[데이터 사이언스 입문] - pandas 사용법 ( DataFrame, Series, Subset, Summarize, sort, Groupby, plot)
0
datascience
목록 보기
2/2

🖥️ pandas 란?
pandas는 행과 열을 기반으로 한 엑셀과 같은 데이터 분석을 하는 툴이다.
대용량 데이터를 빠르게 처리하고 소스 코드를 주피터를 이용해 재사용이 가능하다는 점이 장점이다.
🖥️ pandas 사용법
먼저, pandas를 불러보자.
import pandas as pd이후 간단한 표를 만들어 그 표를 분석해보자.
df = pd.DataFrame({"a":[4,5,6],"b":[7,8,9],"c":[10,11,12]}, index=[1,2,3])
df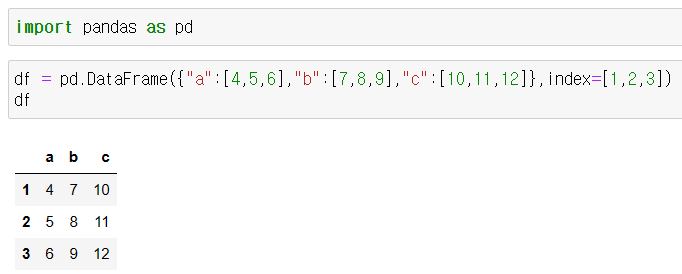
위의 그림과 같이 표가 생성되었다.
- series 데이터
df["a"]위 코드는 a칼럼에 있는 데이터(4,5,6)을 출력하는 걸 series 데이터라 한다.
 위 사진과 같이 인덱스 값과 a의 데이커 값이 출력되는 걸 알 수 있다.
여기서,
위 사진과 같이 인덱스 값과 a의 데이커 값이 출력되는 걸 알 수 있다.
여기서, df[["a"]]대괄호를 하나 더 쓰게 되면 a칼럼의 데이터값이 DataFrame형태로 나타난다.
 즉 DataFrame은 2차원 구조이고 Series는 1차원의 구조이다.
즉 DataFrame은 2차원 구조이고 Series는 1차원의 구조이다.
- data의 일부 값만 추출하기
예 1) a값이 4초과인 데이터만 추출하고 싶을 경우,
 예 2) column값이 a,b인 경우만 데이터 추출할 경우,
예 2) column값이 a,b인 경우만 데이터 추출할 경우,
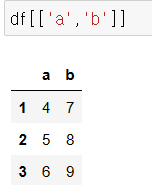 여기서 두 개 이상의 값을 불러 올때 DataFrame 형태로 불러와야함.
여기서 두 개 이상의 값을 불러 올때 DataFrame 형태로 불러와야함.
- data값의 빈도수 구하기
예 1) a값에 대한 빈도수 구하기

- data 정렬
예 1) a컬럼 기준으로 정렬

예 2) DataFrame 전체에서 'a'값 기준으로 정렬

cf. 역순으로 정렬 시, -> ascending=False
df.sort_values("a", ascending=False)예 3) "c"칼럼 삭제
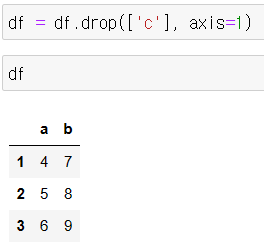
- group data
예 1) a 컬럼값을 그룹화하여 b 컬럼값 평균 구하기 -> a 값 정렬한 후 그에 맞는 b값이 여러개일 경우, 평균화. 하나 일 경우 그대로 기재한다. : groupby
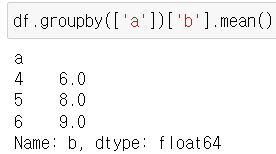 예 2) pivot_table로 a의 index에맞춘 평균값 구하기
예 2) pivot_table로 a의 index에맞춘 평균값 구하기

- 데이터를 이용한 시각화 : plotting
예 1) 꺽은선 그래프

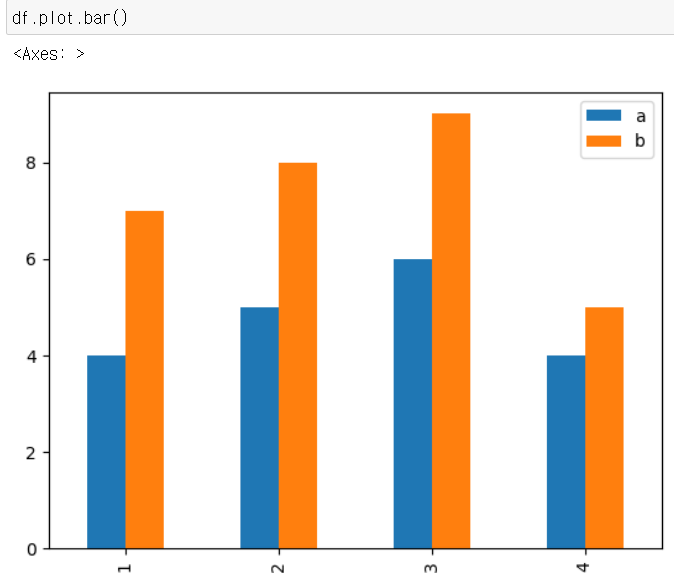
예 2) 막대 그래프
예 3) 밀도함수

