
새싹 인공지능 응용sw 개발자 양성 교육 프로그램 심선조 강사님 수업 정리 글입니다.
목차
- n차원 배열의 선형 대수학
- pandas
원문
https://numpy.org/numpy-tutorials/content/tutorial-svd.html
1. n차원 배열의 선형 대수학
전제조건
컴퓨터에 matplotlib 및 SciPy 도 설치되어 있어야 한다.
from scipy import misc
img = misc.face()
img.ndim
>>3
img.shape
#3개 열, 1024개 있다, 이런 데이터가 768개 있다
>>(768, 1024, 3)
#이미지는 기본 가로세로가 있다. 가로 1024, 세로 768, 3개는
img.size #요소수
>>2359296
img.dtype
>>dtype('uint8')
type(img) #type은 numpy의 기본적인 형태 "ndarray" = 배열
>>numpy.ndarray
img #121, 112, 131 = rgb
#숫자값의 범위가 궁금하면 img[0,0,0] -> 121
>>array([[[121, 112, 131],
[138, 129, 148],
[153, 144, 165],
...,
[119, 126, 74],
[131, 136, 82],
[139, 144, 90]],
[[ 89, 82, 100],
[110, 103, 121],
[130, 122, 143],
...,
[118, 125, 71],
[134, 141, 87],
[146, 153, 99]],
[[ 73, 66, 84],
[ 94, 87, 105],
[115, 108, 126],
...,
[117, 126, 71],
[133, 142, 87],
[144, 153, 98]],
...,
[[ 87, 106, 76],
[ 94, 110, 81],
[107, 124, 92],
...,
[120, 158, 97],
[119, 157, 96],
[119, 158, 95]],
[[ 85, 101, 72],
[ 95, 111, 82],
[112, 127, 96],
...,
[121, 157, 96],
[120, 156, 94],
[120, 156, 94]],
[[ 85, 101, 74],
[ 97, 113, 84],
[111, 126, 97],
...,
[120, 156, 95],
[119, 155, 93],
[118, 154, 92]]], dtype=uint8)
img[0,0,0]
>>121
img[0,0, :]
>>array([121, 112, 131], dtype=uint8)
img[0,:,:]
>>array([[121, 112, 131],
[138, 129, 148],
[153, 144, 165],
...,
[119, 126, 74],
[131, 136, 82],
[139, 144, 90]], dtype=uint8)
img.max() #요소값중 가장 큰 것 , 경우의 수는 256 = 8byte로 표현, #nomalization, 데이터가 큰 값을 조정하는 것
>>255
img.min() #요소값중 가장 작은 것
>>0
학습목표
- NumPy에서 1차원, 2차원 및 n차원 배열의 차이점을 이해
- for 루프를 사용하지 않고 n차원 배열에 일부 선형 대수 연산을 적용하는 방법을 이해
- n차원 배열의 축 및 모양 속성을 이해
모양, 축 및 배열 속성
선형 대수학에서 벡터의 차원은 배열의 항목 수를 나타냅니다. NumPy에서는 대신 축 수를 정의합니다. 예를 들어 1D 배열은 와 같은 벡터 이고 2D 배열은 행렬입니다.[1, 2, 3]
import matplotlib.pyplot as plt
#matplotlib = 파이썬에서 차트를 그려주는 기본적인 라이브러리
%matplotlib inline #요즘에는 안 적어도 사진 나옴
plt.imshow(img)
plt.show
img[:,:,0] # 0= r값 (rgb)
>>array([[121, 138, 153, ..., 119, 131, 139],
[ 89, 110, 130, ..., 118, 134, 146],
[ 73, 94, 115, ..., 117, 133, 144],
...,
[ 87, 94, 107, ..., 120, 119, 119],
[ 85, 95, 112, ..., 121, 120, 120],
[ 85, 97, 111, ..., 120, 119, 118]], dtype=uint8)
img[:,:,1] # 0= g값 (rgb)
>>array([[112, 129, 144, ..., 126, 136, 144],
[ 82, 103, 122, ..., 125, 141, 153],
[ 66, 87, 108, ..., 126, 142, 153],
...,
[106, 110, 124, ..., 158, 157, 158],
[101, 111, 127, ..., 157, 156, 156],
[101, 113, 126, ..., 156, 155, 154]], dtype=uint8)
img[:,:,1].shape #이미지의 사이즈를 보여준다.
>>(768, 1024)
#조정할 때는 가장 큰 숫자 값으로 나누면 값이 조정이 된다. -> 값이 0~1사이 값으로 변함 = 그래도 사진은 차이가 없다.
img_array = img / 255
img_array.max(),img_array.min()
>>(1.0, 0.0)
plt.imshow(img_array) #값이 변했다고 달라지는 것은 없음
plt.show()
img_array.dtype #int가 255나누기 작업을 통해서 float로 변했음
>>dtype('float64')img.shape
>>(768, 1024, 3) # 3개가 나왔으니 3차원이다, channel은 열
슬라이스 구문을 사용하여 각 색상 채널을 별도의 행렬에 할당할 수 있습니다.
red_array = img_array[:, :, 0]
green_array = img_array[:, :, 1]
blue_array = img_array[:, :, 2]특이값 분해(svd)
SVD(Singular Value Decomposition)
행렬을 특정한 구조로 분해하는 방식

출처)https://ko.wikipedia.org/wiki/%ED%8A%B9%EC%9E%87%EA%B0%92_%EB%B6%84%ED%95%B4
img 1024, 768
u = 1024 768
시그마 = 1024 768 , 대각선으로만 값이 있고 나머지 값은 다 0 이다.
v = 1024 768 , 전치행렬해서 곱하면 된다.
행렬곱
@연산자 = 행렬곱
[1, 2] * 2 =[2, 2] # 스칼라값 곱할 때
-
전제조건
앞 쪽의 열값과 뒤 쪽의 행 값이 같아야 한다. -
결과
앞 쪽의 행 값과 뒤 쪽의 열값의 곱으로 나온다.
ex) 10 * 5 , 바깥쪽의 값들 곱으로 나온다.
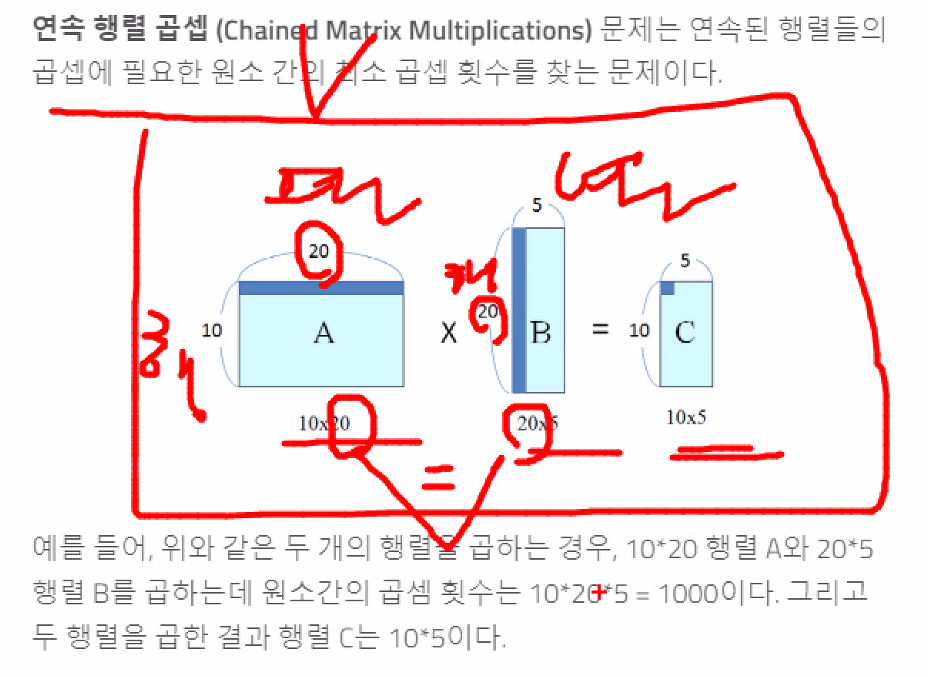 출처) https://dudri63.github.io/2019/01/28/algo20/
출처) https://dudri63.github.io/2019/01/28/algo20/
그레이스케일

img_gray.shape #그레이스케일 정보
>>(768, 1024)
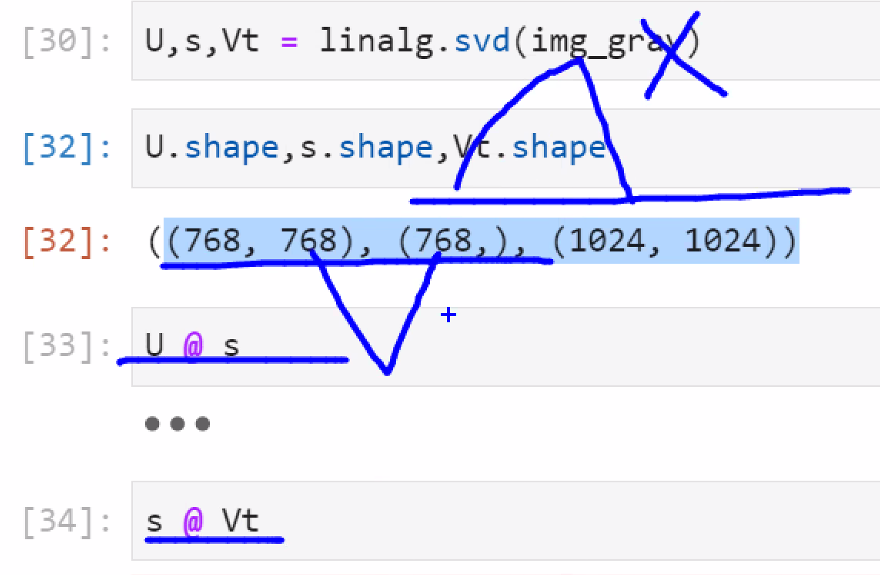
u @ s = 가능 768, 768, 같아서
u @ vt = 불가능 768, 1024 달라서
U,s,Vt = linalg.svd(img_gray)
U.shape,s.shape,Vt.shape
>>((768, 768), (768,), (1024, 1024))
#특이값 분해는 하나의 행렬이 3개의 열로 분해가 된다.
U @ s
>>array([-14.82934258, -15.64213083, -14.11270338, -11.83441097,
-11.22274112, -12.0353505 , -13.47822804, -14.71083649,
-12.81620569, -14.75900199, -16.39875751, -15.92262872,
-14.2169179 , -15.3288541 , -14.70930414, -12.08341602,
-13.22480892, -17.99291819, -18.52242787, -16.64750177,
-15.22914737, -13.38720335, -10.1227432 , -7.90847967,
-9.96630176, -12.48284105, -8.99099249, -6.41657917, 생략
# 사이즈가 안 맞아서 대각행렬을 이용해야 한다.
#((768, 768), (768,), (1024, 1024)) 768, 1024, 둘 의 값이 안 맞아서
s @ Vt
>>오류
import numpy as np
Sigma = np.zeros((U.shape[1],Vt.shape[0]))
Sigma.shape
>>(768, 1024)
np.fill_diagonal(Sigma, s) #fill= 대각선으로 값을 채움, (Sigma, s) = Sigma에 s값을 채워라
Sigma
>>array([[410.42098224, 0. , 0. , ..., 0. ,
0. , 0. ],
[ 0. , 85.56090199, 0. , ..., 0. ,
0. , 0. ],
[ 0. , 0. , 63.61066707, ..., 0. ,
0. , 0. ],
...,
[ 0. , 0. , 0. , ..., 0. ,
0. , 0. ],
[ 0. , 0. , 0. , ..., 0. ,
0. , 0. ],
[ 0. , 0. , 0. , ..., 0. ,
0. , 0. ]])
U@Sigma@Vt #원래대로 복원
>>array([[0.45209882, 0.51876549, 0.57815529, ..., 0.47355843, 0.51387529,
0.54524784],
[0.33250118, 0.41485412, 0.49104706, ..., 0.46907059, 0.53181569,
0.57887451],
[0.26975608, 0.35210902, 0.43446196, ..., 0.47104157, 0.53378667,
0.57692392],
...,
[0.39135137, 0.40982196, 0.46304078, ..., 0.5706549 , 0.56673333,
0.5692549 ],
[0.37452784, 0.41374353, 0.47675608, ..., 0.56840078, 0.56419608,
0.56419608],
[0.37509412, 0.42158667, 0.47340078, ..., 0.56447922, 0.56027451,
0.55635294]])
#특이값 분해는 값이 3개로 분해가 된다. 2. 대각선만 값이 있는 부분만 return 3. 1024 * transpose값만 return이 된다.
분해 된 것은 합칠 수 있다. 중간에 있는 값이 대각선마 있는 값을 복원할려면 대각행렬로 바꿔야 한다.
Sigma = np.zeros((U.shape[1],Vt.shape[0])) Sigma.shape 대각선으로 값으로 채우는 작업이다. np.fill_diagonal(Sigma, s) #fill= 대각선으로 값을 채움, (Sigma, s) = Sigma에 s값을 채워라
근사치
linalg.norm(img_gray - U @ Sigma @ Vt)
>> 1.4049006864018454e-12
이 값이 작으면 차이가 별로 없는 것
#원래값과 이것이 차이가 있느냐 없느냐를 체크하는 함수 2개
linalg.norm(img_gray - U@Sigma@Vt) # 결과값이 0에 가깝기 때문에 원상복구가 됬다.
>>1.4108253216554015e-12
#원래값과 이것이 차이가 있느냐 없느냐를 체크하는 함수 2개, true = 원상복구됨
np.allclose(img_gray, U @ Sigma @ Vt)
>>Ture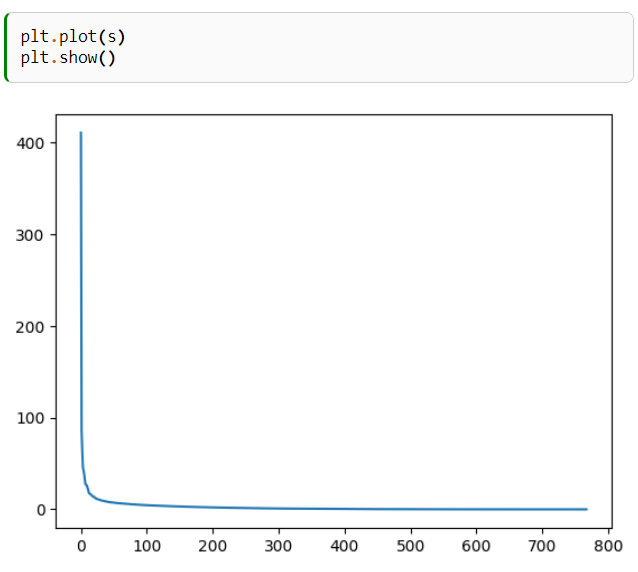
#데이터를 압축해서 쓸 수 있다는 것은
k = 500
approx = U @ Sigma[:,:k] @ Vt[:k,:]#u =768 @뒤가 1024, 열은 768개 사용하고 행은 10개만 사용하겠다 , ;=전부다
plt.imshow(approx,cmap='gray')
plt.show
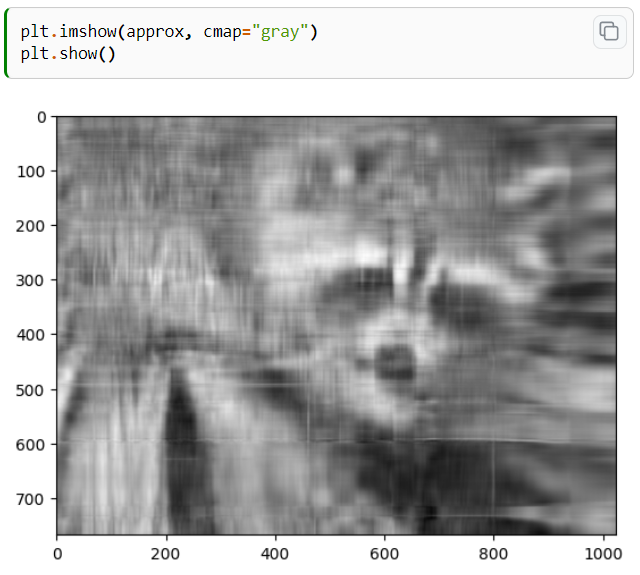
numpy.linalg
NumPy의 선형 대수 모듈인 numpy.linalg 를 사용하여 수행
이 모듈의 대부분의 선형 대수 함수는 scipy.linalg 에서도 찾을 수 있으며 사용자는 실제 응용 프로그램에 scipy 모듈을 사용하는 것이 좋습니다.
from numpy import linalg # 특이값 분해 svd, linalg= 선형대수학
img_gray = img_array @ [0.2126, 0.7152, 0.0722] #컬럼값으로 그레이스케일로 바꾸는 공식, 컬럼 -> 그레이스케일
- linalg.norm
numpy.linalg.norm
linalg.norm ( x , ord = 없음 , axis = 없음 , keepdims = False )
행렬 또는 벡터 노름.
이 함수는 매개변수의 값에 따라 8개의 서로 다른 행렬 노름 중 하나 또는 무한한 수의 벡터 노름(아래 설명) 중 하나를 반환할 수 있다.
- 정규화 노름
벡터값에 절대값을 입혀서 차이 값을 구하거나, 제곱을 해서 차이 값을 구하는 것
벡터값 사이의 차이를 구하기 위해서 사용
@sigma와 @vt값을 빼서
분해된 것은 복원할 떄 모든 데이터가 필요한 것이 아니라 일부 데이터만 있어도 가능하다.
특이값 분해를 우리가 직접하지는 않지만 어떻게 작동하는 지만 알기.
이미지불러오기
from PIL import Image
img_path = 'img01.jpg'
img = Image.open(img_path).convert('L') #).convert('L') = 그레스이스케일
plt.imshow(img)
plt.show()
type(img)
>>numpy.ndarray
img
>>array([[[121, 112, 131],
[138, 129, 148],
[153, 144, 165],
...,
[119, 126, 74],
[131, 136, 82],
[139, 144, 90]], 생략
np.array(img)
>>array([[[121, 112, 131],
[138, 129, 148],
[153, 144, 165],
...,
[119, 126, 74],
[131, 136, 82],
[139, 144, 90]], 생략
np.array(img)
>>array([[[121, 112, 131],
[138, 129, 148],
[153, 144, 165],
...,
[119, 126, 74],
[131, 136, 82],
[139, 144, 90]], 생략
import cv2
img = cv2.imread(img_path)
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
img
array([[[121, 152, 181],
[120, 151, 180],
[120, 151, 180],
...,
[113, 146, 177],
[113, 146, 177],
[113, 146, 177]], 생략

2. pandas
csv - ,으로 구분된 파일
tsv - tab으로 구분된 파일
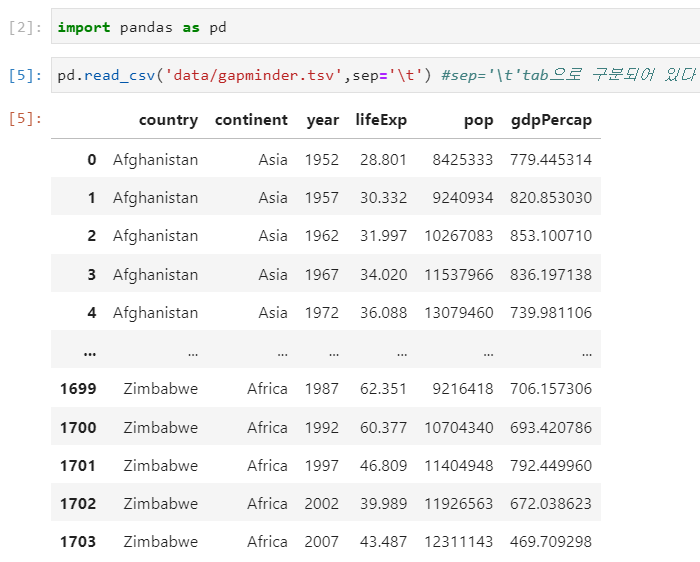
pandas의 기본 베이스는 numpy이다
import pandas as pd
df = pd.read_csv('data/gapminder.tsv',sep='\t') #sep='\t'tab으로 구분되어 있다
type(df)
>>pandas.core.frame.DataFrame
dataframe의 기본구조
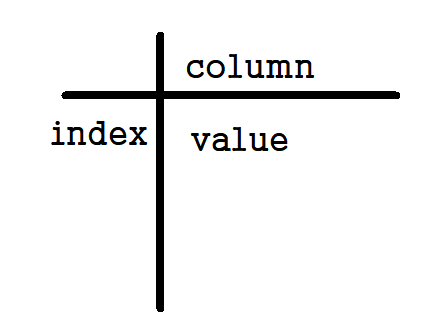
시리즈와 데이터프레임
시리즈 : 열, 같은 종류의 data
데이터프레임 : 시리즈들이 각 요소가 되는 딕셔너리
print(df.head(5))
>>
country continent year lifeExp pop gdpPercap
0 Afghanistan Asia 1952 28.801 8425333 779.445314
1 Afghanistan Asia 1957 30.332 9240934 820.853030
2 Afghanistan Asia 1962 31.997 10267083 853.100710
3 Afghanistan Asia 1967 34.020 11537966 836.197138
4 Afghanistan Asia 1972 36.088 13079460 739.981106
print(df.head(2)) #위에서 5개
>>
country continent year lifeExp pop gdpPercap
0 Afghanistan Asia 1952 28.801 8425333 779.445314
1 Afghanistan Asia 1957 30.332 9240934 820.853030
df.shape
>>(1704, 6)
df.size
>>10224
df.ndim
>>2
df.columns
데이터 프레임의 열이름을 보여준다.
df.columns
>>Index(['country', 'continent', 'year', 'lifeExp', 'pop', 'gdpPercap'], dtype='object')
df.index #일련번호가 잇다.
>>RangeIndex(start=0, stop=1704, step=1)
df.values
>>array([['Afghanistan', 'Asia', 1952, 28.801, 8425333, 779.4453145],
['Afghanistan', 'Asia', 1957, 30.332, 9240934, 820.8530296],
['Afghanistan', 'Asia', 1962, 31.997, 10267083, 853.10071],
...,
['Zimbabwe', 'Africa', 1997, 46.809, 11404948, 792.4499603],
['Zimbabwe', 'Africa', 2002, 39.989, 11926563, 672.0386227],
['Zimbabwe', 'Africa', 2007, 43.487, 12311143, 469.7092981]],
dtype=object)
df.dtypes #numpy는 한 종류의 타입만 올 수 있다. df는 열마다 다른 타입도 가능하다. #컬럼이름, 타입명, object = str
>>country object
continent object
year int64
lifeExp float64
pop int64
gdpPercap float64
dtype: object
df.info() # RangeIndex: 1704 entries, 0 to 1703 = null값이 없다
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1704 entries, 0 to 1703
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 country 1704 non-null object
1 continent 1704 non-null object
2 year 1704 non-null int64
3 lifeExp 1704 non-null float64
4 pop 1704 non-null int64
5 gdpPercap 1704 non-null float64
dtypes: float64(2), int64(2), object(2)
memory usage: 80.0+ KB
데이터 추출하기
- 열단위 데이터 추출하기
df['country']
>>
0 Afghanistan
1 Afghanistan
2 Afghanistan
3 Afghanistan
4 Afghanistan
...
1699 Zimbabwe
1700 Zimbabwe
1701 Zimbabwe
1702 Zimbabwe
1703 Zimbabwe
Name: country, Length: 1704, dtype: object
type(df['country']) #Series = 데이터 타입
>>pandas.core.series.Series
df['country'].head()
>>
0 Afghanistan
1 Afghanistan
2 Afghanistan
3 Afghanistan
4 Afghanistan
Name: country, dtype: object
df['country'].tail()
>>
1699 Zimbabwe
1700 Zimbabwe
1701 Zimbabwe
1702 Zimbabwe
1703 Zimbabwe
Name: country, dtype: object
df['country'].sample(2)
>>
22 Albania
1407 South Africa
Name: country, dtype: object
loc
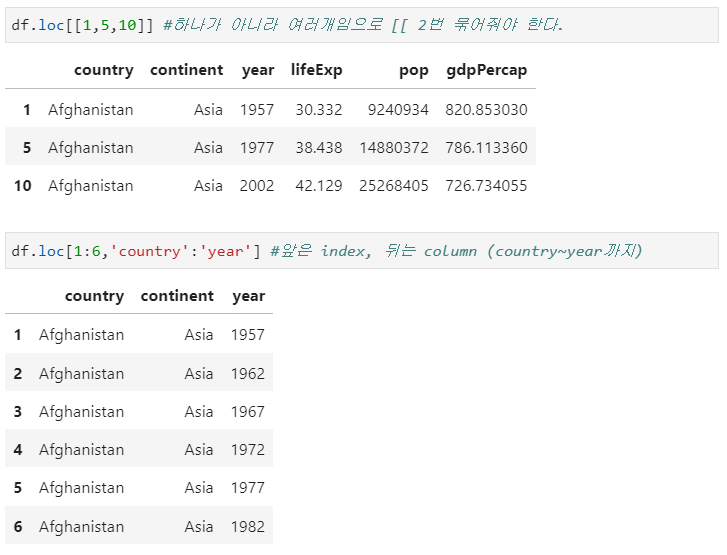
loc: 인덱스를 전달하면 행 단위로 데이터 추출, 부여된 명칭으로 불러야 한다.
iloc: 특정 열 값 추출 (i = index)
df.loc[0] #첫번째 인덱스 값을 가져와라 # 한 행만 가져와서 series형태로 출력, pandas처럼 표형식으로 출력 안 됨
>>
country Afghanistan
continent Asia
year 1952
lifeExp 28.801
pop 8425333
gdpPercap 779.445314
Name: 0, dtype: object
df.iloc[-1] #loc는 부여된 이름이라서 -1은 index인 iloc만 가능하다.
>>
country Zimbabwe
continent Africa
year 2007
lifeExp 43.487
pop 12311143
gdpPercap 469.709298
Name: 1703, dtype: objectS
df.iloc[0] #첫 번째 행의 값을 가져와라
>>
country Afghanistan
continent Asia
year 1952
lifeExp 28.801
pop 8425333
gdpPercap 779.445314
Name: 0, dtype: object
df.iloc[0,0] #첫 번째 행의 첫 번째 열의 값을 가져와라
>>'Afghanistan'
df.iloc[-1]
>>country Zimbabwe
continent Africa
year 2007
lifeExp 43.487
pop 12311143
gdpPercap 469.709298
Name: 1703, dtype: object
나만의 데이터 만들기
import pandas as pd
s = pd.Series(['banana',42])
s
>>
0 banana
1 42
dtype: object
s = pd.Series(['Wes','pandas'],index=['person','who']) # index=['person','who'] = index이름 설정
s
>>
person Wes
who pandas
dtype: object
scientists = pd.DataFrame({
'Name':['rosa','will'],
'occupation':['chemist', 'Statistician'],
'Born':['1920-07-25', '1876-06-13'],
'Died':['1958-04-16', '1937-10-16'],
'Age':[37, 61]}
)
print(scientists)
>>
Name occupation Born Died Age
0 rosa chemist 1920-07-25 1958-04-16 37
1 will Statistician 1876-06-13 1937-10-16 61
시리즈 다루기
df = pd.read_csv('data/scientists.csv')
df.index
>>RangeIndex(start=0, stop=8, step=1)
df.columns
>>Index(['Name', 'Born', 'Died', 'Age', 'Occupation'], dtype='object')
df.values
>>array([['Rosaline Franklin', '1920-07-25', '1958-04-16', 37, 'Chemist'],
['William Gosset', '1876-06-13', '1937-10-16', 61, 'Statistician'],
['Florence Nightingale', '1820-05-12', '1910-08-13', 90, 'Nurse'],
['Marie Curie', '1867-11-07', '1934-07-04', 66, 'Chemist'],
['Rachel Carson', '1907-05-27', '1964-04-14', 56, 'Biologist'],
['John Snow', '1813-03-15', '1858-06-16', 45, 'Physician'],
['Alan Turing', '1912-06-23', '1954-06-07', 41,
'Computer Scientist'],
['Johann Gauss', '1777-04-30', '1855-02-23', 77, 'Mathematician']],
dtype=object)
df.keys() #columns와 결과값은 같지만 columns는 속성이라 ()안 쓰지만 keys는 매소드라 ()사용
>>Index(['Name', 'Born', 'Died', 'Age', 'Occupation'], dtype='object')
#시리즈의 기초 통계 메서드 사용하기
#mean = 평균, max,min,std= 표준편차
df['Age']
>>0 37
1 61
2 90
3 66
4 56
5 45
6 41
7 77
Name: Age, dtype: int64
df['Age'].mean()
>>59.125
df.describe() #숫자형은 Age뿐이라서 Age만 나옴
>>Age
count 8.000000
mean 59.125000
std 18.325918
min 37.000000
25% 44.000000
50% 58.500000
75% 68.750000
max 90.000000
- 함수정리
append: 2개 이상의 시리즈 연결
describe: 요약 통계량 계산
drop_duplicates: 중복값이 없는 시리즈 반환
isin: 시리즈에 포함된 값이 있는지 확인
median: 중갑값 반환, 먼저 값을 순서대로 일렬로 나열하고 중간값 출력, 값이 짝수개라면 두 개 값의 평균값을 출력한다.
replace: 특정 값을 가진 시리즈 값을 교체
sort_values: 값을 정렬
to_frame: return되는 값은 dataframe으로 반환할 때
