
새싹 인공지능 응용sw 개발자 양성 교육 프로그램 심선조 강사님 수업 정리 글입니다.
목차
- jupyter lab
- numpy
1. jupyter lab
ctrl + enter = 실행
shift + enter = 새로 생성
tab = 자동완성
shift + tab = 설명서
m = 마크다운모드
y = 함수작성모드
java array - 같은 종류의 데이터 타입만 가능
python list - 다른 종류의 데이터 타입 가능
프로그램밍 언어는 complie, interpreter 2개의 언어로 이루어져 있다.
complie언어(java)- 모아서 실행,
interpreter언어(python)- 한 줄씩 실행
2. numpy
https://numpy.org/devdocs/user/absolute_beginners.html
ndarray가 기본 구조 ex) pandas처럼
- import하는 방법
import numpy as np>>>a = np.arange(6)
>>>a2 = a[np.newaxis, :]
>>>a2.shape
(1, 6)
>>> = 명령프롬포트
a = n[.aragne(6)
a= range
대괄호 1개 = 일차원 = 벡터
딥러닝, 차원을 맞추는 것이 중요하다.
NumPy 배열은 Python 목록보다 빠르고 컴팩트하다.
배열
a = np.array(['1', 2, 3, 4, 5, 6])
a.dtype
dtype('<U11') #데이터 타입을 알려줌, '<U11'=유니코드- ()의차이
() = 속성 = 변수 값
어떤 값을 저장하는 변수값을 호출할 때는 ()을 안 씀
ex) java - 메서드를 호출할 때 ()를 사용
a.ndim
>> 1 #1차원이다
a.shape
>>(6,) #1차원에 원소 6개 있다- a vs print(a)
a = array
print = a의 값을 출력한다.
a
>>
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
print(a)
>>
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]배열에 대한 추가 정보
"n차원 배열"의 줄인말 = "ndarray"
[1, 1, 2, 3] = 1차원 배열 = 벡터
[]것이 2개 있다. = 2차원 배열 = array
[]것이 3개 있다. = 3차원 배열 = 매트릭스벡터는 1차원 배열
array는 2차원 배열
매트릭스 3차원 배열
3차원 이상의 배열은 텐서
값 하나는 스칼라
기본 배열을 만드는 법
- np.array()
- np.arange()
파이썬 *변수는 list로 받는다
**변수는 dictionary로 반는다. 이름을 정해 줘야 한다.
- int8, int64의 차이점
#데이터 유형 지정 dtype
np.zeros((2,3),dtype=np.int8) #int8, int64의 차이점 = 1bye 8 2bye 16, 1byte가지고 int를 표현하겠다. 딥러닝은 용량이 크기때문에 데이터의 적절한 사이즈를 잡아주는 게 중요하다.
#float는 기본이 64
>>
array([[0, 0, 0],
[0, 0, 0]], dtype=int8)
요소 추가, 제거 및 정렬
- np.sort()
- np.concatenate()
arr = np.array([2, 1, 5 ,3, 7, 4 ,6, 8])
np.sort(arr)
>>array([1, 2, 3, 4, 5, 6, 7, 8])
a = np.array([[1,4],[3,1]])
a
>>array([[1, 4],
[3, 1]])
np.sort(a,axis=0)
>>array([[1, 1],
[3, 4]])
np.sort(a,axis=1)
>>array([[1, 4],
[1, 3]])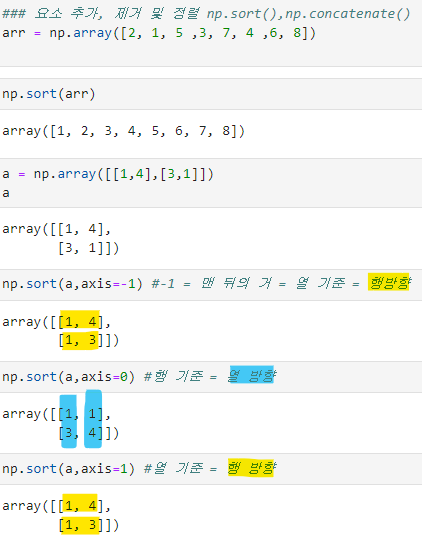
x = np.array([3, 1, 2])
>>array([1, 2, 0], dtype=int64)
np.argmax(x) #제일 큰 값의 인덱스를 return해라
>>0
x = np.array([[0, 3], [2, 2]])
x
>>array([[0, 3],
[2, 2]])
np.argsort(x, axis=-1) #-1 = 맨 뒤의 거 = 열 기준 = 행방향 ,
>> array([[0, 1],
[0, 1]], dtype=int64)
np.argsort(x, axis=1) #열 기준
>> array([[0, 1],
[0, 1]], dtype=int64)
np.argsort(x, axis=0) #행 기준
>>array([[0, 1],
[1, 0]], dtype=int64)#axis는 기본이 -1,
axis=1는 열기준으로 정렬
axis=0은 행기준으로 정렬
앞에는 작은 값이 오고 뒤에 큰 값이 온다.
- 추가 설명
a = np.array([[1,4],[3,1]])
a.shape = (2,2)
(2,2)
=0, 1
=행, 열
=-2, -1
기본값은 -1로 setting
-1 = 맨 마지막으로 기준으로 정렬해라
기본이 -1 = 늘 열 기준으로 정렬해라 = 행 단위로 처리가 된다.
#argsort는 지정된 축을 따른 간접 정렬 , arg = index값을 return한다.
- np.concatenate()
#concatenate
a =np.array([[[1, 2, 3, 4]]])
b =np.array([[[5, 6, 7, 8]]])
np.concatenate((a,b),axis=0)
#행단위라서 2줄 ( 차원, 행, 열) 행열이 몇개가 있는 거냐 axis = 0은 차원, axis=0이 기본값
>>array([[[1, 2, 3, 4]],
[[5, 6, 7, 8]]])
np.concatenate((a,b),axis=1) # , 열단위라서 1줄, 행이라서 1이붙고
>>array([[[1, 2, 3, 4],
[5, 6, 7, 8]]])
np.concatenate((a,b),axis=2) #axis=2은 열,
>>array([[[1, 2, 3, 4, 5, 6, 7, 8]]])
배열의 모양과 크기
-
ndarray.ndim : 배열의 축 또는 차원 수를 알려줍니다.
-
ndarray.size : 배열의 총 요소 수를 알려줍니다. 이것은 배열 모양 요소의 곱 입니다.
-
ndarray.shape : 배열의 각 차원을 따라 저장된 요소 수를 나타내는 정수 튜플을 표시합니다. 예를 들어 2개의 행과 3개의 열이 있는 2차원 배열이 있는 경우 배열의 모양은 입니다 .(2, 3)
#1차원은 무조건 옆에 붙는다, 2차원은 행, 열단위로 붙일수 있고 3차원도 가능하다
#배열의 모양과 크기
a.ndim #몇 차원이냐
>>3
a.size #요소의 개수 , 안에 데이터가 몇 개가 들어 있냐
>>4
a.shape #이렇게 생겼다. #1차원이면 (4,) #(1, 1, 4) 1행의 4열짜리가 1개가 있다.
>>(1, 1, 4)
np.concatenate((a,b),axis=0).shape
>>(2, 1, 4)
#. = method chaining
#앞쪽의 결과값이 return이 되어야 shape을 사용가능하다.배열의 재구성
- arr.reshape() : 데이터를 변경하지 않고 배열에 새로운 모양이 부여된다/
a = np.arange(6)
a
>>array([0, 1, 2, 3, 4, 5])
a.reshape(3,2) #3행의 2열로 바꾸겠다
>>array([[0, 1],
[2, 3],
[4, 5]])
a.reshape(2,3)
>>array([[0, 1, 2],
[3, 4, 5]])
a.reshape(1,6) #a.shape(2,2)요소가 많거나 부족하면 안 된다.
>>array([[0, 1, 2, 3, 4, 5]])
np.reshape(a,(2,3))
>>array([[0, 1, 2],
[3, 4, 5]])
a = np.array([1, 2, 3, 4, 5, 6])
a.shap
>>(6,)
1D배열을 2D배열로 변환하는 방법
(배열에 새 축을 추가하는 방법)
- np.newaxis
- np.expand_dims
a2 = a[np.newaxis,:]
a2
>>array([[1, 2, 3, 4, 5, 6]])
a2.shape
>>(1,6)
a3 = a[:, np.newaxis]
a3
>>array([[1],
[2],
[3],
[4],
[5],
[6]])
a3.shape
>>(6, 1)
#지정된 위치에 새 축 삽입가능
b = np.expand_dims(a, axis=0) #1차원 => 2차원
b #헹쪽으로 추가
>>array([[1, 2, 3, 4, 5, 6]])
b = np.expand_dims(a, axis=1) #1차원 => 2차원
b #열쪽으로 추가
>>array([[1],
[2],
[3],
[4],
[5],
[6]])
a3
>>array([[1],
[2],
[3],
[4],
[5],
[6]])
a4 = np.expand_dims(a3,axis=0)
#하나가 앞쪽에 추가 된다,
>>array([[[1],
[2],
[3],
[4],
[5],
[6]]])
a3.shape
>>(6,1)
a4.shape
>>(6, 1, 1)
aa = a3.reshape((3,2))
a4 = np.expand_dims(aa,axis=0)
a4.shape
>>(1, 3, 2)
a4 = np.expand_dims(aa,axis=1)
a4.shape
>>(3, 1, 2)
a4 = np.expand_dims(aa,axis=2)
a4.shape
>>(3, 2, 1)
a4 = np.expand_dims(aa,axis=3)
a4.shape
>>오류
기존 데이터에서 배열을 만드는 방법
- slicing and indexingnp
- .vstack()np
- .hstack()np
- .hsplit()
- .view()
- copy()
기본 배열 연산
broadcating
배열과 단일 숫자 사이의 연산 또는 두 개의 서로 다른 크기의 배열 간에 연산을 수행하려는 경우
두 개의 배열에서 작업할 떼 numpy는 요소별로 모양을 비교한다. 후행(즉, 맨 오른 쪽) 차원에서 시작하여 왼쪽으로 작동한다. 두 차원은 다음과 같은 경우 호환된다.
1. 동등하거나 2. 둘 중 하나는 1이다.
이러한 조건이 충족되지 않으면 배열에 호환되지 않는 모양이 있음을 나타내는 예외가 발생합니다.ValueError: operands could not be broadcast together
예를 들어 256x256x3RGB 값의 배열이 있고 이미지의 각 색상을 다른 값으로 조정하려는 경우 이미지에 3개의 값이 있는 1차원 배열을 곱할 수 있습니다. 브로드캐스트 규칙에 따라 이러한 배열의 후행 축 크기를 정렬하면 호환 가능함을 보여줍니다.
Image (3d array): 256 x 256 x 3
Scale (1d array): 3
Result (3d array): 256 x 256 x 3고유 아이템 및 개수 획득 방법
- up.unique()
a = np.array([11, 11, 12, 13, 14, 15, 16, 17, 12, 13, 11, 14, 18, 19, 20])
np.unique(a, return_index=True,return_inverse=True,return_counts=True) #중복된 값은 출력 안 한다. return_index=True = index값, return_counts=True = 몇 번 있는지
>>
(array([11, 12, 13, 14, 15, 16, 17, 18, 19, 20]),
array([ 0, 2, 3, 4, 5, 6, 7, 12, 13, 14], dtype=int64),
array([0, 0, 1, 2, 3, 4, 5, 6, 1, 2, 0, 3, 7, 8, 9], dtype=int64),
array([3, 2, 2, 2, 1, 1, 1, 1, 1, 1], dtype=int64))
행렬 전치 및 변형
- arr.reshape()
- arr.transpose()
- arr.T
data = np.arange(1,7).reshape(2,3)
data
>>array([[1, 2, 3],
[4, 5, 6]])
data.transpose() # 첫 번째 행을 첫 번째 열로, 두 번째 행을 두 번째 열로 바꿔준다.
#행,열 곱은 모양이 맞아야 가능하다.
>>array([[1, 4],
[2, 5],
[3, 6]])
data.T #= data.transpose()
>>array([[1, 4],
[2, 5],
[3, 6]])배열을 뒤집는 방법
- np.flip()
arr = np.array([1, 2, 3, 4, 9, 5, 6, 7, 8]) #정렬이라고 하기 보다는 뒤집기이다.
np.flip(arr)
>>array([8, 7, 6, 5, 9, 4, 3, 2, 1])
arr_2d = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
arr_2d
>>array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
np.flip(arr_2d) #1행의 1열의 값이 맨 끝 3행의 4열로 간다.
>>array([[12, 11, 10, 9],
[ 8, 7, 6, 5],
[ 4, 3, 2, 1]])
np.flip(arr_2d, axis=0)
>>array([[ 9, 10, 11, 12],
[ 5, 6, 7, 8],
[ 1, 2, 3, 4]])
np.flip(arr_2d, axis=1) #열 단위로, 0= 행 단위로
>>array([[ 4, 3, 2, 1],
[ 8, 7, 6, 5],
[12, 11, 10, 9]])
x = np.array([[1 , 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
x
>>array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])다차원 배열 형태 변경 및 병합
- .flatten()
- ravel()
.flatten() -> reshape써도 괜찮다.
ravel복사본을 생성하지 않으므로 메모리 효율적이다. (=얕은 복사)
x.flatten() #1차원
>>array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
x.reshape((1, -1)) #2차원 , -1은 있는 변수 그대로 쓰겠다. reshape도 비슷한 효과를 낼 수 있다.
>>array([[ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]])
x.reshape((1, -1))[0] #1차원
>>array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])더 많은 정보를 위해 독스트링에 접근하는 방법
- help()
- ?
- ??
doctstring = 설명서 , 단축키) shift+tab
x.reshape?
>>
Docstring:
a.reshape(shape, order='C')
Returns an array containing the same data with a new shape.
Refer to `numpy.reshape` for full documentation.
See Also
--------
numpy.reshape : equivalent function
Notes
-----
Unlike the free function `numpy.reshape`, this method on `ndarray` allows
the elements of the shape parameter to be passed in as separate arguments.
For example, ``a.reshape(10, 11)`` is equivalent to
``a.reshape((10, 11))``.
Type: builtin_function_or_method
def double(a):
'''
여기에다가 함수 설명을 적어요.
'''
return a*2
double?
>>
Signature: double(a)
Docstring: 여기에다가 함수 설명을 적어요.
File: c:\users\user\appdata\local\temp\ipykernel_15492\2464801337.py
Type: function
double??
>>
Signature: double(a)
Source:
def double(a):
'''
여기에다가 함수 설명을 적어요.
'''
return a*2
File: c:\users\user\appdata\local\temp\ipykernel_15492\2464801337.py
Type: function
수학 공식으로 작업하기
배열에서 작동하는 수학 공식을 쉽게 구현할 수 있다는 점은 NumPy가 과학 Python 커뮤니티에서 널리 사용되는 이유 중 하나입니다.
예를 들어, 다음은 평균 제곱 오차 공식(회귀를 처리하는 지도 머신 러닝 모델에서 사용되는 중심 공식)입니다.
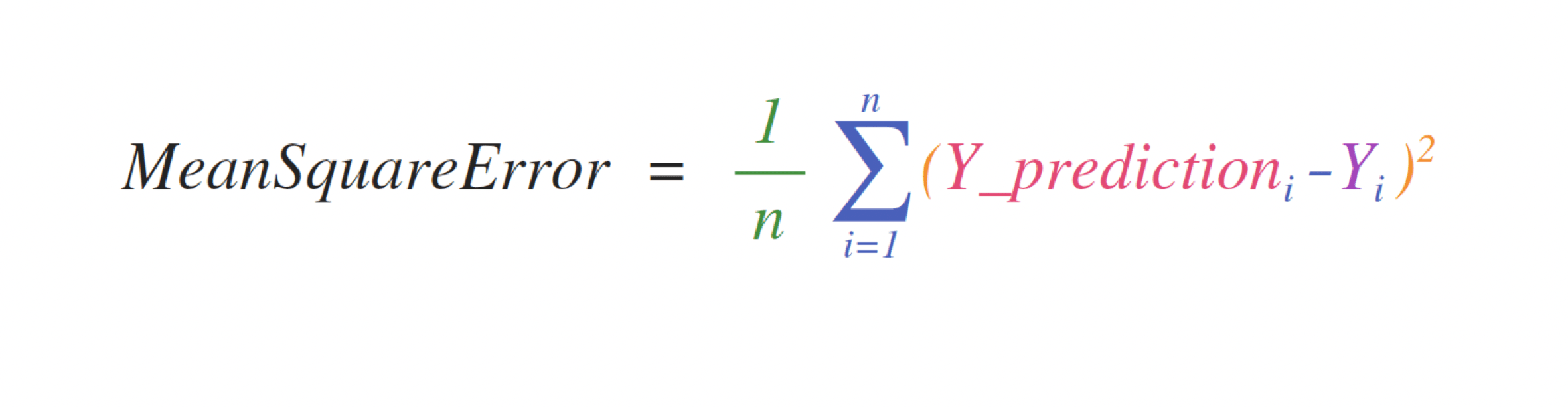
설명) y= 정답 , y_prediction =예측값,
차이값을 빼는 이유 예측한 것이 정답과 얼마나 비슷한 지 확인하기 위해서,
+-값이면 0으로 상쇄될 수 있기 때문에 제곱을 사용한다.
정답과 예측값 차이값의 제곱이 계산된다 = 하나의 수치로 뭉치기 위해서 합을 구한다.
1/n = 평균 계산
=

predictions , labels = 배열
시각화↓

NumPy 객체를 저장하고 로드하는 방법
- np.save
- np.savez
- np.savetxt
- np.loadnp
- .loadtxt
다음을 사용하여 "filename.npy"로 저장할 수 있습니다.
np.save('filename', a)
np.load()배열을 재구성 하는 데 사용할 수 있습니다.
NumPy 배열을 .csv 또는 .txt 파일과 같은 일반 텍스트 파일로 저장할 수 있습니다 np.savetxt.
np.savetxt('new_file.csv', csv_arr)
