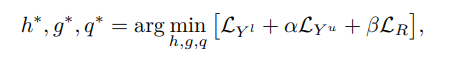
α, β = hyper-parameters (저자는 α , β 모두 1.0로 설정).
Experiments
제안된 방법 SPADE의 장점을 강조하기 위해 다양한 실용적인 설정에서 분포 불일치를 가진 반지도 학습의 다양한 실험을 진행했습니다.
이미지 데이터로는 MVTec 이상 탐지 데이터셋과 Magnetic Tile 데이터셋을 사용합니다.
표 형식의 데이터로는 Covertype, Thyroid, 그리고 Drug 데이터셋을 사용합니다
모든 실험에서, 데이터셋 자체가 훈련 및 테스트 분할을 가지고 있지 않은 경우, 데이터셋을 임의로 분할하여 겹치지 않는 훈련 및 테스트 데이터로 나눕니다. 그런 다음, 훈련 데이터를 추가로 겹치지 않는 레이블이 지정된 데이터와 레이블이 지정되지 않은 데이터로 나눕니다. 레이블이 지정된 데이터와 레이블이 지정되지 않은 데이터가 서로 다른 분포에서 온다는 점을 강조합니다

( ??? Once -Class Classification 할 때 UnLabelled Data도 포함? -> Margin 제대로 설정됨? )
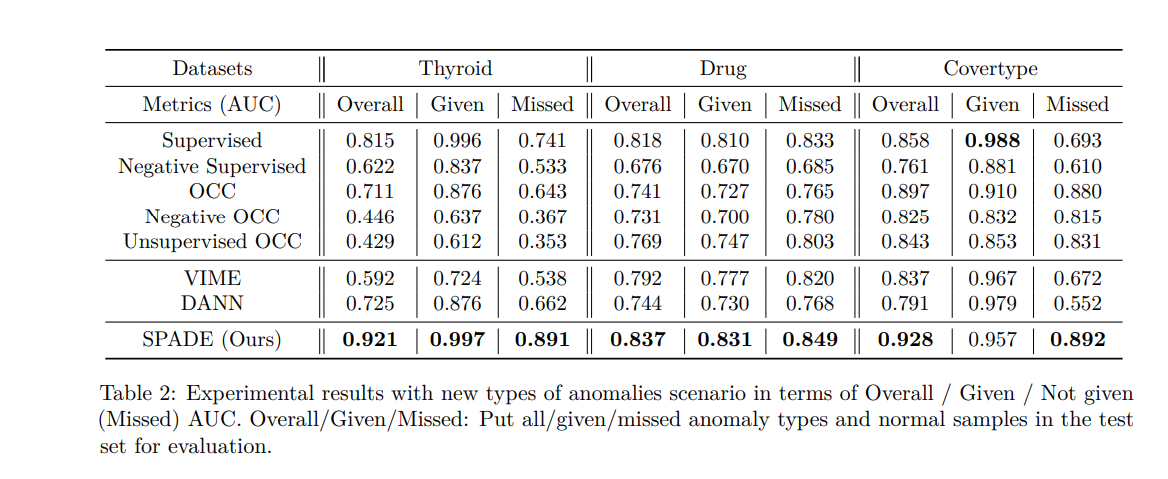
SPADE를 Table 1의 방법론들과 비교합니다.
보다 구체적으로, Gaussian Distribution Estimator (GDE)를 OCC (오직 음의 레이블된 데이터만 사용) 및 Negative OCC (양의 레이블된 데이터만 배제)에 사용합니다.
GDE는 다른 대안들 (isolation forests, OC-SVM 등)과 비교하여 가장 우수한 성능을 보여줍니다.
비지도 OCC의 비교모델은 SRR (Yoon 등, 2022)을 사용하고, 지도 (오직 레이블된 데이터만 사용) 및 음의 지도 기준선으로는 Random Forest를 사용합니다 (레이블되지 않은 데이터를 음으로 처리).
이미지 데이터에 대해서는 VIME 대신에 FixMatch를 반지도 기준선으로 사용합니다. MVTec 및 Magnetic 데이터셋에 대해 Negative OCC, 비지도 OCC, 그리고 SPADE의 기준선 아키텍처로 CutPaste를 사용합니다.
New types of anomalies
이상 탐지 시스템에서는 시간이 지남에 따라 이상 현상이 변화할 수 있습니다. 사기 탐지의 경우, 범죄자들은 기존 시스템을 속이기 위해 새로운 사기 방법을 개발할 수 있으며, 제조업에서는 수정된 공정으로 인해 이전에 접하지 못한 다른 결함이 발생할 수 있습니다. 따라서 레이블이 지정된 데이터는 오래되어 더 이상 유효하지 않을 수 있고, 새롭게 수집된 레이블이 지정되지 않은 데이터는 다른 분포에서 나올 수 있습니다. 이러한 시나리오를 모방하기 위해 여러 종류의 이상 현상을 포함하는 데이터셋을 구축합니다.
여러 종류의 이상 현상 중에서, 이상 타입의 일부분이 Labeled된 데이터 형태로 제공됨.
• Thyroid 데이터에 대해, 레이블 1 이상 현상 유형을 레이블이 지정된 데이터로 제공합니다 (레이블 2 이상 현상 유형은 레이블이 지정되지 않은 데이터에만 포함됩니다).
• Drug 데이터에 대해, 레이블 2, 3, 4 이상 현상 유형을 레이블이 지정된 데이터로 제공합니다 (레이블 5, 6, 7 이상 현상 유형은 레이블이 지정되지 않은 데이터에만 포함됩니다).
• Covertype 데이터에 대해, 레이블 3, 4, 5 이상 현상 유형을 레이블이 지정된 데이터로 제공합니다 (레이블 6, 7 이상 현상 유형은 레이블이 지정되지 않은 데이터에만 포함됩니다).
• MVTec 및 Magnetic tile 데이터셋의 경우, 각 카테고리에는 서로 다른 수의 이상 현상 유형이 있습니다. 레이블이 지정된 데이터로 홀수 형태의 이상 현상 유형을 제공합니다. 모든 짝수 형태의 이상 현상은 레이블이 지정되지 않은 데이터에 포함됩니다.
실험 결과를 보면 SPADE가 보이지 않은 이상 현상에 대해서도 일반화 능력이 뛰어나다는 것을 확인할 수 있습니다.
지도 학습과 반지도 학습 (VIME과 FixMatch) 방법은 주어진 이상 현상에 높은 편향을 가지고 있음
지도 분류기는 레이블이 지정되지 않은 데이터를 전혀 활용하지 못하며,
음의 지도 분류기는 예측 모델을 훈련하기 위해 오염된 레이블이 지정된 데이터로 인해 어려움을 겪음.
OCC 모델은 이상 레이블 정보를 활용하지 못하므로 최적이 아님.
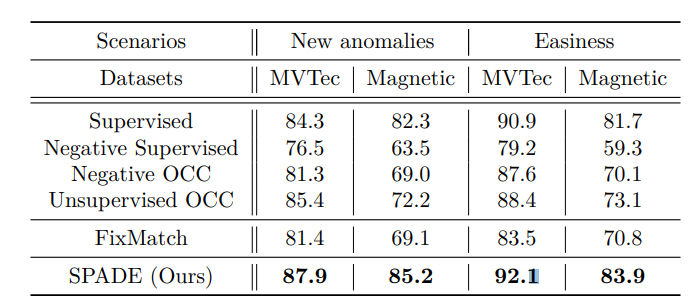
Labeling based on the ‘easiness’ of samples
모델이 구분하기 쉬운레이블링만 라벨링
-> 모델이 구분하기 쉽냐 어렵냐 기준? -> 로지스틱으로 학습한 뒤 예측하여 잘 구분한것은 쉬운 레이블링
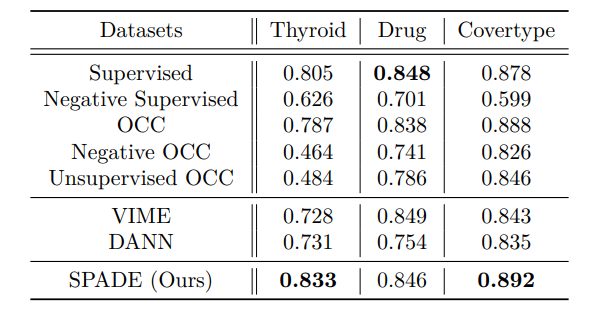
PU-Learning
라벨이 지정된 데이터에는 양성 샘플만 있고, 다른 모든 샘플은 레이블이 지정되지 않은 경우인 양성 및 레이블이 지정되지 않은 (PU) 설정에서, 레이블이 지정된 데이터 (양성 샘플만)와 레이블이 지정되지 않은 데이터 (양성 및 음성 샘플 모두)의 분포는 서로 다를 수 있습니다. '새로운 이상형 타입' 시나리오와 동일한 실험 설정을 사용하지만, 라벨이 지정된 데이터에서 정상 샘플을 추가로 제외하여 PU 설정을 대표하도록 합니다.

Conclusion
반지도 이상 탐지는 실무에서 매우 중요한 도전과제입니다. 많은 상황에서 라벨이 지정된 샘플과 라벨이 지정되지 않은 샘플의 분포가 동일하다고 가정할 수 없습니다. 본 논문에서는 이러한 상황에 대해 집중적으로 다루며, 표준 프레임워크의 성능이 이 설정에서 어떻게 저하되는지를 보여줍니다. 우리는 새로운 프레임워크인 SPADE를 제안합니다. 이는 앙상블 OCCs를 사용한 새로운 의사 라벨링 메커니즘과 지도 및 자기 지도 학습을 결합하는 신중한 방법을 도입합니다. 또한, 유효한 검증 세트 없이 하이퍼파라미터를 선택하는 새로운 접근 방식을 사용합니다. 이것은 데이터 효율적인 이상 탐지에 있어서 중요한 요소입니다. 전반적으로, SPADE가 다양한 시나리오에서 대안들보다 일관적으로 더 나은 성능을 보여줍니다 - SPADE를 사용하면 표에 표현된 데이터에서 최대 10.6%, 이미지 데이터에서 최대 3.6%의 AUC 향상을 얻을 수 있습니다. 또한, 이상 탐지 외에도 향후 연구에서는 이 반지도 프레임워크를 분포 불일치를 갖는 다중 클래스 분류나 회귀로 확장할 수 있을 것입니다.
