데이터 개요와 중점 사항
신용카드 사기 예측 데이터
- 2013년 European Card 사용 트랜잭션을 가공하여 생성
- 불균형 되어 있는 데이터 셋. 284,807건의 데이터 중 492건이 Fraud (전체의 0.172%)
데이터 출처: https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud
중점 사항
1. Feature Engineering
- 중요 Feature의 데이터 분포도 변경 (정규분포, Log 변환)
- SMOTE 오버 샘플링 (사기 데이터 건 수 증식)
- 이상치 제거
- ML Algorithm
- Logistic Regression
- LightGBM
Log 변환?
-> 왜곡된 분포도를 가진 데이터 세트를 비교적 정규 분포에 가깝게 변환해주는 Feature Engineering 방식
SMOTE 오버 샘플링?
- 레이블이 불균형한 분포를 가진 데이터를 학습 시, 이상 레이블을 가지는 데이터 건수가 매우 적어 제대로된 유형의 학습이 어려움
- 반면에 정상 레이블을 가지는 데이터 건수는 매우 많아 일방적으로 정상 레이블로 치우친 학습을 수행하여, 제대로 된 이상 데이터 검출이 어려움
- 대표적으로 오버 샘플링, 언더 샘플링 방법을 통해 적절한 학습 데이터를 확보함
오버 샘플링: 적은 레이블을 가진 데이터 세트를 많은 레이블을 가진 데이터 세트 수준으로 증식
언더 샘플링: 많은 레이블을 가진 데이터 세트를 적은 레이블을 가진 데이터 세트 수준으로 감소 샘플링
SMOTE: 원본데이터 -> K 최근접 이웃으로 데이터 신규 증식 -> 신규 증식하여 오버 샘플링
데이터 일차 가공
데이터 로드 후 확인
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
card_df = pd.read_csv('./creditcard.csv')
card_df.head(3)
...
아무래도 개인정보가 민감한 데이터라 사전에 차원 축소 기법으로 데이터가 암호화 되어있음
card_df.shape(284807, 31)
데이터를 전처리 하는
get_preprocessed_df()함수를 만듦
원본 데이터는 복사용으로 계속 유지하고 카피 데이터만 사용
이 함수는 전처리 과정을 거치면서 계속 업데이트할 것임
우선 예측에 필요 없는Time칼럼을 날림
from sklearn.model_selection import train_test_split
def get_preprocessed_df(df=None):
df_copy = df.copy()
df_copy.drop('Time', axis=1, inplace=True)
return df_copyFeature와 Label을 나누고, train과 test를 나누는 함수를 만듦
그리고 실행까지 하기
def get_train_test_dataset(df=None):
df_copy = get_preprocessed_df(df)
X_features = df_copy.iloc[:,:-1]
y_target = df_copy.iloc[:,-1]
X_train, X_test, y_train, y_test = train_test_split(X_features, y_target, test_size=0.3, random_state=0, stratify=y_target)
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = get_train_test_dataset(card_df)각 데이터세트의 Label 비율 확인
print("학습 데이터 레이블 값 비율")
print(y_train.value_counts()/y_train.shape[0]*100)
print("테스트 데이터 레이블 값 비율")
print(y_test.value_counts()/y_test.shape[0]*100)학습 데이터 레이블 값 비율
0 99.827451
1 0.172549
Name: Class, dtype: float64
테스트 데이터 레이블 값 비율
0 99.826785
1 0.173215
Name: Class, dtype: float64
stratify를 사용해서 train, test 균일하게 나눔
굉장히 불균등한 데이터임을 확인할 수 있음
1 비율이 17%가 아니라 0.17%임
앞에서 많이 만들었던 평가 지표 출력하는
get_clf_eval함수 만듦
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
def get_clf_eval(y_test, pred=None, pred_proba=None):
confusion = confusion_matrix( y_test, pred)
accuracy = accuracy_score(y_test , pred)
precision = precision_score(y_test , pred)
recall = recall_score(y_test , pred)
f1 = f1_score(y_test,pred)
roc_auc = roc_auc_score(y_test, pred_proba)
print('오차 행렬')
print(confusion)
print('정확도: {0:.4f}, 정밀도: {1:.4f}, 재현율: {2:.4f},\
F1: {3:.4f}, AUC:{4:.4f}'.format(accuracy, precision, recall, f1, roc_auc))max_iter만 설정한 LogisticRegression으로 예측까지 진행한 후 평가지표 확인
from sklearn.linear_model import LogisticRegression
lr_clf = LogisticRegression(max_iter = 1000, solver='liblinear')
lr_clf.fit(X_train, y_train)
lr_pred = lr_clf.predict(X_test)
lr_pred_proba = lr_clf.predict_proba(X_test)[:,1]
get_clf_eval(y_test, lr_pred, lr_pred_proba)오차 행렬
[[85282 13]
[ 58 90]]
정확도: 0.9992, 정밀도: 0.8738, 재현율: 0.6081, F1: 0.7171, AUC:0.9709불균일한 데이터여서 정확도는 의미가 없음
신용카드 사기 예측 특성상 재현율이 중요한 지표임
앞으로 fit에서 예측까지 여러번 수행할 것이기 때문에 이것을
get_model_train_eval함수로 만듦
def get_model_train_eval(model, ftr_train=None, ftr_test=None, tgt_train=None, tgt_test=None):
model.fit(ftr_train, tgt_train)
pred = model.predict(ftr_test)
pred_proba = model.predict_proba(ftr_test)[:,1]
get_clf_eval(tgt_test, pred, pred_proba)이번엔 LigthGBM으로 예측까지 진행
여기서boost_from_average는 기본값이 True로 되어있는데, 그렇게 할 경우 불균일한 데이터에서 평가지표가 굉장히 나쁘게 나옴
일반적인 데이터에서는 True로 해도 상관 없는데, 이런 데이터에서는 False로 설정해주기
from lightgbm import LGBMClassifier
lgbm_clf = LGBMClassifier(n_estimators = 1000, num_leaves=64, n_jobs=-1, boost_from_average = False)
get_model_train_eval(lgbm_clf, ftr_train=X_train, ftr_test=X_test, tgt_train=y_train, tgt_test = y_test)오차 행렬
[[85290 5]
[ 36 112]]
정확도: 0.9995, 정밀도: 0.9573, 재현율: 0.7568, F1: 0.8453, AUC:0.9790LogisticRegression보다 LightGBM이 훨씬 잘 나옴
데이터 분포도 변환
스케일링이 안 되어있는 Amount 칼럼의 분포를 히스토그램으로 확인해보자
import seaborn as sns
plt.figure(figsize=(8, 4))
plt.xticks(range(0, 30000, 1000), rotation=60)
sns.histplot(card_df['Amount'], bins=100, kde=True)
plt.show()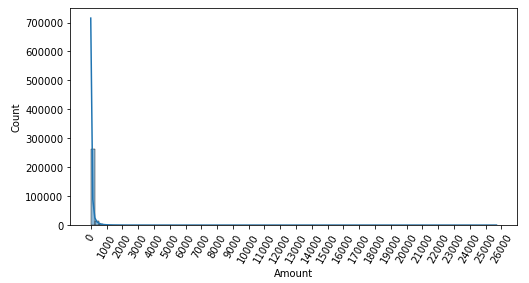
아무래도 카드 결제의 대부분은 소액 결제로 이루어지고, 큰 금액의 결제는 특별한 일이 있을 때만 이루어질 것이다.
그래서 낮은 금액에 빈도가 몰려있는 것을 확인할 수 있다.
Amount에 대해서 Standard 스케일링을 진행하자
get_preprocessed_df()함수를 업데이트한다.
Amount를 스케일링한 칼럼을 추가하고 기존 Amount는 삭제
from sklearn.preprocessing import StandardScaler
def get_preprocessed_df(df=None):
df_copy = df.copy()
# 추가
scaler = StandardScaler()
amount_n = scaler.fit_transform(df_copy['Amount'].values.reshape(-1,1))
df_copy.insert(0, 'Amount_Scaled', amount_n)
df_copy.drop(['Time', 'Amount'], axis=1, inplace=True)
return df_copy스케일링까지 진행한 데이터로 성능을 다시 예측해본다.
X_train, X_test, y_train, y_test = get_train_test_dataset(card_df)
print('### 로지스틱 회귀 예측 성능 ###')
lr_clf = LogisticRegression(max_iter=1000)
get_model_train_eval(lr_clf, ftr_train=X_train, ftr_test=X_test, tgt_train=y_train, tgt_test=y_test)
print('### LightGBM 예측 성능 ###')
lgbm_clf = LGBMClassifier(n_estimators=1000, num_leaves=64, n_jobs=-1, boost_from_average=False)
get_model_train_eval(lgbm_clf, ftr_train=X_train, ftr_test=X_test, tgt_train=y_train, tgt_test=y_test)### 로지스틱 회귀 예측 성능 ###
오차 행렬
[[85281 14]
[ 58 90]]
정확도: 0.9992, 정밀도: 0.8654, 재현율: 0.6081, F1: 0.7143, AUC:0.9702
### LightGBM 예측 성능 ###
오차 행렬
[[85290 5]
[ 37 111]]
정확도: 0.9995, 정밀도: 0.9569, 재현율: 0.7500, F1: 0.8409, AUC:0.9779오히려 더 안 좋게 나옴, 스케일링이 효과가 없나보다.
스케일링은 하지 않고, log 변환을 진행해보자
Amount 칼럼에 대해 log1p를 이용한다.
log1p는 데이터를 라고 했을 때 값으로 변환한다.
1을 더해주는 건 값이 나오는 걸 방지하는 거다.
get_preprocessed_df()업데이트
def get_preprocessed_df(df=None):
df_copy = df.copy()
scaler = StandardScaler()
amount_n = np.log1p(df_copy['Amount'])
df_copy.insert(0, 'Amount_Scaled', amount_n)
df_copy.drop(['Time', 'Amount'], axis=1, inplace=True)
return df_copy로그 변환 후 다시 성능을 예측해본다.
X_train, X_test, y_train, y_test = get_train_test_dataset(card_df)
print('### 로지스틱 회귀 예측 성능 ###')
get_model_train_eval(lr_clf, ftr_train=X_train, ftr_test=X_test, tgt_train=y_train, tgt_test=y_test)
print('### LightGBM 예측 성능 ###')
get_model_train_eval(lgbm_clf, ftr_train=X_train, ftr_test=X_test, tgt_train=y_train, tgt_test=y_test)### 로지스틱 회귀 예측 성능 ###
오차 행렬
[[85283 12]
[ 59 89]]
정확도: 0.9992, 정밀도: 0.8812, 재현율: 0.6014, F1: 0.7149, AUC:0.9727
### LightGBM 예측 성능 ###
오차 행렬
[[85290 5]
[ 35 113]]
정확도: 0.9995, 정밀도: 0.9576, 재현율: 0.7635, F1: 0.8496, AUC:0.9796LightGBM의 재현율이 꽤 올랐다. 이대로 진행하자
우선 로그변환한
이상치 데이터 제거
Seaborn 라이브러리의 heatmap으로 traget과 상관관계가 높은 Feature가 무엇인지 확인해보자
import seaborn as sns
plt.figure(figsize=(12, 12))
corr = card_df.corr()
sns.heatmap(corr, annot=True, fmt='.1f', cmap='RdBu')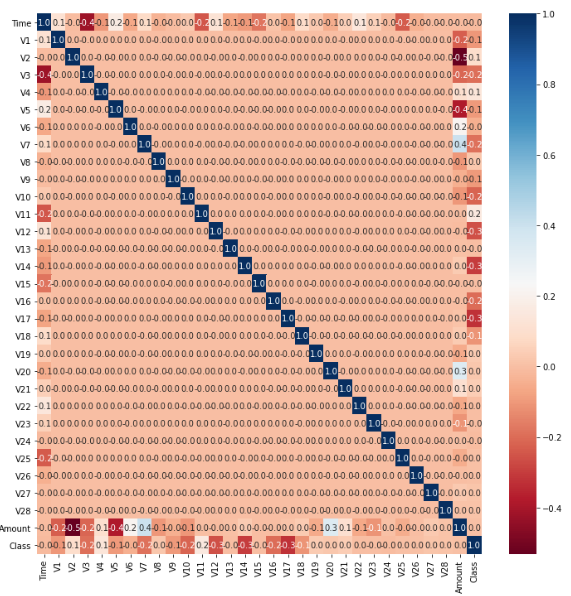
맨 아랫줄을 보면 V12, V14, V17정도가 높은 걸 볼 수 있다.
여기서는 V14에 대해서 이상치 처리를 진행해보자
이상치를 찾는get_outlier()함수를 만듦
여기서 이상치는Q1-1.5*IQR보다 작거나Q3+1.5*IQR보다 큰 값으로 정의
import numpy as np
def get_outlier(df=None, column=None, weight=1.5):
fraud = df[df['Class']==1][column]
Q1 = np.percentile(fraud.values, 25)
Q3 = np.percentile(fraud.values, 75)
IQR = Q3 - Q1
IQR_weight = IQR * weight
lowest_val = Q1 - IQR_weight
highest_val = Q3 + IQR_weight
outlier_index = fraud[(fraud < lowest_val) | (fraud > highest_val)].index
return outlier_index
V14칼럼에 대해 이상치의 인덱스를 확인하자
outlier_index = get_outlier(df=card_df, column='V14', weight=1.5)
print('이상치 데이터 인덱스:', outlier_index)이상치 데이터 인덱스: Int64Index([8296, 8615, 9035, 9252], dtype='int64')총 4개가 검출 되었다. 많지 않으니까 제거하자
get_preprocessed_df()함수에 이상치 제거 부분을 업데이트
def get_preprocessed_df(df=None):
df_copy = df.copy()
scaler = StandardScaler()
amount_n = np.log1p(df_copy['Amount'])
df_copy.insert(0, 'Amount_Scaled', amount_n)
df_copy.drop(['Time', 'Amount'], axis=1, inplace=True)
# 추가
outlier_index = get_outlier(df=df_copy, column='V14', weight=1.5)
df_copy.drop(outlier_index, axis=0, inplace=True)
return df_copy이상치 제거 후 모델 예측에서 평가까지 진행해보자
X_train, X_test, y_train, y_test = get_train_test_dataset(card_df)
print('### 로지스틱 회귀 예측 성능 ###')
get_model_train_eval(lr_clf, ftr_train=X_train, ftr_test=X_test, tgt_train=y_train, tgt_test=y_test)
print('### LightGBM 예측 성능 ###')
get_model_train_eval(lgbm_clf, ftr_train=X_train, ftr_test=X_test, tgt_train=y_train, tgt_test=y_test)### 로지스틱 회귀 예측 성능 ###
오차 행렬
[[85281 14]
[ 48 98]]
정확도: 0.9993, 정밀도: 0.8750, 재현율: 0.6712, F1: 0.7597, AUC:0.9743
### LightGBM 예측 성능 ###
오차 행렬
[[85290 5]
[ 25 121]]
정확도: 0.9996, 정밀도: 0.9603, 재현율: 0.8288, F1: 0.8897, AUC:0.9780재현율이 많이 올랐다!
이상치 딱 4개 제거했는데 효과가 좋았다.
이렇게 이상치 처리는 평가에 큰 영향을 줄 때가 많다.
다만 그렇다고 이상치를 너무 극단적으로 처리하는 건 권장되지 않음
따라서 이상치 처리는 최대한 보수적으로 진행하는 것이 좋다.
