규제 선형 회귀 개요
우리가 지금까지 다룬 회귀 모델들은 결국 Loss 값인 RSS를 최소화 하는 것이었음
그런데, 앞에 다항 회귀의 차수가 15일 때를 보면 회귀계수가 매우 크게 설정됨
-> 과적합 발생
-> 형편없는 평가 데이터 예측 성능
따라서, 데이터의 오류값인 RSS와 회귀 계수를 동시에 최소화하는 것이 규제 선형 회귀의 아이디어!
아래는 L2 규제 예시
: 학습 데이터 적합 정도와 회귀 계수 값의 크기를 제어하는 튜닝 파라미터
: 회귀 계수
감소: 최소화 (이전과 동일)
증가: 회귀 계수 감소
규제 방식
-
L1 규제: 의 절댓값에 대해 패널티 부여 (Lasso)
-> 불필요한 회귀 계수를 급격하게 감소시켜 0으로 만들고 제거함
-
L2 규제: 의 제곱에 대해 패널티 부여 (Ridge)
-> 회귀 계수의 크기를 감소시킴
-
L1, L2 혼합 규제: 두 규제를 결합 (ElasticNet)
일반적으로 규제를 적용하는 것이 퍼포먼스가 더 좋음!
Ridge Regression
릿지 회귀
앞에서 설명한 L2 규제를 적용한 회귀
-> 회귀 계수의 크기를 감소시킴
scikit-learn에서는
Ridge클래스를 제공
사용법은LinearRegression과 거의 동일함
# 앞의 LinearRegression예제에서 분할한 feature 데이터 셋인 X_data과 Target 데이터 셋인 Y_target 데이터셋을 그대로 이용
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
# boston 데이타셋 로드
boston = load_boston()
# boston 데이타셋 DataFrame 변환
bostonDF = pd.DataFrame(boston.data , columns = boston.feature_names)
# boston dataset의 target array는 주택 가격임. 이를 PRICE 컬럼으로 DataFrame에 추가함.
bostonDF['PRICE'] = boston.target
y_target = bostonDF['PRICE']
X_data = bostonDF.drop(['PRICE'],axis=1,inplace=False)
ridge = Ridge(alpha = 10)
neg_mse_scores = cross_val_score(ridge, X_data, y_target, scoring="neg_mean_squared_error", cv = 5)
rmse_scores = np.sqrt(-1 * neg_mse_scores)
avg_rmse = np.mean(rmse_scores)
print(' 5 folds 의 개별 Negative MSE scores: ', np.round(neg_mse_scores, 3))
print(' 5 folds 의 개별 RMSE scores : ', np.round(rmse_scores,3))
print(' 5 folds 의 평균 RMSE : {0:.3f} '.format(avg_rmse)) 5 folds 의 개별 Negative MSE scores: [-11.422 -24.294 -28.144 -74.599 -28.517]
5 folds 의 개별 RMSE scores : [3.38 4.929 5.305 8.637 5.34 ]
5 folds 의 평균 RMSE : 5.518 값의 변경하면서 변화를 살펴보자
가 0이면 Linear Regression과 동일한 것을 생각하기
# Ridge에 사용될 alpha 파라미터의 값들을 정의
alphas = [0 , 0.1 , 1 , 10 , 100]
# alphas list 값을 iteration하면서 alpha에 따른 평균 rmse 구함.
for alpha in alphas :
ridge = Ridge(alpha = alpha)
#cross_val_score를 이용하여 5 fold의 평균 RMSE 계산
neg_mse_scores = cross_val_score(ridge, X_data, y_target, scoring="neg_mean_squared_error", cv = 5)
avg_rmse = np.mean(np.sqrt(-1 * neg_mse_scores))
print('alpha {0} 일 때 5 folds 의 평균 RMSE : {1:.3f} '.format(alpha,avg_rmse))alpha 0 일 때 5 folds 의 평균 RMSE : 5.829
alpha 0.1 일 때 5 folds 의 평균 RMSE : 5.788
alpha 1 일 때 5 folds 의 평균 RMSE : 5.653
alpha 10 일 때 5 folds 의 평균 RMSE : 5.518
alpha 100 일 때 5 folds 의 평균 RMSE : 5.330 가 100일 때 가장 성능이 좋게 나옴
단, 가 높을수록 무조건 성능이 좋은 건 아님!
각 에 대해 회귀 계수를 시각화해보자
# 각 alpha에 따른 회귀 계수 값을 시각화하기 위해 5개의 열로 된 맷플롯립 축 생성
fig , axs = plt.subplots(figsize=(18,6) , nrows=1 , ncols=5)
# 각 alpha에 따른 회귀 계수 값을 데이터로 저장하기 위한 DataFrame 생성
coeff_df = pd.DataFrame()
# alphas 리스트 값을 차례로 입력해 회귀 계수 값 시각화 및 데이터 저장. pos는 axis의 위치 지정
for pos , alpha in enumerate(alphas) :
ridge = Ridge(alpha = alpha)
ridge.fit(X_data , y_target)
# alpha에 따른 피처별 회귀 계수를 Series로 변환하고 이를 DataFrame의 컬럼으로 추가.
coeff = pd.Series(data=ridge.coef_ , index=X_data.columns )
colname='alpha:'+str(alpha)
coeff_df[colname] = coeff
# 막대 그래프로 각 alpha 값에서의 회귀 계수를 시각화. 회귀 계수값이 높은 순으로 표현
coeff = coeff.sort_values(ascending=False)
axs[pos].set_title(colname)
axs[pos].set_xlim(-3,6)
sns.barplot(x=coeff.values , y=coeff.index, ax=axs[pos])
# for 문 바깥에서 맷플롯립의 show 호출 및 alpha에 따른 피처별 회귀 계수를 DataFrame으로 표시
plt.show()
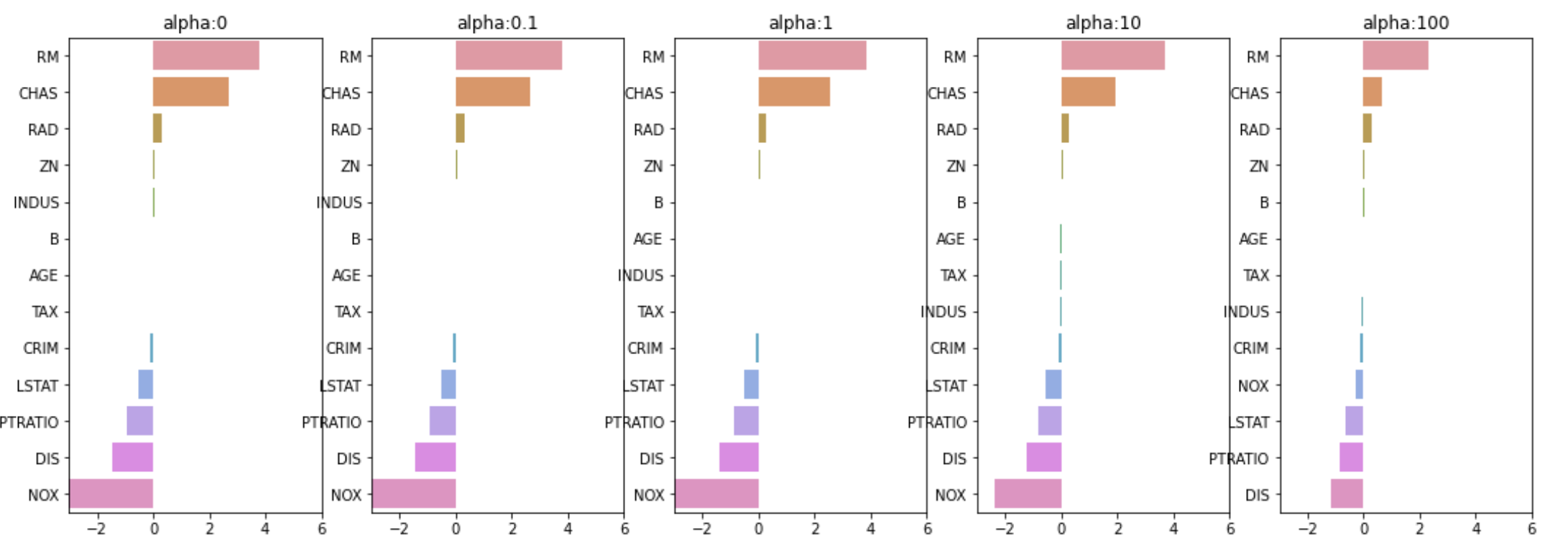
아까 설명한 것처럼 규제 강할수록 (가 클수록) 회귀 계수가 작아진다!
수치적으로도 살펴보자
ridge_alphas = [0 , 0.1 , 1 , 10 , 100]
sort_column = 'alpha:'+str(ridge_alphas[0])
coeff_df.sort_values(by=sort_column, ascending=False)
가 커질 때 회귀 계수가 점점 작아짐
하지만 0이 되진 않음! (Lasso와 차이점)
Lasso Regression
라쏘 회귀
앞에서 설명한 L1 규제를 적용한 회귀
-> 불필요한 회귀 계수를 급격하게 감소시켜 0으로 만들고 제거함
-> 적절한 피처만 회귀에 포함시키는 Feature Selection의 특성을 가짐!
scikit-learn에서는
Lasso클래스를 지원
사용 방식은 Ridge와 동일
여기서는 함수로 만들어서 Elastic Net 회귀까지 사용하자
모델을 정해서 학습을 하고 CV로 평균 RMSE 구한 후,
회귀 계수를 구하기 위해 다시 학습 후 회귀 계수 return하는 함수
from sklearn.linear_model import Ridge, Lasso, ElasticNet
from sklearn.model_selection import cross_val_score
# alpha값에 따른 회귀 모델의 폴드 평균 RMSE를 출력하고 회귀 계수값들을 DataFrame으로 반환
def get_linear_reg_eval(model_name, params=None, X_data_n=None, y_target_n=None,
verbose=True, return_coeff=True):
coeff_df = pd.DataFrame()
if verbose : print('####### ', model_name , '#######')
for param in params:
if model_name =='Ridge': model = Ridge(alpha=param)
elif model_name =='Lasso': model = Lasso(alpha=param)
elif model_name =='ElasticNet': model = ElasticNet(alpha=param, l1_ratio=0.7)
neg_mse_scores = cross_val_score(model, X_data_n,
y_target_n, scoring="neg_mean_squared_error", cv = 5)
avg_rmse = np.mean(np.sqrt(-1 * neg_mse_scores))
print('alpha {0}일 때 5 폴드 세트의 평균 RMSE: {1:.3f} '.format(param, avg_rmse))
# cross_val_score는 evaluation metric만 반환하므로 모델을 다시 학습하여 회귀 계수 추출
model.fit(X_data_n , y_target_n)
if return_coeff:
# alpha에 따른 피처별 회귀 계수를 Series로 변환하고 이를 DataFrame의 컬럼으로 추가.
coeff = pd.Series(data=model.coef_ , index=X_data_n.columns )
colname='alpha:'+str(param)
coeff_df[colname] = coeff
return coeff_dfalpha 조정하면서 Lasso Regression 실행
lasso_alphas = [ 0.07, 0.1, 0.5, 1, 3]
coeff_lasso_df =get_linear_reg_eval('Lasso', params=lasso_alphas, X_data_n=X_data, y_target_n=y_target)####### Lasso #######
alpha 0.07일 때 5 폴드 세트의 평균 RMSE: 5.612
alpha 0.1일 때 5 폴드 세트의 평균 RMSE: 5.615
alpha 0.5일 때 5 폴드 세트의 평균 RMSE: 5.669
alpha 1일 때 5 폴드 세트의 평균 RMSE: 5.776
alpha 3일 때 5 폴드 세트의 평균 RMSE: 6.189 alpha = 0.07일 때 가장 성능이 좋았다.
회귀 계수를 출력해보자
반환된 coeff_lasso_df를 첫번째 컬럼순으로 내림차순 정렬하여 회귀계수 출력
sort_column = 'alpha:'+str(lasso_alphas[0])
coeff_lasso_df.sort_values(by=sort_column, ascending=False)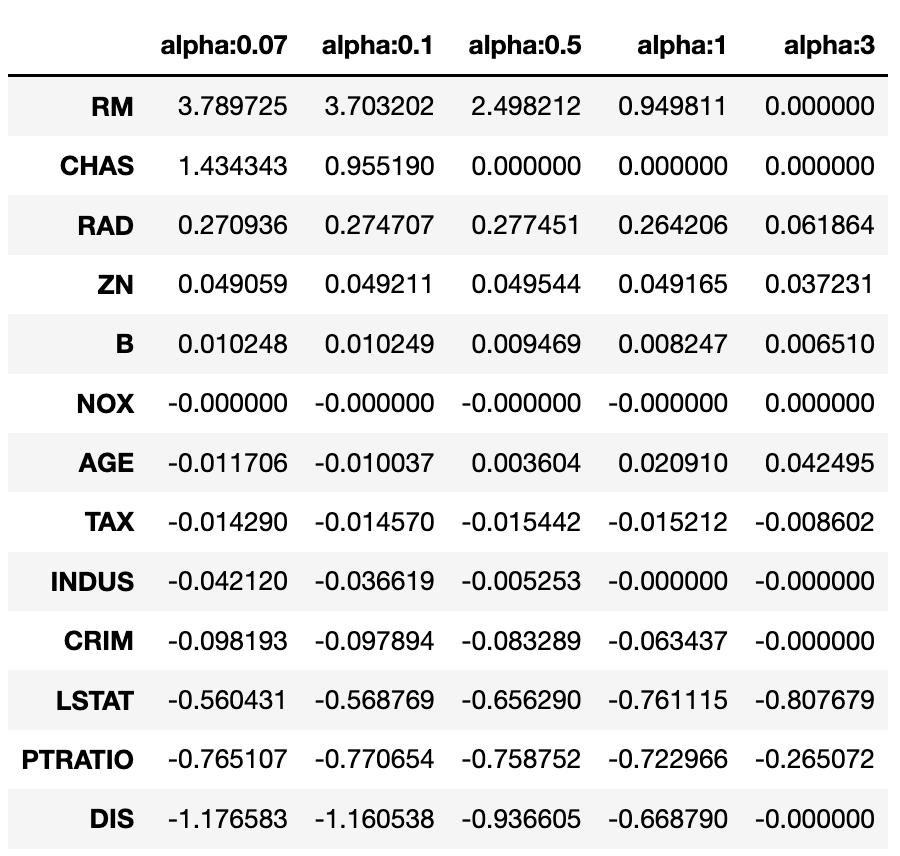
Ridge와 다르게 아예 0이 되어버린 회귀 계수가 있는 것을 확인하자!
Elastic Net Regression
엘라스틱넷 회귀
L2와 L1 규제를 결합한 회귀
Lasso Regression과 Elastic Net Regression은 서로 상관관계가 높은 피처들의 경우 이들 중 중요한 Feature만 선택하고, 다른 Feature의 회귀 계수를 모두 0으로 만드는 성향이 강함
이 때문에 에 따라 회귀 계수가 급격히 변동하는데, Elastic Net은 이것은 완화하기 위해 Lasso에 L2 규제를 추가한 것!
scikit-learn에서는
ElasticNet클래스를 지원
주요 생성 파라미터는 alpha, l1_ratio
-> 여기서 alpha는 Ridge와 Lasso 클래스의 alpha와는 다름!
a * L1규제 + b * L2규제 라고 하자
if) alpha: 10, l1_ratio = 0.7
-> a + b = 10, a = 7, b = 3
->
그 외에는 Ridge, Lasso와 거의 동일하다.
앞에서 만든 함수를 이용해서 Elastic Net Regression 실행
l1_ratio는 고정해서, 설정한 alpha에 따라 alpha1, alpha2가 가변한다.
elastic_alphas = [ 0.07, 0.1, 0.5, 1, 3]
coeff_elastic_df =get_linear_reg_eval('ElasticNet', params=elastic_alphas,
X_data_n=X_data, y_target_n=y_target)####### ElasticNet #######
alpha 0.07일 때 5 폴드 세트의 평균 RMSE: 5.542
alpha 0.1일 때 5 폴드 세트의 평균 RMSE: 5.526
alpha 0.5일 때 5 폴드 세트의 평균 RMSE: 5.467
alpha 1일 때 5 폴드 세트의 평균 RMSE: 5.597
alpha 3일 때 5 폴드 세트의 평균 RMSE: 6.068 alpha = 0.1 일 때, 가장 성능이 좋았다.
회귀 계수도 살펴보자
sort_column = 'alpha:'+str(elastic_alphas[0])
coeff_elastic_df.sort_values(by=sort_column, ascending=False)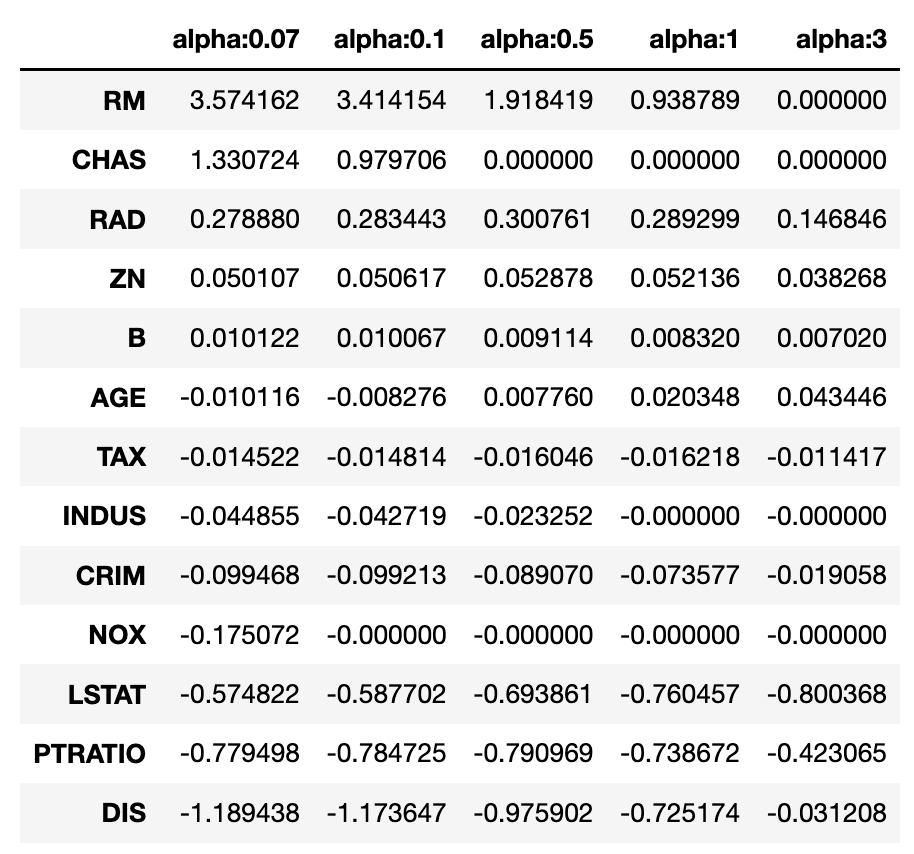
0이 된 회귀 계수들이 있는데, Lasso에 비하면 덜 극단적인 것을 볼 수 있음
