
기본 컨셉 코드
print(0.1 + 0.2, 0.1 + 0.2 == 0.3)
print(0.1 + 0.3, 0.1 + 0.3 == 0.3)0.30000000000000004 False
0.4 Falsesum = 0
for i in range(7):
sum += 1.0/7.0
print(sum, sum == 1.0)0.9999999999999998 False⭐️ 결론부터 얘기하자면 파이썬은 소수점을 부동 소수점으로 처리하여 완전하게 정확한 수를 저장하기 힘든 상황이 벌어질 수 있다.
예를 들어 0.3이라는 수를 2진법으로 표현해 보면 다음과 같다.
0.3 * 2 = 0.6 => 0
0.6 * 2 = 1.2 => 1
0.2 * 2 = 0.4 => 0
0.4 * 2 = 0.8 => 0
0.8 * 2 = 1.6 => 1 ....
따라서, 0.3의 표현은 0.01001...이렇게 무한 반복이 되는 상황이 벌어지게 된다.
IEEE 754 2진법 32bit Floating point 방법에 따르면 32비트 안에 소수를 저장하게 됨으로써 완전하게 정확한 수를 저장할 수 없는 상황이 벌어지고 다음과 같은 결과를 보게 되는 것이다.
양자화를 이용한 경량화는 이렇게 제한된 메모리에 데이터를 다루는 컴퓨터에서 다소 오차가 발생할 수는 있지만 좀 더 적은수의 비트를 사용해 연산을 처리하면 메모리, 속도 측면에서 훨씬 빠르게 task를 수행 할 수 있게 한다.
fixed point, floating point

출처 : Naver BoostCamp AI Tech - edwith 강의
👉 32-bit fixed-point : 정수 부분과 소수 부분을 그대로 구역을 나누눠 저장, 32bit Floating point방법에 비하여 메모리를 비 효율적으로 사용하는 형태
👉 IEEE 754 2진법 32bit Floating point : 기본 컨셉 코드에서의 설명과 동일
대부분의 언어들은 기본적으로 IEEE 754 2진법 32bit Floating point을 제공하고 fixed-point을 사용하기 위해서는 직접 구현하거나 라이브러리를 이용해야 한다.
✔️ 32-bit fixed-point
장점
- 소수를 정확하게 나타낼 수 있다.
- 더하기와 빼기에서 오류가 없음
- 크기 및 전력소비 => Floating point보다 계산량이 적기 때문에 chip사이즈가 작고 이에 따른 전력소비 또한 적음
- 가격 비용
- 일부 프로세서에서는 산술이 훨씬 빠름
- 메모리 사용과 스피드 측면 => 계산시 메모리와 프로세서 시간이 적게 필요하다.
단점
- 값의 동적 범위가 훨씬 적다.
- 곱셈에 대하여 다소 문제가 있다.
참고 자료
https://www.mathworks.com/help/fixedpoint/gs/benefits-of-fixed-point-hardware.html
✔️ Floating Point Unit(FPU)
부동 소수점 장치로써 예전에는 CPU와 분리되어 존재하였었으나 최근에는 CPU안에 내장되어있는 형태로 많이 나오고 심지어 차지하고 있는 부분 또한 큰 부분을 차지하고 있다
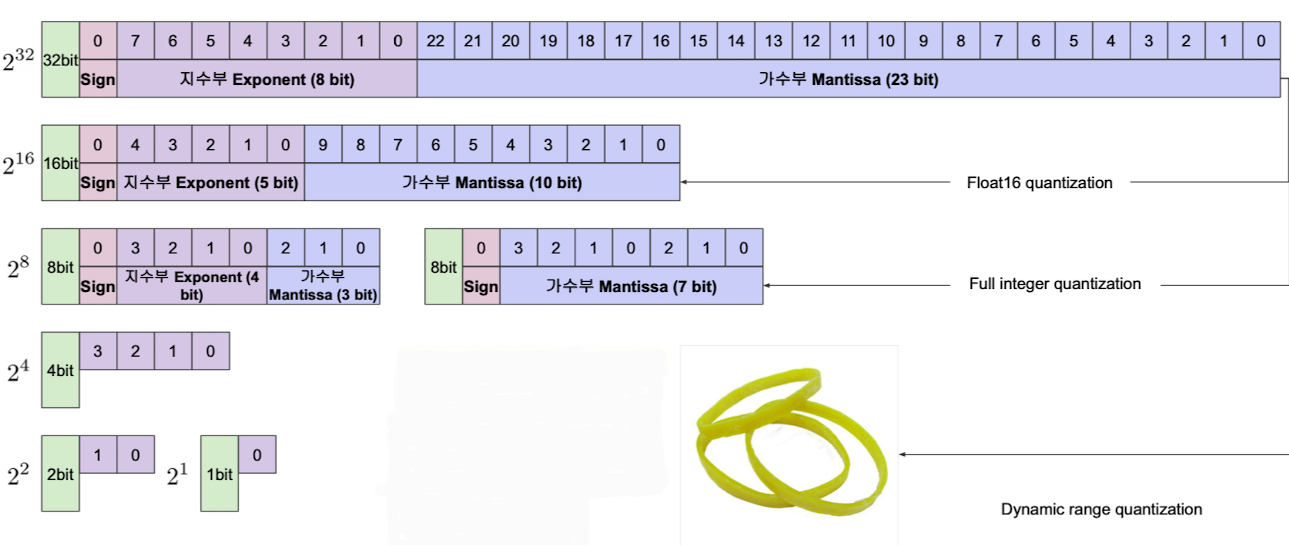
✔️ 사용비트에 따른 부동소수점 표현력
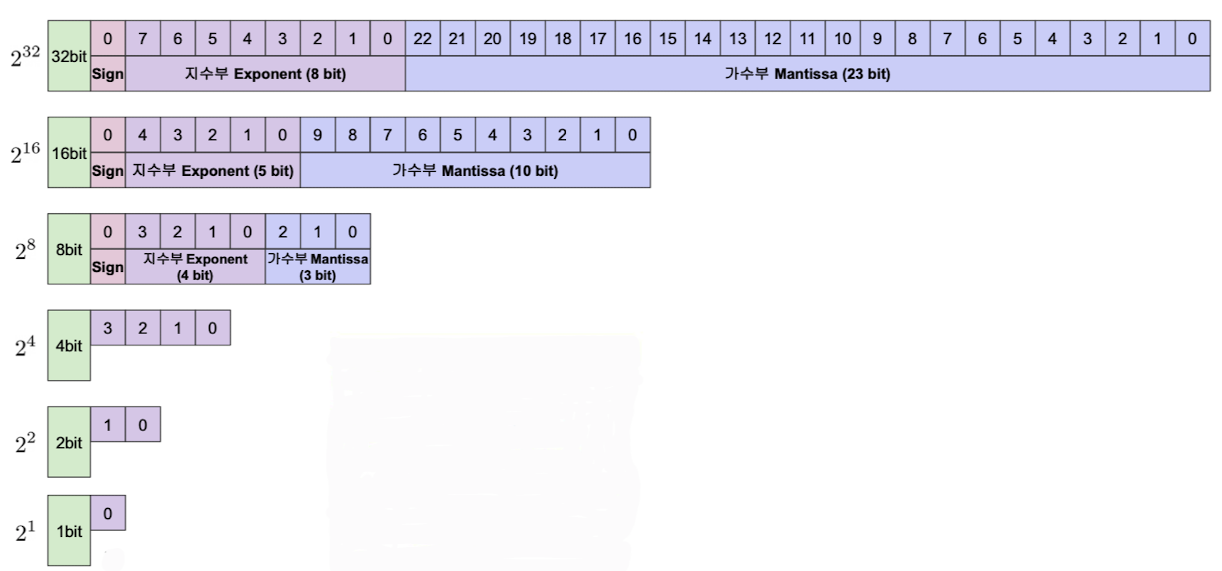
출처 : Naver BoostCamp AI Tech - edwith 강의
Quantization이란
✔️ 목표 및 특징
- model size를 줄이자
- memory bandwith requirements 감소
- int8연산이 float32보다 훨씬 빠름
- 추론 속도를 높히는 기술(train속도를 높히기 보다는) -> 양자화된 연산자에 대해서는 순방향 패스만 지원됨
✔️ float32를 int8로 표현을 하게 되면 기존의 데이터에 비해 표현할 수 있는 데이터가 정교하지 못하다는 단점이 있게 된다.

출처 : Naver BoostCamp AI Tech - edwith 강의
참고 자료
https://www.youtube.com/watch?v=DDelqfkYCuo
✔️ Affine quantization
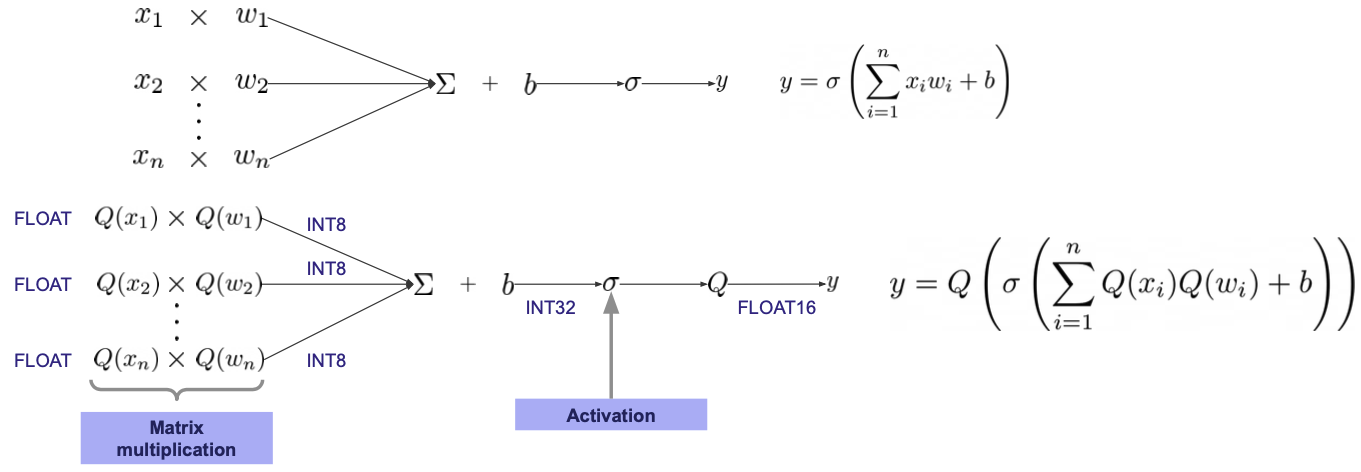
출처 : Naver BoostCamp AI Tech - edwith 강의
참고 자료
Affine quantization 수식 유도 과정 - https://leimao.github.io/article/Neural-Networks-Quantization/
✔️ 역전파 수행 시 Quantize를 수행하게 되면 기울기가 정의되지 않는 부분이 있기에 역전파 수행시에만 원래의 데이터에 대한 그래프의 기울기를 사용하게 된다.

출처 : Naver BoostCamp AI Tech - edwith 강의
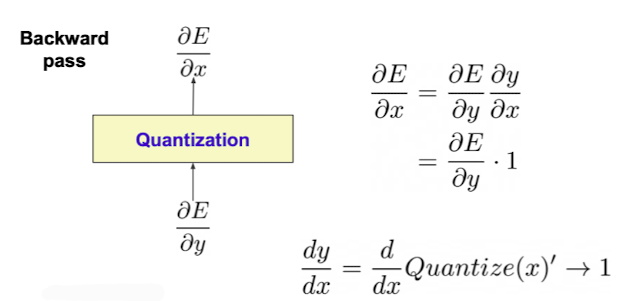
출처 : Naver BoostCamp AI Tech - edwith 강의
✔️ 이러한 문제점을 해결하기 위해 또 다른 방법은 현재는 Quantize를 수행 시 계단모양이기에 해당 문제가 생기게 되는데 이러한 계단 모양을 조금 smooth하게 만들어서 기울기가 없는 문제를 해결하는 방법 또한 존재한다.
참고 자료https://openaccess.thecvf.com/content_CVPR_2019/papers/Yang_Quantization_Networks_CVPR_2019_paper.pdf - Figure2
추가 참고 자료
https://arxiv.org/pdf/1606.06160.pdf
https://papers.nips.cc/paper/2016/file/d8330f857a17c53d217014ee776bfd50-Paper.pdf
여러 quantization들
✔️ 다양한 quantize를 하는 기준들이 존재한다.
- Dynamic VS Static
Dynamic : 값 자체는 float형태로 두웠다가 계산시에 quantize해주는 작업으로 진행이 되어 진다.
Static : Dynamic에서 더 나아가 모든 연산의 결과도 int8의 형태로 저장 - Post-training VS Quantization-aware traning
Post-training : (Dynamic , Static을 포함하는 개념)Traning한 후에 quantize를 적용
파라미터 size 큰 모델에서 정확도 하락 폭이 작으며 파라미터 size 작은 소현 모델에서는 적합하지 않다.
Quantization-aware traning : traning과정에 quantize를 함 -> fake node를 첨가하여 quantize되었을 시 어떻게 수행이 될지 시뮬레이션을 돌려봄 => 원래 training loss가 수행되는 것이 약간 틀어져서 Quantize된 것 까지 고려하여 trainig
양자화 모델의 정화도 하락을 최소화
참고 자료
https://pytorch.org/docs/stable/quantization.html
Qunatization-aware training - https://github.com/tensorflow/tensorflow/tree/r1.13/tensorflow/contrib/quantize
✔️ quantize에 따른 모델 traing 방향
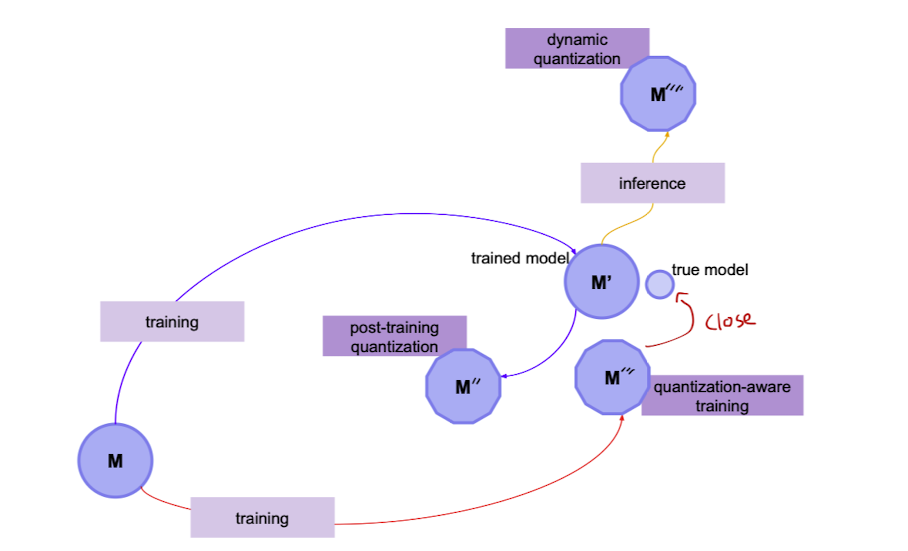
출처 : Naver BoostCamp AI Tech - edwith 강의
✔️ Hardware종류마다 quantize가 지원되는 종류는 다양하다.
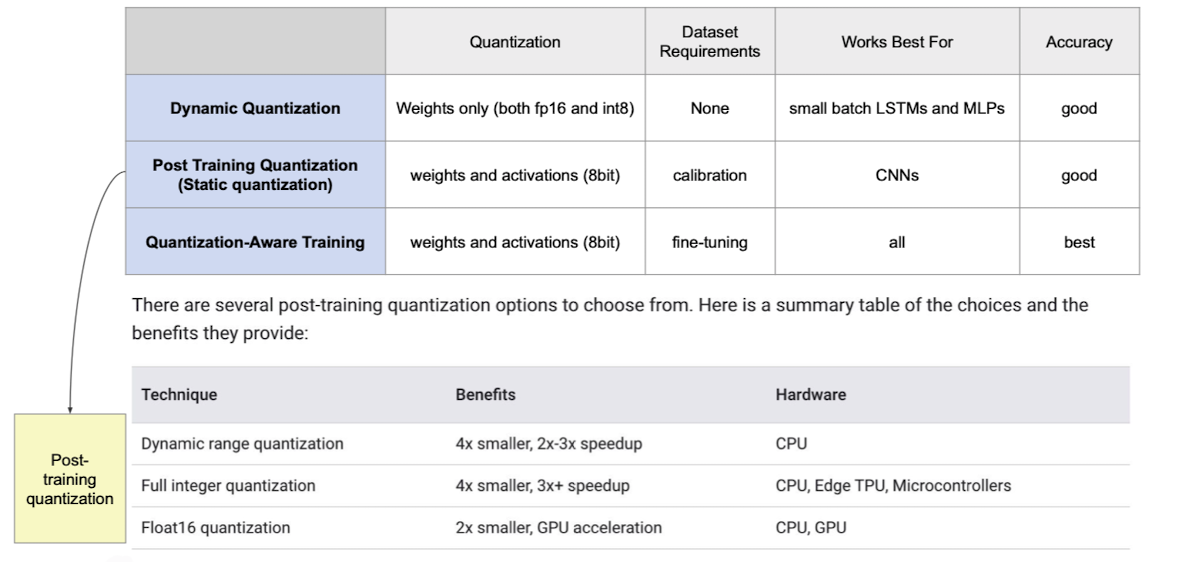
출처 : Naver BoostCamp AI Tech - edwith 강의
이때, Post-traning quantization의 경우 모델이 quantize되더라도 하드웨어가 없어 못돌리는 경우도 존재하는 것도 확인 해 볼 수 있다.
참고
https://wannabeaprogrammer.tistory.com/42
참고 자료
https://www.tensorflow.org/lite/performance/post_training_quantization
✔️ Post-training quantization
출처 : Naver BoostCamp AI Tech - edwith 강의
참고 자료
https://blog.tensorflow.org/2019/06/tensorflow-integer-quantization.html
✔️ 어떤 quantization사용해야 할지에 대한 참고자료
-> https://arxiv.org/pdf/2004.09602.pdf
✔️ 이 뿐만 아니라 하드웨어마다 어떤 quantization을 사용해야 할 지에 대한 다양한 논문들 또한 다양하게 존재
-> https://openaccess.thecvf.com/content_CVPR_2019/papers/Wang_HAQ_Hardware-Aware_Automated_Quantization_With_Mixed_Precision_CVPR_2019_paper.pdf
✔️ 어느 Quantization이 좋을지 자동으로 전해주는 알고리즘 또한 존재
-> https://openaccess.thecvf.com/content_CVPR_2019/papers/Wang_HAQ_Hardware-Aware_Automated_Quantization_With_Mixed_Precision_CVPR_2019_paper.pdf
Reference
Naver BoostCamp AI Tech - edwith 강의
https://wannabeaprogrammer.tistory.com/42
