앞에서 확인한 것처럼 정확도에는 한계가 존재한다.
다른 성능 평가지표들도 알아보자.
오차 행렬
오차 행렬, 혼동 행렬, 오분류표, Confusion Matrix
학습된 분류 모델이 예측을 수행하면서 얼마나 헷갈리고 있는지 함께 보여주는 지표
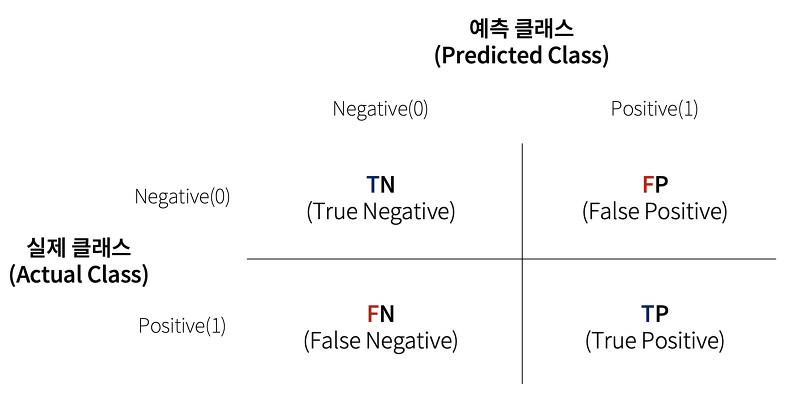
뒤에 붙은 N, P가 예측이고, 앞에 붙은 T, F가 예측한 게 맞는지 틀린지를 보여주는 것
- TN: 예측값: Negative, 실제: Negative
- FP: 예측값: Positive, 실제: Negative
- FN: 예측값: Negative, 실제: Positive
- TP: 예측값: Positive, 실제: Positive
이것을 토대로 앞에서 했던 정확도를 다시 계산해보면 아래처럼 될 것!
앞에서 정확도를 구할 때 사용한 MNIST 예제로 오차 행렬을 만들어보자
from sklearn.metrics import confusion_matrix
# 앞절의 예측 결과인 fakepred와 실제 결과인 y_test의 Confusion Matrix출력
confusion_matrix(y_test , fakepred)array([[405, 0],
[ 45, 0]], dtype=int64)TN: 405, FN: 45, FP: 0, TP: 0 으로 나옴
정확도는 높게 나오지만 계산에서 0인 것들이 제대로 고려되지 않았음
그걸 고려해주는정밀도와재현율을 알아보자
정밀도와 재현율
정밀도 (Precision)
재현율 (Recall)
재현율은 민감도 (Sensitivity), 참긍정률(TPR,True Positive Rate) 라고도 불림
MNIST 예제로 계산해보자
from sklearn.metrics import accuracy_score, precision_score , recall_score
print("정밀도:", precision_score(y_test, fakepred))
print("재현율:", recall_score(y_test, fakepred))정밀도: 0.0
재현율: 0.0둘다 0이 나왔음, 정확도랑은 매우 큰 차이가 나는 것을 볼 수 있다.
이제 임의로 만든 Estimator를 넣은 MNIST 예제는 그만하고,
타이타닉 데이터에 Logistic Regression 을 적용 후 각 성능 평가지표를 확인해보자
우선 각 성능 평가지표를 한번에 출력하는 함수를 만들어주기
from sklearn.metrics import accuracy_score, precision_score , recall_score , confusion_matrix
def get_clf_eval(y_test , pred):
confusion = confusion_matrix( y_test, pred)
accuracy = accuracy_score(y_test , pred)
precision = precision_score(y_test , pred)
recall = recall_score(y_test , pred)
print('오차 행렬')
print(confusion)
print('정확도: {0:.4f}, 정밀도: {1:.4f}, 재현율: {2:.4f}'.format(accuracy , precision ,recall))아래는 앞에 타이타닉 예시에서 했던 전처리와 동일하게 해주는 것
import pandas as pd
from sklearn.preprocessing import LabelEncoder
# Null 처리 함수
def fillna(df):
df['Age'].fillna(df['Age'].mean(),inplace=True)
df['Cabin'].fillna('N',inplace=True)
df['Embarked'].fillna('N',inplace=True)
df['Fare'].fillna(0,inplace=True)
return df
# 머신러닝 알고리즘에 불필요한 속성 제거
def drop_features(df):
df.drop(['PassengerId','Name','Ticket'],axis=1,inplace=True)
return df
# 레이블 인코딩 수행.
def format_features(df):
df['Cabin'] = df['Cabin'].str[:1]
features = ['Cabin','Sex','Embarked']
for feature in features:
le = LabelEncoder()
le = le.fit(df[feature])
df[feature] = le.transform(df[feature])
return df
# 앞에서 설정한 Data Preprocessing 함수 호출
def transform_features(df):
df = fillna(df)
df = drop_features(df)
df = format_features(df)
return df타이타닉 데이터를 불러와서 전처리 후 Logistic Regression으로 학습하고 성능 평가지표를 출력한다.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
# 원본 데이터를 재로딩, 데이터 가공, 학습데이터/테스트 데이터 분할
titanic_df = pd.read_csv('./titanic_train.csv')
y_titanic_df = titanic_df['Survived']
X_titanic_df= titanic_df.drop('Survived', axis=1)
X_titanic_df = transform_features(X_titanic_df)
X_train, X_test, y_train, y_test = train_test_split(X_titanic_df, y_titanic_df, \
test_size=0.20, random_state=11)
lr_clf = LogisticRegression()
lr_clf.fit(X_train , y_train)
pred = lr_clf.predict(X_test)
get_clf_eval(y_test , pred)오차 행렬
[[104 14]
[ 13 48]]
정확도: 0.8492, 정밀도: 0.7742, 재현율: 0.7869일반적인 Estimator를 사용하니까 정밀도와 재현율이 적당히 나오는 것을 볼 수 있다.
강의에서 언급은 없어서 나중에 나오는지는 모르겠는데 평가지표들을 한번에 출력해주는
classification_report라는 scikit-learn 함수가 있음
from sklearn.metrics import classification_report
print(classification_report(y_test, pred)) precision recall f1-score support
0 0.89 0.88 0.89 118
1 0.77 0.79 0.78 61
accuracy 0.85 179
macro avg 0.83 0.83 0.83 179
weighted avg 0.85 0.85 0.85 179