캐시 메모리
-
캐시 메모리는 CPU의 처리속도와 주기억장치의 접근 속도 차이를 줄이기 위해 사용하는 고속 Buffer Memory임, 이를 통해 전체 시스템의 성능을 개선 시킬 수 있음
-
캐시는 잠시 저장해둔다는 의미이고 기능이라고 볼 수 있음
-
주기억장치와 CPU사이에 위치하며 자주 사용하는 프로그램과 데이터를 기억함
-
메모리 계층 구조에서 빠른 소자에 속하며, 처리속도가 거의 CPU의 속도와 비슷할 정도임
-
캐시메모리를 사용하면 주기억장치를 접근하는 횟수가 줄어들어 컴퓨터의 처리속도가 향상됨
-
빠른 CPU 처리 속도와 상대적으로 느린 메인 메모리에서의 속도의 차이를 극복하는 역할을 함
캐시 적중과 실패
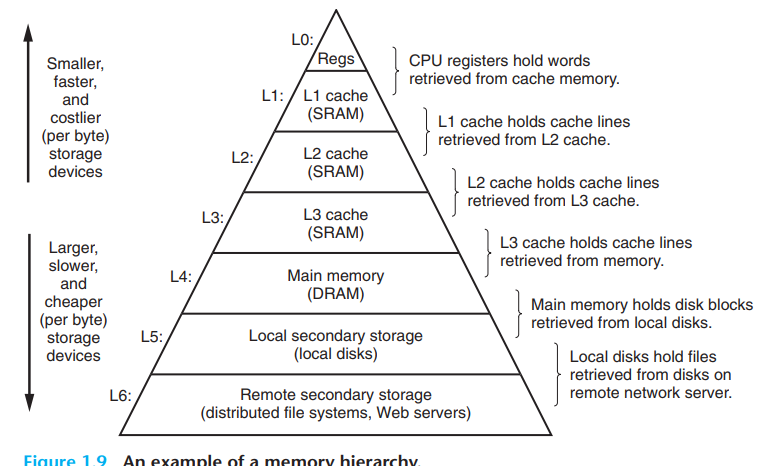
-
위의 구조에서 CPU는 L1,L2,L3 캐시에 접근해서 데이터를 찾음
-
만약 여기서 필요한 데이터가 있는 경우 적중(hit), 없는 경우 실패(miss)라고 함, 이를 통해 적중률 계산이 가능하고, 캐시 메모리의 성능은 이 적중률에 의해 결정됨
-
CPU에서 데이터를 가져오기 위해서
캐시 메모리 -> 메모리 -> 보조기억장치순으로 접근을 함 -
캐시 적중일 경우 캐시 메모리의 데이터를 CPU 레지스터에 복사함
-
캐시 실패, 메모리 적중일 때 메모리의 데이터를 캐시 메모리에 복사하고, 캐시 메모리의 복재된 내용을 CPU 레지스터에 복사함
-
캐시, 메모리 실패일 때 보조기억장치에서 필요한 데이터를 메모리에 복사함, 메모리에 복재된 내용을 캐시 메모리에 복제함, 캐시 메모리의 복재된 데이터를 CPU 레지스터에 복사함
-
캐시메모리의 용량은 적기 때문에 일부만 적재할 수 있다는 사항을 알고 있어야 함
지역성
-
캐시 메모리는 지역성이라는 특징이 있는데, 이 지역성은 프로세스들이 기억장치 내의 정보를 균일하게 액세스 하는 것이 아니라 어느순간에 특정부분을 집중적으로 참조하는 것을 말함
-
이 특징은 메모리의 위치와 접근 시간에 따라서 공간적, 시간적인 특성을 보임
-
이 지역성은 어디까지나 경향에 대한 것이미지 항상 캐시의 높은 적중률을 보장해주진 않음
공간적 지역성
-
CPU가 참조한 데이터와 인접한 데이터 역시 참조될 가능성이 높음
-
예를 들어서 배열을 생각할 때 일정한 메모리 공간을 순차적으로 할당받아 사용하는데, 공간할당을 연속적으로 받게됨, 이 연속적으로 받게 된 메모리가 사용되어 질 때, 연속적으로 사용되어질 가능성이 높은 것을 의미함
시간적 지역성
-
CPU가 한 번 참조한 데이터는 다시 참조할 가능성이 높음
-
예를 들어서 반복문을 수행하면 특정 메모리값으로 선언된 부분을 반복하여서 접근하게 됨, 방금 전에 접근했던 메모리를 다시 참고하게 될 확률이 높아지는 것을 시간적 지역성이라고 함
순차적 지역성
- 분기가 발생하지 않는 한 명령어는 메모리에 저장된 순서대로 인출, 실행됨
캐시 쓰기 정책
-
캐시에 저장되어 있는 데이터에 수정이 발생했을 때, 그 수정된 내용을 주기억장치에 갱신하기 위해 시기와 방법을 결정하는 것을 말함
-
이는 CPU에서 메모리에 읽기 요청을 하게 되면 먼저 캐시에 그 해당 데이터가 있는지 확인을 함, 이 과정에서 그 데이터가 있는 경우 Hit했다고 하여 그 해당 데이터를 가져옴
-
이 Hit를 위해서 어떤 방식으로 어떤 데이터를 적재해둘 것인가가 Hit율을 좌우하고 성능을 좌우함, 그래서 쓰기 정책도 고려를 해야함
Write Through 방식
-
캐시에 쓰기 동작이 이루어질 때마다 캐시 메모리와 주기억장치의 내용을 동시에 갱신하므로 쓰기 동작에 걸리는 시간이 가장 김
-
이 경우 그 구조가 단순하고, 메모리와 캐시의 데이터를 동일하게 유지하는 데 별도의 신경을 쓰지 않아도 되서 자주 씀
-
동작에 걸리는 시간이 긴 단점이 있지만, 실제 프로그램에서 메모리 참조 시 쓰기에 대한 작업을 그렇게 많이 쓰이지 않아서 자주 씀
Write Back 방식
-
캐시에 쓰기 동작이 이루어지는 동안은 캐시의 내용만이 갱신되고, 캐시의 내용이 캐시로부터 제거될 때 주기억장치에 복사됨
-
이렇게 되면 동일한 블록 내에 여러 번 쓰기를 실행하는 경우 캐시에만 여러 번 쓰기를 하고 메인 메모리에는 한 번 만 쓰게 되므로 효율적으로 동작하게 됨
-
블록은 데이터의 기본 단위인 워드의 집합임
Write Once 방식
- 캐시에 쓰기 동작이 이루어질 때 한 번만 기록하고 이후의 기록은 모두 무시함
블록?
블록
이 블록은 데이터가 동시에 이동하는 정보 단위이고 한 블록은 보통 2의 거듭제곱 수를 갯수로 하는 워드의 집합임
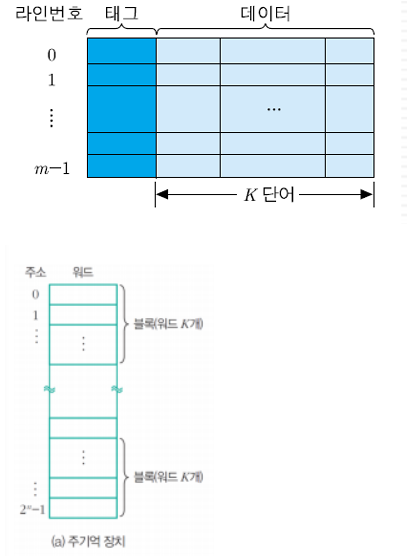
여기서 라인은 캐시에서 각 블록이 저장되는 장소이고 태그는 라인에 적재된 블록을 구분해주는 정보임
캐시메모리의 매핑 프로세스
- 주기억장치로부터 캐시 메모리로 데이터를 전송하는 방법을 말함
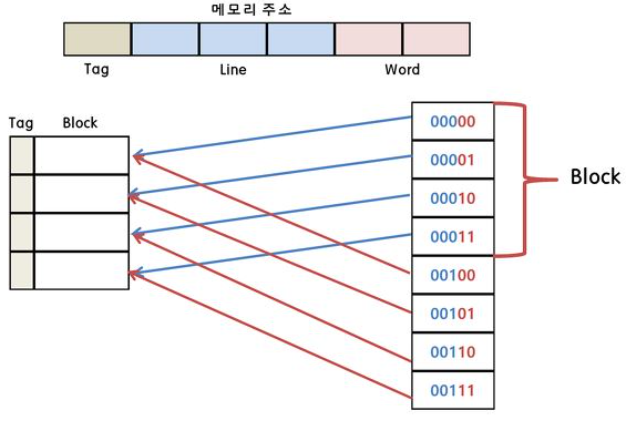
직접 매핑(Direct Mapping)
-
주기억장치의 블록들이 지정된 한 개의 캐시라인으로만 매핑될 수 있는 방법임
-
주기억장치를 일정한 크기의 블록으로 나누고 각각의 블록을 캐시의 정해진 위치에 매핑하는 것
-
간단하고 구현하는 비용이 적게드는 장점이 있지만, 적중률이 낮아질 수 있다는 단점이 있음
-
예를 들어 아래와 같이 지정된 데이터를 동일하게 매핑을 하게끔 할 수 있음
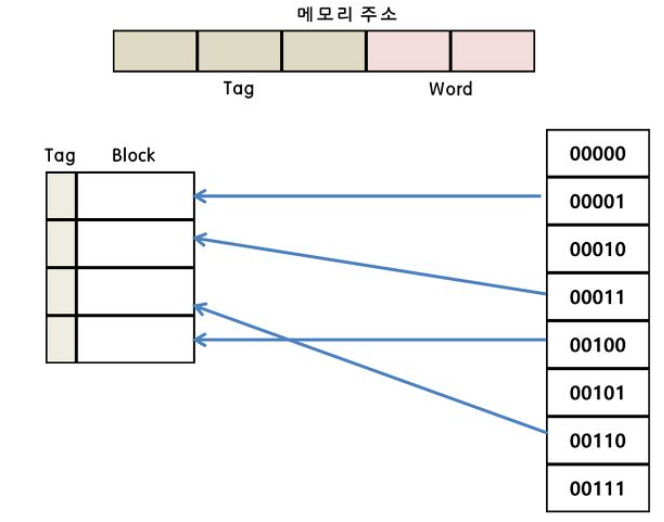
Associative Mapping
-
직접 매핑 방식의 단점을 보완한 방식임, 캐시의 태그 필드를 확장하여 캐시의 어떤 라인과도 무관하게 매핑시킬 수 있음
-
모든 태그들을 병렬로 검사하여 복잡하고 비용이 높다는 단점이 있음
Set-Associative Mapping
-
직접 매핑과 연관 매핑의 장점만을 취한 방식임
-
Associative Mapping의 장점을 가지고 단점을 줄이는 방안을 택한 것, 많은 마이크로프로세서들이 이 방식을 택함
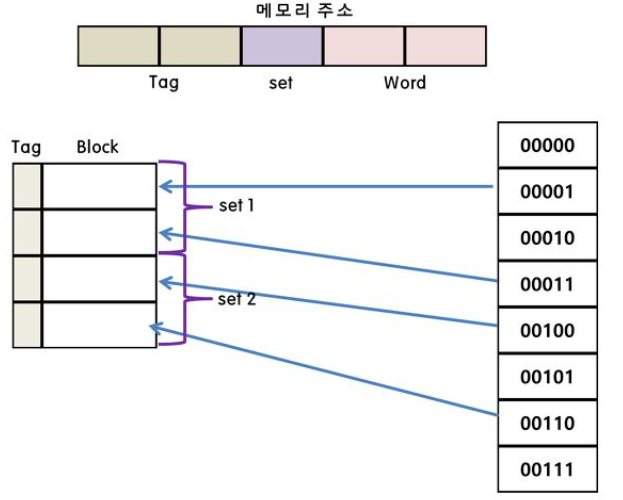
이 매핑 방식의 경우 캐시에 따라서 그리고 상황에 따라서 설계자에 의해 채택이 됨, 그리고 단순하게 단일한 방식을 취하는 것이 아닌 여러가지 방식이 채택되는 것, 이것은 CPU 설계나 만들때 정해지는 것(설계자에 의해)
