Pandas는 빅데이터분석기사 실기 준비하면서 꽤 익숙해진 상태라 헷갈리는 것들 위주로 정리
여기서 사용하는 코드는 titanic 데이터셋을 기반으로 작성됨
Pandas 개요
pandas는 2차원 데이터를 효율적으로 가공/처리가 가능함, 정형 데이터 다루기 좋음
| DataFrame | Series |
|---|---|
| 2차원 | 1차원 |
| 칼럼명 O | 칼럼명 X |
칼럼명이 있으면 무조건 DataFrame !
DataFrame과 상호 변환
| 변환 형태 | 설명 |
|---|---|
| list -> DataFrame | pd.DataFrame(list, columns=col_name1) DataFrame 생성 인자로 list 객체와 매핑되는 칼럼명들 입력 |
| ndarray -> DataFrame | pd.DataFrame(array2, columns=col_name2) DataFrame 생성 인자로 ndarray와 매핑되는 칼럼명들 입력 |
| dict -> DataFrame | dict = {'col1':[1, 11], 'col2':[2, 22], 'col3':[3, 33]} df_dict = pd.DataFrame(dict) key가 칼럼명이 되고, value가 값이 됨 |
| DataFrame -> ndarray | df.values 하면 됨 |
| DataFrame -> list | df.values.tolist() 하면 됨 |
| DataFrame -> dict | df.to_dict() 하면 됨 |
sort_values()
DataFrame, Series 정렬에 사용함
df.sort_values(by=['Name']) # 오름차순
df.sort_values(by=['Name'], ascending=False) # 내림차순
df.sort_values(by=['Pclass', 'Name'], ascending=False)by 인자에 둘 이상의 칼럼명도 넣을 수 있음
groupby와 aggregation
groupby는 SQL의 그것을 생각하면 됨
aggregation은count(),mean(),max(),min()등의 집계 함수들을 통칭하는 것
주로 둘을 연계해서 사용함
groupby의 반환값은 DataFrameGroupBy 객체이다! (아래 예시)
df_groupby = df.groupby(by='Pclass')
print(type(df__groupby))<class 'pandas.core.groupby.groupby.DataFrameGroupBy'>그런데 DataFrameGroupBy 객체에 aggregation 함수를 사용하면 다시 DataFrame이 된다!
titanic_groupby = titanic_df.groupby('Pclass')[['PassengerId', 'Survived']].count()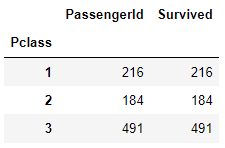
둘 이상의 aggregation을 동시에 하고 싶으면
agg()함수를 사용한다.
titanic_df.groupby('Pclass')['Age'].agg([max, min])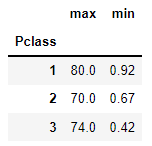
각각 칼럼에 aggregation을 따로 해주고 싶을 때는
Dictionary를 사용한다. (예시 1)
그런데, 한 칼럼에 대해 두 개 이상의 aggregation을 사용하면 마지막 것만 적용된다. (예시 2)
이럴 때는Named Aggregation을 사용하면 된다. (예시 3)
# 예시 1
agg_format={'Age':'max', 'Fare':'mean'}
titanic_df.groupby('Pclass').agg(agg_format)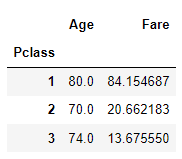
# 예시 2
agg_format={'Age':'max', 'Age':'sum', 'Fare':'mean'}
titanic_df.groupby('Pclass').agg(agg_format)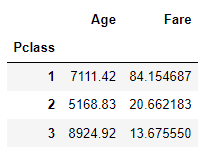
# 예시 3
titanic_df.groupby(['Pclass']).agg(age_max=('Age', 'max'), age_mean=('Age', 'mean'), fare_mean=('Fare', 'mean'))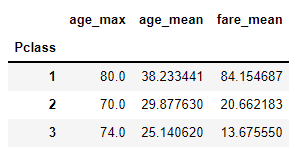
nunique()
해당 칼럼에 unique 값이 총 몇 개인지를 보여주는 것임
아래 예시를 보면 Pclass의 unique가 3, 1, 2 으로 3개니까 nunique는 3인 것을 확인하자
print(titanic_df['Pclass'].unique())
print(titanic_df['Pclass'].nunique())[3 1 2]
3lambda식 적용하기
lambda식: 함수를 간결하게 표현하려고 사용
일반 함수와 lambda식 비교
# 일반 함수
def get_square(a):
return a**2
print('3의 제곱은:',get_square(3))# lambda식
lambda_square = lambda x : x ** 2
print('3의 제곱은:',lambda_square(3))DataFrame에서
apply함수와 결합하여 lambda식으로 바로 함수 적용하기
# 예시 1
titanic_df['Name_len']= titanic_df['Name'].apply(lambda x : len(x))
titanic_df[['Name','Name_len']].head(3)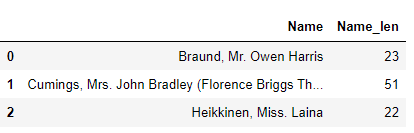
# 예시 2
titanic_df['Child_Adult'] = titanic_df['Age'].apply(lambda x : 'Child' if x <=15 else 'Adult')
titanic_df[['Age','Child_Adult']].head(8)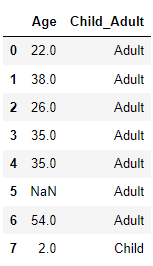
elif는 사용 불가로 알고 있음
elif기능을 사용하려면 아래처럼중첩 else를 사용하면 된다.
# 예시 3
titanic_df['Age_cat'] = titanic_df['Age'].apply(lambda x : 'Child' if x<=15 else ('Adult' if x <= 60 else 'Elderly'))
titanic_df['Age_cat'].value_counts()Child 83
Elderly 22
Name: Age_cat, dtype: int64Pandas 최종 정리
- 2차원 데이터 핸들링은 Pandas를 사용해라!
- 모든 Pandas API를 사용하려면 너무 많아서 지침, 필요한 기능 먼저 공부하기!
- 이정도만 하고 데이터 분석하다가 막히는 것들을 구글링으로 채우기!
