
기본 컨셉 코드
import numpy as np
DATA = [1,3,2]
ans = np.max(DATA)
arg_ans = np.argmax(DATA)
print("max : {} VS argmax {}".format(ans,arg_ans))
p1 = np.exp(1) / (np.exp(1) + np.exp(2) + np.exp(3))
p2 = np.exp(2) / (np.exp(1) + np.exp(2) + np.exp(3))
p3 = np.exp(3) / (np.exp(1) + np.exp(2) + np.exp(3))
print("DATA 원소들의 softmax 전체 합 : {:.1f}".format(p1 + p2 + p3))
print("DATA 원소들의 softmax 값 : {:.4f}, {:.4f}, {:.4f}".format(p1,p2,p3))
from scipy.special import softmax
scipy_ans = softmax(DATA)
print(scipy_ans)
print("DATA 원소들의 softmax 전체 합 : {:.1f}".format(np.sum(scipy_ans)))
print("DATA 원소들의 softmax 값 : {:.4f}, {:.4f}, {:.4f}".format(*scipy_ans))max : 3 VS argmax 1
DATA 원소들의 softmax 전체 합 : 1.0
DATA 원소들의 softmax 값 : 0.0900, 0.2447, 0.6652
[0.09003057 0.66524096 0.24472847]
DATA 원소들의 softmax 전체 합 : 1.0
DATA 원소들의 softmax 값 : 0.0900, 0.6652, 0.2447⭐️ 결론부터 얘기하자면 Knowledge distillation에서는 Teacher와 Student의 개념이 나오고 진짜 정답과, Student모델이 Teacher모델을 따르도록 학습이 되어지는데 진짜 답에서는 hardmax(argmax)를 따르도록 하고 Student모델이 Teacher모델을 따르도록 학습하는 부분은 softmax값을 따르도록 학습이 되어진다.
Knowledge distillation
logit, sigmoid, softmax관계 및 수식 유도 참고자료
-> https://opentutorials.org/module/3653/22995
Knowledge distillation이전 정리 블로그 내용
https://velog.io/@ganta/Annotation-data-efficient-learning
✔️ Knowledge distillation의 기본 형태는 커다란 모델에 있는 것을 액기스만 뽑아 Edge device에 전달하는 것이다.
✔️ Transfer learning과의 차이점
Transfer learning은 어느 도메인에서 배운 지식을 다른 도메인에서 사용하는 것이라면 Knowledge distillation는 서로 같은 도메인 사이에서 모델을 사용한다는 점이 차이점이다.
✔️ 혼자 배운 것 보다 Teacher모델 정보를 받아 Student모델을 학습하면 더욱 좋은 퍼포먼스를 낸다.
Teacher-Stuent networks & Hinton loss
✔️ Student를 학습 시킬때 loss는 보통 다음과 같은 loss형태로 구하게 된다.
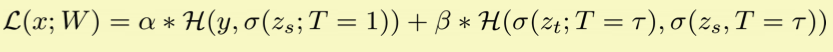
출처 : Naver BoostCamp AI Tech - edwith 강의
이 loss를 hinton loss라고 한다.<br =>
아래와 같은 방법으로 식이 자주 사용이 된다.

출처 : Naver BoostCamp AI Tech - edwith 강의
이때, teacher-student는 쿨백 라이블러 발산을 사용하였는데 이 이유는 확률분포를 비슷하게 하기 위한 방향으로 학습이 되게 하기 위함이고 실제값과 student값은 Cross-Entropy를 사용하였는데 이 이유는 정확한 값에 맞춰지게 학습을 하기 위함이다.
참고 자료
https://stats.stackexchange.com/questions/357963/what-is-the-difference-cross-entropy-and-kl-divergence
✔️ Softmax with temperature를 설정해주워 softmax의 값들이 서로 조금씩 차이게 하게 하는 이유는 현재 Teacher모델이 특정 도메인만 보는 것을 학습하는 것이 아닌 다양한 도메인들에 대하여 어떠한 식으로 생각하고 있는지 좀 더 세밀하게 보기 위함이다.(예를 들어, 도메인 a가 답이면 a의 값만 월들히 크고 나머지 값들은 작지만 이 차이를 낮게 하여 만약 도메인 b가 다른 도메인 보다는 큰 수를 가지고 있다고 하면 teacher은 a도메인과 b도메인을 비슷하게 보고 있고 이러한 디테일한 성향을 student가 학습하도록 하게 한다.)
Zero-mean assumption
참고 자료
https://arxiv.org/pdf/1503.02531.pdf
수식 유도과정 - https://drive.google.com/file/d/1N8lOUoAAIodT7IuRIRRG5i9I2Ltpbxh9/view
✔️ Knowledge distillation이 model compression이다라고 하는 것은 어폐가 있다
✔️ Special한 케이스에서만 model compression인데 Zero-mean assumption이 참일 때 model compression이라고 한다.
✔️ Teacher network의 logit들(softmax통과하여 나온 값들)이 zero mean이 아닐 경우 model compression이라고 하기에는 애매한 부분이 있다. => 다른 데로 값이 튀거나 할 수 있기 때문에(즉, zero mean이 되려면 총 합은 1이고 분모값이 매우 작아야 한다는 의미이다.)
💡 포인트는 어떤 전제가 참이 되어야만 Knowledge distillation이 model compression이다.
여러 distillation
- Feature distillation
참고 자료
https://arxiv.org/pdf/1904.01866.pdf
- Data-free knowledge distillation
참고 자료
https://arxiv.org/pdf/1710.07535.pdf
Reference
Naver BoostCamp AI Tech - edwith 강의
