XGBoost/LightGBM 사용해서 분류 예측 진행
Early Stopping과 베이지안 최적화를 이용한 하이퍼 파라미터 튜닝을 중점으로 진행
데이터 개요와 전처리
데이터 출처: https://www.kaggle.com/competitions/santander-customer-satisfaction/rules
산탄데르 은행의 고객 만족 예측
각 칼럼명은 어느정도 인코딩이 되어 있어서 뜻을 식별하기가 힘듦
TARGET:0 -> 만족
TARGET:1 -> 불만족
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
import warnings
warnings.filterwarnings('ignore')
cust_df = pd.read_csv("./train_santander.csv", encoding='latin-1')
print('dataset shape:', cust_df.shape)
cust_df.info()dataset shape: (76020, 371)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 76020 entries, 0 to 76019
Columns: 371 entries, ID to TARGET
dtypes: float64(111), int64(260)
memory usage: 215.2 MB칼럼이 너무 많아서 칼럼명이 나오지 않음
결측값은 없는 데이터임
Target(Label) 비율 확인
# 0: 만족, 1: 불만족
print(cust_df['TARGET'].value_counts())
unsatisfied_cnt = cust_df[cust_df['TARGET'] == 1].shape[0]
total_cnt = cust_df.shape[0]
print('unsatisfied 비율은 {0:.2f}'.format((unsatisfied_cnt / total_cnt)))0 73012
1 3008
Name: TARGET, dtype: int64
unsatisfied 비율은 0.04칼럼별 통계량 확인
cust_df.describe( )
(일부)
var3에 min 값이 이상함
아마 결측 등의 처리를 저렇게 해준 것 같음
좀 더 구체적으로 확인하기
cust_df['var3'].value_counts() 2 74165
8 138
-999999 116
9 110
3 108
...
177 1
87 1
151 1
215 1
191 1
Name: var3, Length: 208, dtype: int64
- -999999 값이 116개가 있음, 대부분을 차지하는 2로 replace 해주기
- 예측에 도움이 되지 않는 ID 칼럼은 drop
- Feature 데이터세트와 Label 데이터 세트를 분리
# var3 피처 값 대체 및 ID 피처 드롭
cust_df['var3'].replace(-999999, 2, inplace=True)
cust_df.drop('ID', axis=1, inplace=True)
# 피처 세트와 레이블 세트분리. 레이블 컬럼은 DataFrame의 맨 마지막에 위치해 컬럼 위치 -1로 분리
X_features = cust_df.iloc[:, :-1]
y_labels = cust_df.iloc[:, -1]
print('피처 데이터 shape:{0}'.format(X_features.shape))피처 데이터 shape:(76020, 369)train/test 데이터세트 분리하고 Label 분포 확인
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_features, y_labels,
test_size=0.2, random_state=0, stratify=y_labels)
train_cnt = y_train.count()
test_cnt = y_test.count()
print('학습 세트 Shape:{0}, 테스트 세트 Shape:{1}'.format(X_train.shape , X_test.shape))
print(' 학습 세트 레이블 값 분포 비율')
print(y_train.value_counts()/train_cnt)
print('\n 테스트 세트 레이블 값 분포 비율')
print(y_test.value_counts()/test_cnt)학습 세트 Shape:(60816, 369), 테스트 세트 Shape:(15204, 369)
학습 세트 레이블 값 분포 비율
0 0.960438
1 0.039562
Name: TARGET, dtype: float64
테스트 세트 레이블 값 분포 비율
0 0.960405
1 0.039595
Name: TARGET, dtype: float64
stratify를 사용해서 두 데이터세트의 분포가 비슷하게 나왔음
train 데이터 세트를 다시 train과 validation으로 분리
# X_train, y_train을 다시 학습과 검증 데이터 세트로 분리.
X_tr, X_val, y_tr, y_val = train_test_split(X_train, y_train,
test_size=0.3, random_state=0, stratify=y_train)XGBoost 모델
XGBoost 모델 사용하는데 Early Stopping 사용
평가지표로는 ROC_AUC_SCORE 이용
관련 파라미터 복습
early_stopping_rounds: 더이상 비용 평가 지표 감소하지 않는 최대 반복 횟수
eval_metric: 반복 수행 시 사용하는 비용 평가 지표
eval_set: 평가 수행하는 별도의 검증 데이터 세트
from xgboost import XGBClassifier
from sklearn.metrics import roc_auc_score
# n_estimators는 500으로, learning_rate 0.05, random state는 예제 수행 시마다 동일 예측 결과를 위해 설정.
xgb_clf = XGBClassifier(n_estimators=500, learning_rate=0.05, random_state=156)
# 성능 평가 지표를 auc로, 조기 중단 파라미터는 100으로 설정하고 학습 수행.
xgb_clf.fit(X_tr, y_tr, early_stopping_rounds=100, eval_metric='auc', eval_set = [(X_tr, y_tr), (X_val, y_val)])
xgb_roc_score = roc_auc_score(y_test, xgb_clf.predict_proba(X_test)[:, 1])
print('ROC AUC: {0:.4f}'.format(xgb_roc_score))[0] validation_0-auc:0.82361 validation_1-auc:0.81441
[1] validation_0-auc:0.82781 validation_1-auc:0.81954
[2] validation_0-auc:0.83186 validation_1-auc:0.82203
[3] validation_0-auc:0.83492 validation_1-auc:0.82536
[4] validation_0-auc:0.83504 validation_1-auc:0.82500
[5] validation_0-auc:0.83602 validation_1-auc:0.82564
[6] validation_0-auc:0.83678 validation_1-auc:0.82595
...
[237] validation_0-auc:0.91499 validation_1-auc:0.84361
[238] validation_0-auc:0.91502 validation_1-auc:0.84358
[239] validation_0-auc:0.91507 validation_1-auc:0.84356
[240] validation_0-auc:0.91507 validation_1-auc:0.84358
[241] validation_0-auc:0.91512 validation_1-auc:0.84354
[242] validation_0-auc:0.91521 validation_1-auc:0.84348
[243] validation_0-auc:0.91534 validation_1-auc:0.84340
ROC AUC: 0.8233ROC AUC Score: 0.8233 나온 것 확인하기
HyperOpt 패키지 사용해서 베이지안 최적화로 하이퍼 파라미터 튜닝
Search Space를 다음과 같이 만듦
from hyperopt import hp
# max_depth는 5에서 15까지 1간격으로, min_child_weight는 1에서 6까지 1간격으로
# colsample_bytree는 0.5에서 0.95사이, learning_rate는 0.01에서 0.2사이 정규 분포된 값으로 검색
xgb_search_space = {'max_depth': hp.quniform('max_depth', 5, 15, 1),
'min_child_weight': hp.quniform('min_child_weight', 1, 6, 1),
'colsample_bytree': hp.uniform('colsample_bytree', 0.5, 0.95),
'learning_rate': hp.uniform('learning_rate', 0.01, 0.2)
}목적 함수를 만듦
주석 천천히 따라가보기
최솟값을 찾아야 하니까 마지막에 -1을 곱함
from sklearn.model_selection import KFold
from sklearn.metrics import roc_auc_score
# 목적 함수 설정
# 추후 fmin()에서 입력된 search_space값으로 XGBClassifier 교차 검증 학습 후 -1* roc_auc 평균 값을 반환.
def objective_func(search_space):
xgb_clf = XGBClassifier(n_estimators = 100, max_depth=int(search_space['max_depth'])
, min_child_weight = int(search_space['min_child_weight'])
, colsample_bytree = search_space['colsample_bytree']
, learning_rate = search_space['learning_rate'])
# 3개 k-fold 방식으로 평가된 roc_auc 지표를 담는 list
roc_auc_list= []
# 3개 k-fold방식 적용
kf = KFold(n_splits=3)
# X_train을 다시 학습과 검증용 데이터로 분리
for tr_index, val_index in kf.split(X_train):
# kf.split(X_train)으로 추출된 학습과 검증 index값으로 학습과 검증 데이터 세트 분리
X_tr, y_tr = X_train.iloc[tr_index], y_train.iloc[tr_index]
X_val, y_val = X_train.iloc[val_index], y_train.iloc[val_index]
# early stopping은 30회로 설정하고 추출된 학습과 검증 데이터로 XGBClassifier 학습 수행.
xgb_clf.fit(X_tr, y_tr, early_stopping_rounds=30, eval_metric='auc'
, eval_set = [(X_tr, y_tr), (X_val, y_val)])
# 1로 예측한 확률값 추출후 roc auc 계산하고 평균 roc auc 계산을 위해 list에 결과값 담음.
score = roc_auc_score(y_val, xgb_clf.predict_proba(X_val)[:, 1])
roc_auc_list.append(score)
# 3개 k-fold로 계산된 roc_auc값의 평균값을 반환하되,
# HyperOpt는 목적함수의 최소값을 위한 입력값을 찾으므로 -1을 곱한 뒤 반환.
return -1 * np.mean(roc_auc_list)fmin 함수로 베이지안 최적화를 사용해서 최적의 하이퍼 파라미터 조합 찾기
코드 다 돌아가는데 약 30분 정도 걸림
from hyperopt import fmin, tpe, Trials
trials = Trials()
# fmin()함수를 호출. max_evals지정된 횟수만큼 반복 후 목적함수의 최소값을 가지는 최적 입력값 추출.
best = fmin(fn=objective_func,
space=xgb_search_space,
algo=tpe.suggest,
max_evals=50, # 최대 반복 횟수를 지정합니다.
trials=trials, rstate=np.random.default_rng(seed=30))
print('best:', best)[0] validation_0-auc:0.82974 validation_1-auc:0.81182
[1] validation_0-auc:0.83251 validation_1-auc:0.81290
[2] validation_0-auc:0.83539 validation_1-auc:0.81428
[3] validation_0-auc:0.84001 validation_1-auc:0.81700
[4] validation_0-auc:0.84284 validation_1-auc:0.81478
[5] validation_0-auc:0.84487 validation_1-auc:0.81854
...
[58] validation_0-auc:0.90524 validation_1-auc:0.84219
[59] validation_0-auc:0.90588 validation_1-auc:0.84203
[60] validation_0-auc:0.90647 validation_1-auc:0.84243
[61] validation_0-auc:0.90703 validation_1-auc:0.84254
[62] validation_0-auc:0.90771 validation_1-auc:0.84241
[63] validation_0-auc:0.90805 validation_1-auc:0.84249
100%|███████████████████████████████████████████████| 50/50 [36:52<00:00, 44.25s/trial, best loss: -0.8450266698065375]
best: {'colsample_bytree': 0.5776770858963758, 'learning_rate': 0.10188910033482984, 'max_depth': 5.0, 'min_child_weight': 6.0}베이지안 최적화로 찾은 최적의 하이퍼 파라미터
- 'colsample_bytree': 0.5776770858963758
- 'learning_rate': 0.10188910033482984
- 'max_depth': 5.0
- 'min_child_weight': 6.
최종적으로 찾은 하이퍼 파라미터를 사용하고,
Early Stopping까지 이용해서 fit() 하고 test 데이터에 대해 예측을 진행
예측 결과를 ROC AUC Score로 확인
[0] validation_0-auc:0.81909 validation_1-auc:0.81373
[1] validation_0-auc:0.82667 validation_1-auc:0.82210
[2] validation_0-auc:0.83212 validation_1-auc:0.82924
[3] validation_0-auc:0.83394 validation_1-auc:0.82849
[4] validation_0-auc:0.83605 validation_1-auc:0.82922
[5] validation_0-auc:0.84101 validation_1-auc:0.83263
[6] validation_0-auc:0.84398 validation_1-auc:0.83572
[7] validation_0-auc:0.84467 validation_1-auc:0.83622
[8] validation_0-auc:0.84570 validation_1-auc:0.83781
...
[175] validation_0-auc:0.90163 validation_1-auc:0.84437
[176] validation_0-auc:0.90185 validation_1-auc:0.84421
[177] validation_0-auc:0.90203 validation_1-auc:0.84405
[178] validation_0-auc:0.90209 validation_1-auc:0.84407
[179] validation_0-auc:0.90223 validation_1-auc:0.84405
[180] validation_0-auc:0.90227 validation_1-auc:0.84403
[181] validation_0-auc:0.90242 validation_1-auc:0.84396
[182] validation_0-auc:0.90274 validation_1-auc:0.84389
[183] validation_0-auc:0.90284 validation_1-auc:0.84395
ROC AUC: 0.8258베이지안 최적화 전보다 ROC AUC Score가 소폭 상승했음
Feature Importance 시각화로 마무리
from xgboost import plot_importance
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(1,1,figsize=(10,8))
plot_importance(xgb_clf, ax=ax , max_num_features=20,height=0.4)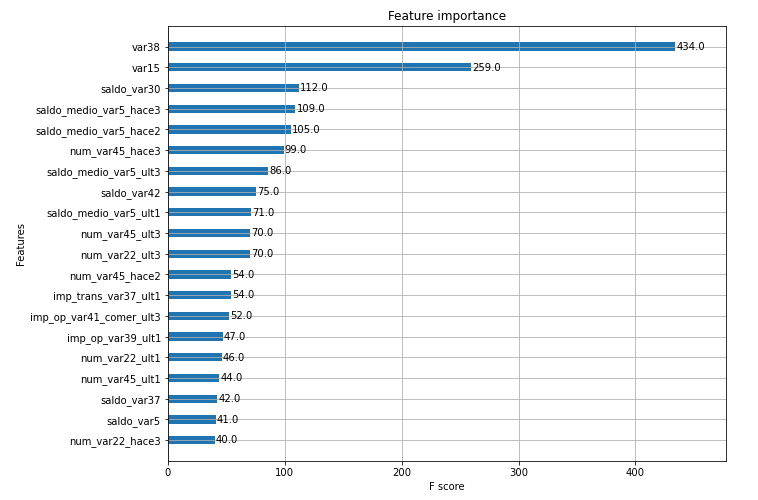
LightGBM 모델
LightGBM도 비슷하니까 필요한 부분만 설명
하이퍼 파라미터 변경 없이 ROC AUC 스코어 출력
Early Stopping만 사용
from lightgbm import LGBMClassifier
lgbm_clf = LGBMClassifier(n_estimators=500)
eval_set=[(X_tr, y_tr), (X_val, y_val)]
lgbm_clf.fit(X_tr, y_tr, early_stopping_rounds=100, eval_metric="auc", eval_set=eval_set)
lgbm_roc_score = roc_auc_score(y_test, lgbm_clf.predict_proba(X_test)[:,1])
print('ROC AUC: {0:.4f}'.format(lgbm_roc_score))[1] training's auc: 0.824228 training's binary_logloss: 0.156831 valid_1's auc: 0.816744 valid_1's binary_logloss: 0.158547
[2] training's auc: 0.835661 training's binary_logloss: 0.151145 valid_1's auc: 0.827251 valid_1's binary_logloss: 0.153561
[3] training's auc: 0.843182 training's binary_logloss: 0.146979 valid_1's auc: 0.828392 valid_1's binary_logloss: 0.150106
[4] training's auc: 0.8459 training's binary_logloss: 0.143663 valid_1's auc: 0.828847 valid_1's binary_logloss: 0.147372
...
[138] training's auc: 0.94852 training's binary_logloss: 0.0939292 valid_1's auc: 0.835307 valid_1's binary_logloss: 0.136192
[139] training's auc: 0.948622 training's binary_logloss: 0.0938259 valid_1's auc: 0.835327 valid_1's binary_logloss: 0.136203
[140] training's auc: 0.948728 training's binary_logloss: 0.0937181 valid_1's auc: 0.835033 valid_1's binary_logloss: 0.136284
[141] training's auc: 0.948793 training's binary_logloss: 0.09363 valid_1's auc: 0.834781 valid_1's binary_logloss: 0.136354
ROC AUC: 0.8213Search Space 생성
LightGBM은 Tree의 깊이에 크게 상관 없어서max_depth크게 잡음
lgbm_search_space = {'num_leaves': hp.quniform('num_leaves', 32, 64, 1),
'max_depth': hp.quniform('max_depth', 100, 160, 1),
'min_child_samples': hp.quniform('min_child_samples', 60, 100, 1),
'subsample': hp.uniform('subsample', 0.7, 1),
'learning_rate': hp.uniform('learning_rate', 0.01, 0.2)
}목적 함수 설정
def objective_func(search_space):
lgbm_clf = LGBMClassifier(n_estimators=100, num_leaves=int(search_space['num_leaves']),
max_depth=int(search_space['max_depth']),
min_child_samples=int(search_space['min_child_samples']),
subsample=search_space['subsample'],
learning_rate=search_space['learning_rate'])
# 3개 k-fold 방식으로 평가된 roc_auc 지표를 담는 list
roc_auc_list = []
# 3개 k-fold방식 적용
kf = KFold(n_splits=3)
# X_train을 다시 학습과 검증용 데이터로 분리
for tr_index, val_index in kf.split(X_train):
# kf.split(X_train)으로 추출된 학습과 검증 index값으로 학습과 검증 데이터 세트 분리
X_tr, y_tr = X_train.iloc[tr_index], y_train.iloc[tr_index]
X_val, y_val = X_train.iloc[val_index], y_train.iloc[val_index]
# early stopping은 30회로 설정하고 추출된 학습과 검증 데이터로 XGBClassifier 학습 수행.
lgbm_clf.fit(X_tr, y_tr, early_stopping_rounds=30, eval_metric="auc",
eval_set=[(X_tr, y_tr), (X_val, y_val)])
# 1로 예측한 확률값 추출후 roc auc 계산하고 평균 roc auc 계산을 위해 list에 결과값 담음.
score = roc_auc_score(y_val, lgbm_clf.predict_proba(X_val)[:, 1])
roc_auc_list.append(score)
# 3개 k-fold로 계산된 roc_auc값의 평균값을 반환하되,
# HyperOpt는 목적함수의 최소값을 위한 입력값을 찾으므로 -1을 곱한 뒤 반환.
return -1*np.mean(roc_auc_list)베이지안 최적화 진행
from hyperopt import fmin, tpe, Trials
trials = Trials()
# fmin()함수를 호출. max_evals지정된 횟수만큼 반복 후 목적함수의 최소값을 가지는 최적 입력값 추출.
best = fmin(fn=objective_func, space=lgbm_search_space, algo=tpe.suggest,
max_evals=50, # 최대 반복 횟수를 지정합니다.
trials=trials, rstate=np.random.default_rng(seed=30))
print('best:', best)[1] training's auc: 0.829117 training's binary_logloss: 0.166068 valid_1's auc: 0.813958 valid_1's binary_logloss: 0.16088
[2] training's auc: 0.831752 training's binary_logloss: 0.163964 valid_1's auc: 0.814755 valid_1's binary_logloss: 0.159158
[3] training's auc: 0.834075 training's binary_logloss: 0.162086 valid_1's auc: 0.817047 valid_1's binary_logloss: 0.157587
[4] training's auc: 0.836349 training's binary_logloss: 0.160373 valid_1's auc: 0.819498 valid_1's binary_logloss: 0.156133
...
[85] training's auc: 0.925372 training's binary_logloss: 0.107112 valid_1's auc: 0.835739 valid_1's binary_logloss: 0.136436
[86] training's auc: 0.925729 training's binary_logloss: 0.106903 valid_1's auc: 0.835716 valid_1's binary_logloss: 0.136424
[87] training's auc: 0.926147 training's binary_logloss: 0.106699 valid_1's auc: 0.835601 valid_1's binary_logloss: 0.136437
[88] training's auc: 0.926626 training's binary_logloss: 0.106467 valid_1's auc: 0.835517 valid_1's binary_logloss: 0.136471
100%|███████████████████████████████████████████████| 50/50 [05:05<00:00, 6.11s/trial, best loss: -0.8409080734703344]
best: {'learning_rate': 0.031064257415817302, 'max_depth': 115.0, 'min_child_samples': 97.0, 'num_leaves': 32.0, 'subsample': 0.9033288761262107}찾은 하이퍼 파라미터 조합으로 test 데이터에 대해 예측 수행
lgbm_clf = LGBMClassifier(n_estimators=500, num_leaves=int(best['num_leaves']),
max_depth=int(best['max_depth']),
min_child_samples=int(best['min_child_samples']),
subsample=round(best['subsample'], 5),
learning_rate=round(best['learning_rate'], 5)
)
# evaluation metric을 auc로, early stopping은 100 으로 설정하고 학습 수행.
lgbm_clf.fit(X_tr, y_tr, early_stopping_rounds=100,
eval_metric="auc",eval_set=[(X_tr, y_tr), (X_val, y_val)])
lgbm_roc_score = roc_auc_score(y_test, lgbm_clf.predict_proba(X_test)[:,1])
print('ROC AUC: {0:.4f}'.format(lgbm_roc_score))[1] training's auc: 0.82595 training's binary_logloss: 0.163518 valid_1's auc: 0.813214 valid_1's binary_logloss: 0.163902
[2] training's auc: 0.83005 training's binary_logloss: 0.160989 valid_1's auc: 0.818465 valid_1's binary_logloss: 0.161587
[3] training's auc: 0.835574 training's binary_logloss: 0.158793 valid_1's auc: 0.822633 valid_1's binary_logloss: 0.159556
[4] training's auc: 0.836537 training's binary_logloss: 0.156857 valid_1's auc: 0.822741 valid_1's binary_logloss: 0.157735
...
[198] training's auc: 0.914469 training's binary_logloss: 0.112229 valid_1's auc: 0.842075 valid_1's binary_logloss: 0.133661
[199] training's auc: 0.914576 training's binary_logloss: 0.112161 valid_1's auc: 0.842022 valid_1's binary_logloss: 0.133682
[200] training's auc: 0.914738 training's binary_logloss: 0.112083 valid_1's auc: 0.842048 valid_1's binary_logloss: 0.133684
[201] training's auc: 0.914877 training's binary_logloss: 0.112014 valid_1's auc: 0.842014 valid_1's binary_logloss: 0.133686
ROC AUC: 0.8239ROC AUC 스코어가 소폭 상승한 것을 확인
