앙상블 학습 개요
앙상블 학습: 분류를 할 때 여러 개의 분류기(Classifier)를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법
앙상블 학습의 유형으로는 여러 가지 종류가 있음
전통적인 세 가지 방법
- 보팅 (Voting)
- 배깅 (Bagging)
- 부스팅 (Boosting)
스태킹 (Stacking) 등..
보팅과 배깅의 차이
보팅: 한 데이터세트에 대해 서로 다른 알고리즘을 가진 분류기의 결합
배깅: 각각의 분류기가 모두 같은 유형의 알고리즘 기반, 데이터 샘플링을 다르게 해서 보팅
배깅의 예로 Decision Tree를 합친 Random Forest가 있음
하드 보팅과 소프트 보팅
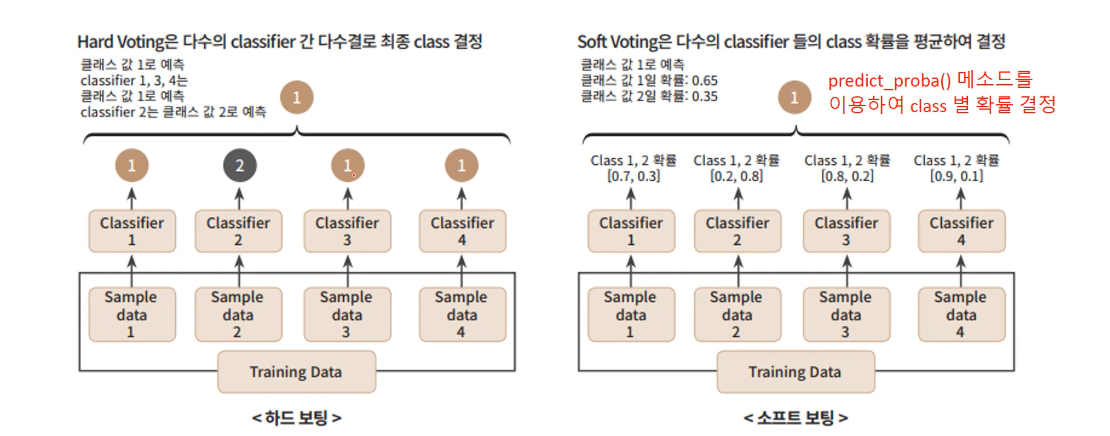
하드 보팅: 각 분류기가 최종 class를 딱 정하면 그게 더 많은 걸 최종 class로 결정
소프트 보팅: 각 분류기마다 각 Class의 확률을 정하고 그 확률들의 평균값이 큰 값을 최종 Class로 결정
여기서 확률이 scikit-learn에서
predict_proba()하면 나오는 그것임!
위 사진의 예로 보면
이므로 최종 Class는 Class 1이 됨
일반적으로 소프트 보팅의 성능이 더 좋아서 더 많이 사용됨!
보팅 실습
scikit-learn으로 보팅을 구현해보자
보팅 방식의 앙상블을 구현한 VotingClassifier 클래스가 있음
여기서는 scikit-learn에 기본 탑재되어 있는 위스콘신 유방암 데이터를 사용함
import pandas as pd
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
cancer = load_breast_cancer()
data_df = pd.DataFrame(cancer.data, columns=cancer.feature_names)
data_df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 569 entries, 0 to 568
Data columns (total 30 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 mean radius 569 non-null float64
1 mean texture 569 non-null float64
2 mean perimeter 569 non-null float64
3 mean area 569 non-null float64
4 mean smoothness 569 non-null float64
5 mean compactness 569 non-null float64
6 mean concavity 569 non-null float64
7 mean concave points 569 non-null float64
8 mean symmetry 569 non-null float64
9 mean fractal dimension 569 non-null float64
10 radius error 569 non-null float64
11 texture error 569 non-null float64
12 perimeter error 569 non-null float64
13 area error 569 non-null float64
14 smoothness error 569 non-null float64
15 compactness error 569 non-null float64
16 concavity error 569 non-null float64
17 concave points error 569 non-null float64
18 symmetry error 569 non-null float64
19 fractal dimension error 569 non-null float64
20 worst radius 569 non-null float64
21 worst texture 569 non-null float64
22 worst perimeter 569 non-null float64
23 worst area 569 non-null float64
24 worst smoothness 569 non-null float64
25 worst compactness 569 non-null float64
26 worst concavity 569 non-null float64
27 worst concave points 569 non-null float64
28 worst symmetry 569 non-null float64
29 worst fractal dimension 569 non-null float64
dtypes: float64(30)
memory usage: 133.5 KB로지스틱 회귀와 KNN을 기반으로 소프트 보팅을 진행해서 새로운 보팅 분류기 만들기
voting='soft'가 소프트 보팅으로 한다는 뜻임
# 개별 모델로 로지스틱 회귀와 KNN 사용
lr_clf = LogisticRegression(solver='liblinear')
knn_clf = KNeighborsClassifier(n_neighbors=8)
# 개별 모델을 소프트 보팅 기반의 앙상블 모델로 구현한 분류기
vo_clf = VotingClassifier(estimators = [('LR', lr_clf), ('KNN', knn_clf)], voting = 'soft')
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, test_size=0.2, random_state = 156)
# 개별 모델의 학습/예측/평가
classifiers = [lr_clf, knn_clf]
for classifier in classifiers:
classifier.fit(X_train , y_train)
pred = classifier.predict(X_test)
class_name= classifier.__class__.__name__
print('{0} 정확도: {1:.4f}'.format(class_name, accuracy_score(y_test , pred)))
# VotingClassifier 학습/예측/평가
vo_clf.fit(X_train, y_train)
pred = vo_clf.predict(X_test)
print("Voting 분류기 정확도: ", round(accuracy_score(y_test, pred),4))LogisticRegression 정확도: 0.9474
KNeighborsClassifier 정확도: 0.9386
Voting 분류기 정확도: 0.9561개별 분류기 예측과 보팅 후 예측 모두 해봤음
보팅 분류기의 정확도가 더 높다!
근데 이건 어느정도 맞춘 예제인 거고, 실제로는 무조건 보팅 분류기의 정확도가 높은 건 아님!
사진 출처는 파이썬 머신러닝 완벽 가이드
