
Data Augmentation
✔️ CNN으로 학습된 neural network는 dataset의 특징들을 압축하여 저장한다.
✔️ 대부분의 사진들은 보기 좋게 찍힌 경우가 많기 때문에(예를 들어 사진사에 의해 찍어진 사진) 이 데이터만 이용하서 학습을 진행하게 되면 실세계에 있는 다양한 상황의 데이터를 커버하지 못하는 편향(bias)이 생기게 된다.
👉 만약 고양이를 분류하고자 할 때 학습한 사진이 모두 밝은 사진이라면 어두운 사진에 대하여는 커버하지 못하는 상황이 발생
✔️ Data Augment는 이러한 상황을 극복하고자 이미지를 여러 방법을 통해 변형(transform)한 뒤 네트워크의 입력 이미지로 사용하는 방식이다. 따라서 이미지를 부풀려 현실 세계의 데이터 분포처럼 만든다.
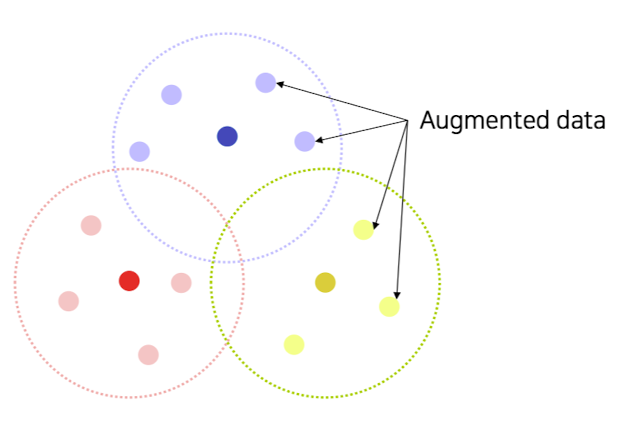
출처 : Naver BoostCamp AI Tech - edwith 강의
💡 학습 데이터는 극히 일부고 bias된 데이터가 대다수를 차지
✔️ 변형(transform)하는 방법에는 여러 방법들이 존재한다 => Crop, Shear, Brightness, perspective, Rotate
➡️ Brightness adjustment : 밝기 조절
➡️ Rotate, flip : 영상을 회전시키거나 뒤집음
➡️ Crop : 사진의 일부만 학습시켜 중요한 부분에 대해 더 강하게 학습
➡️ Affine transformation
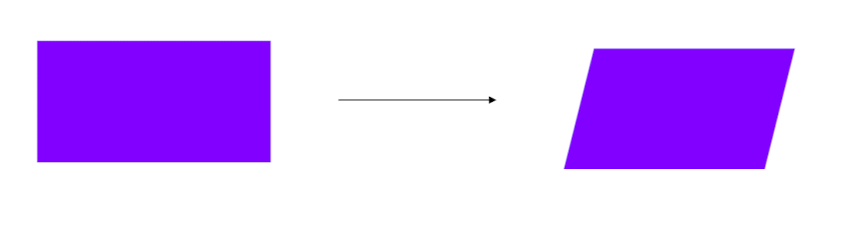
출처 : Naver BoostCamp AI Tech - edwith 강의
사진을 위와 같은 모양으로 분리 시키며 변환은 아래와 같은 규칙을 만족하며 바뀌게 된다.
1, 선은 선으로 유지
2, 길이 비율 유지
3, 평행 유지
원래 , 2 x 2 행렬과 trans parameter 2개로 총 6개의 변환행렬 값들을 필요로 하나 OpenCV를 이용시 3점의 위치변환으로 변환 표현이 가능
rows, cols, ch = image.shape
pts1 = np .float32([[50,50],[200,50],[50,200]])
pts2 = np .float32([[10,100],[200,50],[100,250]])
M = cv2.getAffineTransform(pts1, pts2) # 6개의 원소를 가지는 변환행렬 나오게 됨
shear_img = cv2.wrapAffine(image, M, (cols,rows)) # 픽셀 위치를 옮겨주는 작업을 warping이라고 통상적으로 지칭➡️ CutMix : 두개의 사진을 일정한 비율로 합쳐 학습을 진행하고 라벨 또한 라벨을 일정한 비율로 섞어 학습이 일어나게 된다. 또한 물체의 위치도 더 정교하게 catch하도록 학습된다.(아래의 그림의 경우 0.3을 얻기 위해 어떻게 학습해야 하는지에 대한 위치도 학습)

출처 : Naver BoostCamp AI Tech - edwith 강의
➡️ RandAument : 많은 augmentation방법이 존재하고 가장 좋은 방법들을 골라내기 힘들기 때문에 모든 가능성을 캄색하기 힘드니 랜덤하게 Augmentent들을 뽑아내어 수행 해 보고 성능이 잘 나오는 것을 사용

출처 : Naver BoostCamp AI Tech - edwith 강의
👉 어떤 augment를 사용할지 결정
👉 얼마나 강도를 줄지 결정
👉 어떤 조합을 사용할 건지 결정
💡 desugn choice를 하기 어려우니 랜덤하게 sampling하여 수행하고 이를 토대로 기계가 결정 해 줌

출처 : Naver BoostCamp AI Tech - edwith 강의
💡 Policy : 하나의 augmentation 기법들의 sequence를 pilicy라고 한다.
⭐️ 데이터셋 변형의 목표는 데이터셋의 분포(경향)를 실세계의 분포(경향)와 비슷하게 만드는 것이다.
Leveraging pre-trained information
✔️ 지도학습은 많은 양의 데이터가 필요하나 annotating하는 비용이 비싸기 때문에 적은 데이터 셋 양으로도 실질적으로 학습이 가능한 방법으로써 Transfer learning 방법이 나오게 되었다.
✔️ 하나의 모델이 이존에 있는 모델을 따라하도록 만드는 Knowledge distillation이 존재한다. pre-traine 모델이 가지고 있는 지식을 이용하는 더 진보된 방법이다.
Transfer learning
✔️ 새로운 task에 대하여 pre-trained knowledge적용이 가능
✔️ 하나의 데이터 셋에 대한 정보는 다른 데이터셋 정보와 유사하기 때문에 pre-trained knowledge적용이 가능한 것이다.
✔️ 마지막 층만 잘라내어 수행하고자 하는 새로운 task에 대하여 작동을 하는 fully connected layer를 추가해 새로운 작업을 하는 모델을 만든다.
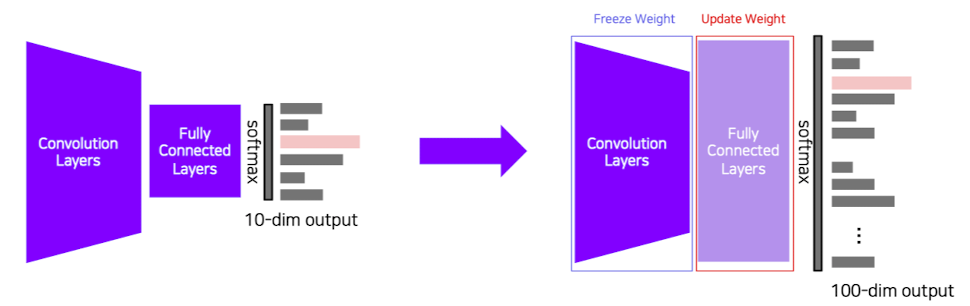
출처 : Naver BoostCamp AI Tech - edwith 강의
✔️ Fine-tuning의 개념을 사용하여 이미 학습된 부분도 재차 학습을 아되 learning rate를 낮게 주워 학습 폭을 작게 하고 마지막 층 부분만 learning rate를 크게 하여 학습폭을 키워 학습을 진행한다.
이때, Fine-tuning은 이미 학습된 부분을 약간 학습시키는 행위를 지칭한다.
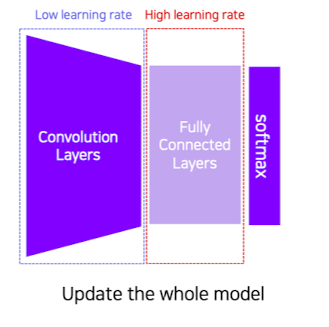
출처 : Naver BoostCamp AI Tech - edwith 강의
Knowledge distillation
✔️ 보통 작은 모델이 큰 모델을 따라하도록 학습이 된다.
✔️ pre-trained된 모델을 Teacher, 이에 따라 학습하는 모델을 Student라고 한다.
✔️ 라벨이 없는 데이터셋을 사용(pre-trained된 모델의 결과로 나온 라벨을 정답 라벨이라 생각하고 수행)하기 때문에 unsupervised learning이다.
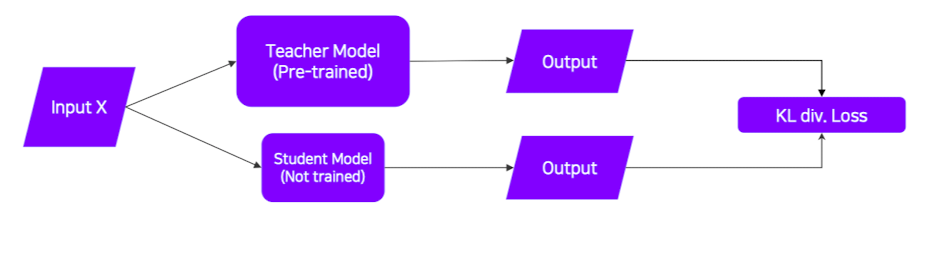
출처 : Naver BoostCamp AI Tech - edwith 강의
(이때, 학습은 student 모델에 대해서만 업데이트가 된다.)
✔️ 이때, 실제 라벨링이 된 데이터를 사용할 수 있으면 답은 실제 답을 따라가도록 학습을 하되 답이 나오는 개형은 pre-trained된 모델처럼 되도록 학습이 진행된다.(Distillation Loss와 Student Loss는 다른 Task일 수 있다.)
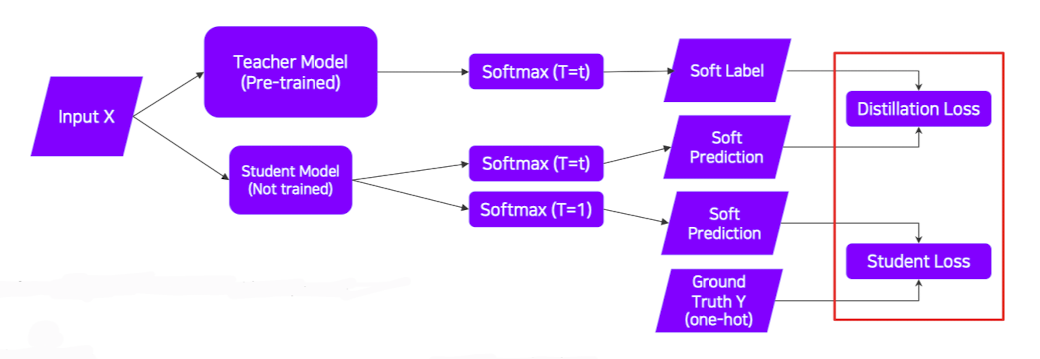
출처 : Naver BoostCamp AI Tech - edwith 강의
👉 Hard label : One-hot vector / Soft label : 전형적인 모델의 output으로 모델이 현재 어떻게 생각하늕지 수치로써 볼 수 있고 위의 그림의 soft prediction은 이 Soft label이 나오도록 해 주는 예측이라고 보면 된다.
👉 Softmax(T=t)는 "Softmax with temperature"를 뜻하며 작은 입력 값과 큰 입력 값 간의 출력 차이를 제어한다.

T가 클수록 큰 입력값 차이를 줄여주게 된다.
극단적인 값보다는 중간값에 가까운 값이 나오도록 하여 더 정교하게 Student가 Teacher를 따라하도록 한다.(너무 극단적인 값이 나오면 약하게 생각하는 부분에 대해서는 정보가 없기 때문이다.)
👉 Distillation Loss
1️⃣ KLdiv(Soft label, Soft prediction)<2개의 distribition이 있을 때 distribution의 차이,거리를 잼>사용
2️⃣ Loss : tacher과 student사이의 차이를 계산
3️⃣ teacher가 알고있는것을 흉내내며 학습
👉 Student Loss
1️⃣ CrossEntropy(Hard label, SOft prediction)사용
2️⃣ Loss : 실제 정답 라벨과 Studnet 네크워트의 추론값의 차이를 계산
3️⃣ 실제 답을 배움
Leveraging unlabeled dataset for training
✔️ Semi-supervised learning
label이 있는 데이터는 대규모 데이터 셋을 모으는데 한계가 있는 반면 label이 없는 대규모 데이터 셋은 인터넷상에서 무궁무진하게 구할 수 있다.
이에 따라, Semi-supervised learning개념이 나왓는데 Unsupervised (no label)과 Fully Supervised(fully lableled)를 합친 개념이다.
✔️ label이 있는 모델을 학습 시킨 후 label이 없는 데이터에 대하여 모델을 이용하여 Pseudo label을 생성 후 이 데이터와 label이 있는 데이터를 이용하여 새로운 모델을 학습 시킨다.
Slef-training
✔️ Data Augmentation, Knowlegde distillation, Semi-supervised learning 이 방법론들을 잘 결합히면 이미지넷에서 새로운지평을 연 연구가 탄생하였는데 이것이 Self-Training이다.
(논문 링크 - https://arxiv.org/abs/1911.04252)
✔️ 진행 과정은 다음과 같다.
1, labeled data를 이용하여 teacher model을 학습
2, unlabeled data에 대하여 Psedo-label생성
3, labeled data와 Psedo-label이 붙은 데이터를 이용하여 RandAugment를 수행하고 Student model생성(이때, Knowlegde distillation와 다른점은 Student model은 점점 커지는 방향으로 아키텍처가 설계)
4, student 모델을 teacher모델로 하고 이러한 과정을 2 ~ 3번 반복
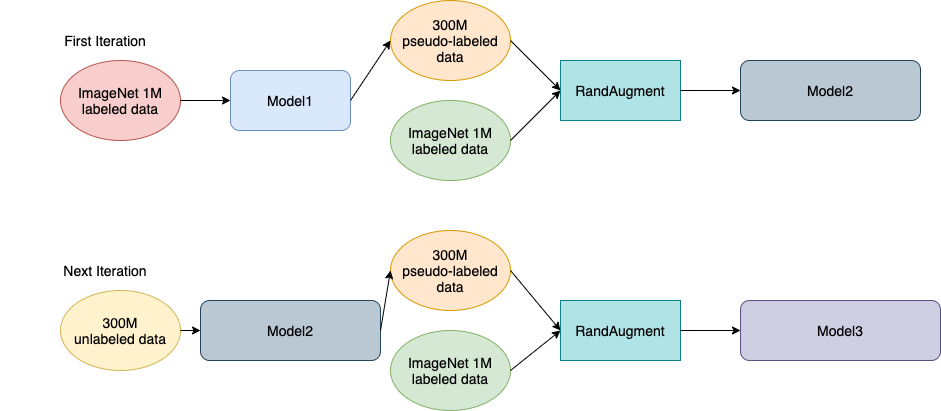
이때, RandAugment는 매 iteration이 수행이 되며 사용이 되고 변형된 데이터가 다음 iteration에서 누적해서 사용되는 것이 아닌 기존 데이터에 대하여만 RandAugment가 반복적으로 수행이 되어진다.
Reference
Naver BoostCamp AI Tech - edwith 강의
