
Seq2Seq
-
RNN의 Many To Many유형을 처리할 때 많이 쓰인다.
-
보통 기계어 번역 부분에 많이 사용되어지며 encoder와 decoder부분으로 처리가 되어지며 encoader부분은 입력 데이터를 처리하게 되고 decoader 부분은 출력값을 처리하게 된다.
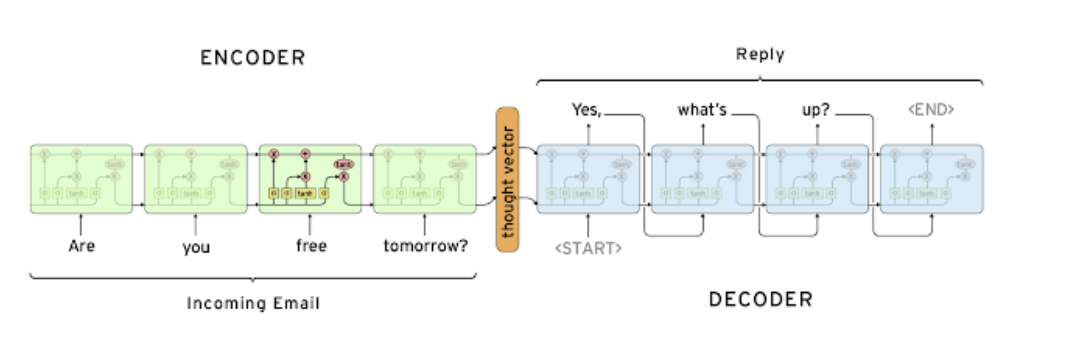
출처: Naver BoostCamp AI Tech - edwith 강의 -
특징
1, 내부의 셀은 LSTM셀을 사용한다.
2, 문장의 길이와 상관 없이 하나의 hidden state를 decoader에 넘겨주게 된다(이로 인해, input데이터의 앞의 데이터 부분이 손실이 많이 일어나게 되고 이를 극복하기 위해 Attention기법이 나오게 되었다.)
또한, 이런 특징으로 인해 보통 문장에서 중요하게 작용을 하는 부분이 주어 부분인데 앞 부분에 위치하여 그 의미가 많이 희석이 되어지고 이를 극복하고자 문장의 역순 넣어 학습시키는 trick도 존재하였다.
Attention
-
Seq2Seq의 긴문장을 해결하지 못하는 부분을 해결하기 위해서 나온 기법이다.(bottleneck problem의 해결)
-
decoder는 encoder의 각각의 hidden state를 고려하여 좀 더 focus를 맞추고 싶은 데이터에 attention을 취하게 되고 이에 따라 좀 더 세밀한 output을 도출 할 수 있게 된다.
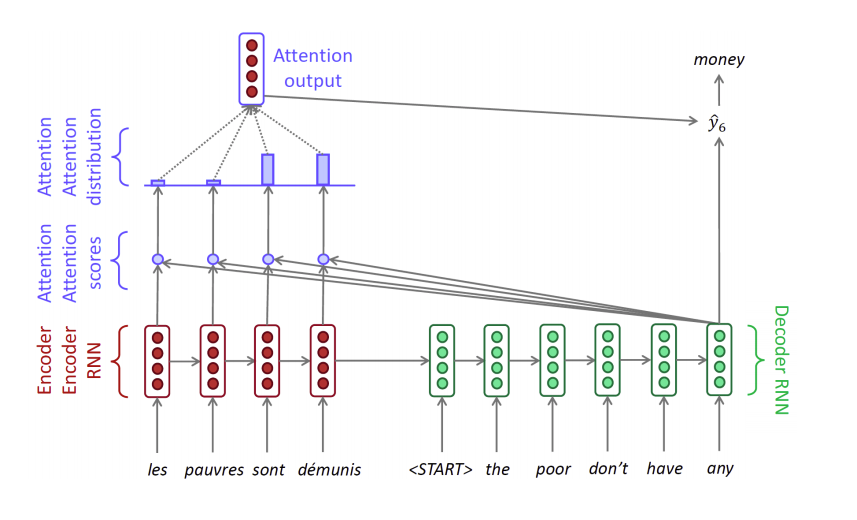
출처: Naver BoostCamp AI Tech - edwith 강의
아웃풋의 도출 과정은 다음과 같다.
1, encoder의 각각의 hidden state는 저장이 되어 있다.
2, encoder의 마지막 hidden state는 decoder에 들어가게 된다.
3, decoder의 hidden state는 input값과 연산이 진행이 되어 hidden state가 업데이트가 되어 진다.(LSTM부분 참고)
4, 이렇게 나온 hidden states는 encoder의 각각의 hidden state와의 내적 연산을 통하여 score를 만들어 낸다.(scalar값)
5, score 값들은 softmax를 통과하여 가중치를 만들어 내게 된다.(합이 1인 형태의 벡터를 가중치 벡터라고 한다.)
6, 이 가중치를 적용하여 각각의 encoder의 각각의 hidden state에 곱하여 더해주워 attention output을 만들어 내게 된다.(가중치 평균)
7, decoder의 hidden state벡터와 attention output벡터는 concat되어 output layer의 입력값으로 들어가게 된다.
8, output layer를 통해 output값이 나오게 된다.
이러한 연산의 형태로 인하여 아웃풋 값이 도출되게 되고 "EOS"토큰(문장의 끝)이 아웃풋으로 나올 시 역전파를 수행하게 되는데 attention output통해 가중치 벡터를 도출해 내는 layer의 가중치 벡터 또한 학습이 되어지는 과정을 볼 수 있다.(즉, 어느 input값이 영향을 많이 미치는 지에 대한 학습이 이뤄진다고 볼 수 있다.) -
teacher forcing 방법
학습 진행시에 원래는 decoder진행하면서 도출된 값(inferencing과정으로 나온 값)을 input값으로 넣어주면서 학습을 시켜워 원래 동작 방식과 같은 것인데 학습 수행 시 하나의 단어에서 output이 잘못되면 뒤의 부분은 대부분 이상한 값이 나오게 된다고 생각 할 수 있다.
이에 따라 학습시에는 제대로 된 문장(ground tools)을 input으로 넣어서 학습을 시켜주게 되는데 이를 teacher forcing이라고 한다. 이에 따라, 학습이 빠르고 용이하게 이뤄 질 수 있다.
하지만, 이러한 방법은 실제 동작 방식과는 괴리가 있다는 단점이 있어 teacher forcing을 초반 training때만 진행을 하고 모델이 안정적으로 되면 학습 후반부에는 teacher forcing을 사용하지 않음으로써 test환경과 비슷한 방식으로 학습이 진행되게 하는 방법도 존재한다. -
score구하기
score를 구하는 선형변환 방식은 다양하게 존재한다.
은 decoder의 hidden state이고 는 encoader에서 각각의 word마다의 hidden state 벡터이다.
1, dot 방식은 단순한 내적 방식이다.
2, general 방식
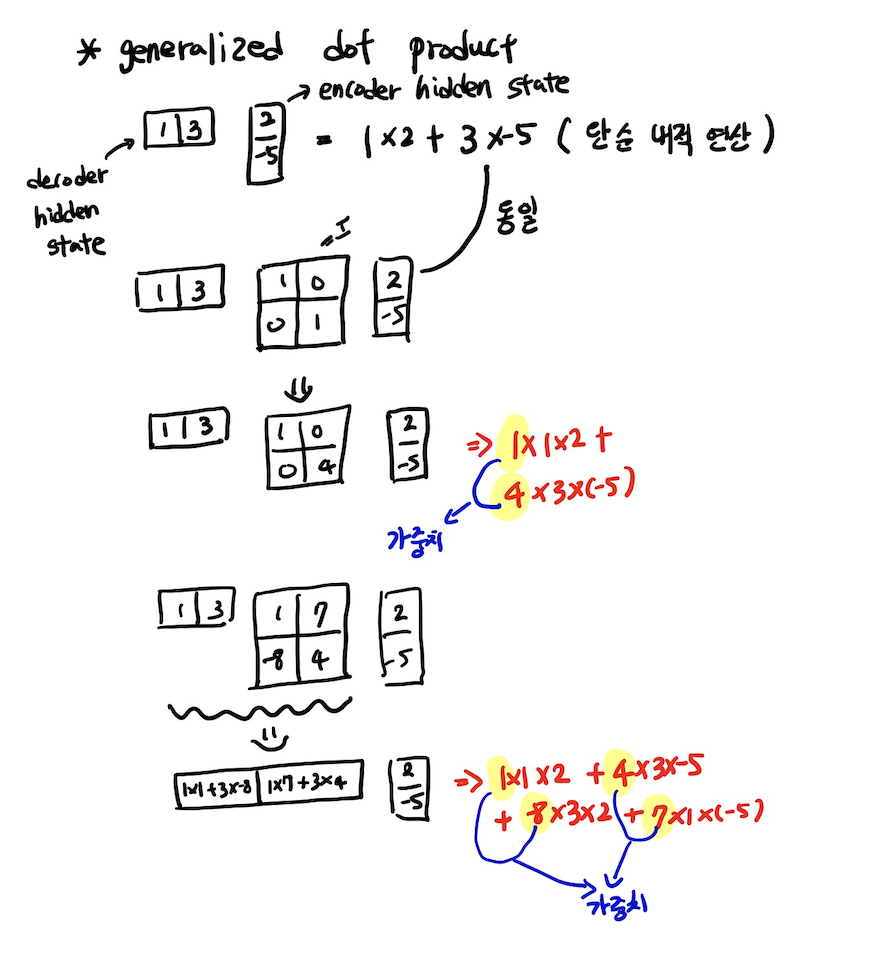
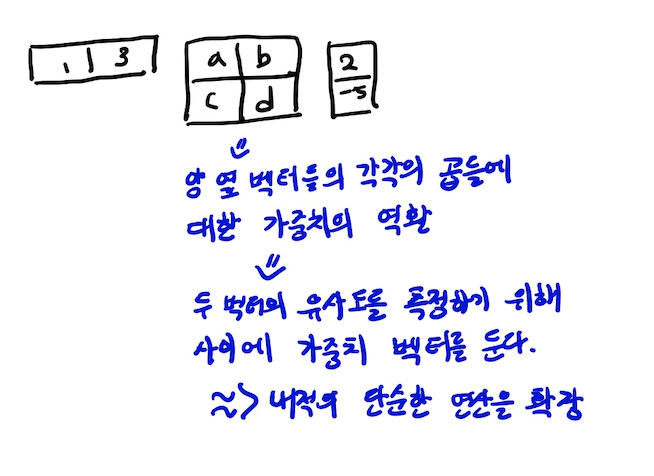
3, concat방식
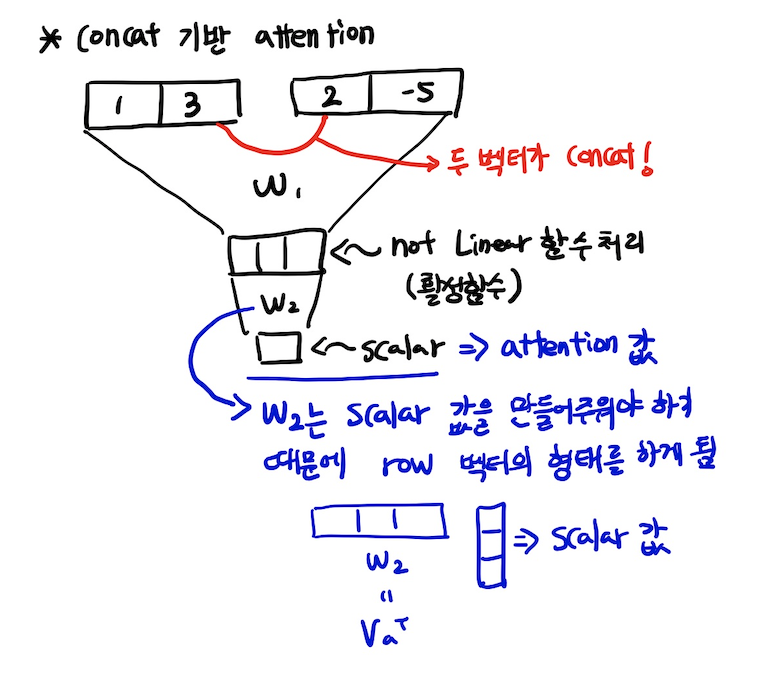
general 방식과 concat방식은 역전파로 인한 학습이 가능하다.
Seq2Seq와 Attention의 차이
- Attention이 Seq2Seq보다 좋은 점
1, 기계어 번역의 성능이 좋아짐
2, Seq2Seq는 긴 문장에 대하여 하나의 Hidden State로 처리하여 성능적 한계가 있었으나 Attention은 이를 극복
3,Attention Output을 이용한 역전파의 수행 덕분에 길이가 긴 hidden state를 거치지 않고 direct하게 역전파를 수행하며 이는 vanishing, exploding gradient 문제를 없애주는데 더욱 도움을 준다.
4, 흥미로운 해석의 가능성을 제공 해 준다.- decoder를 조사함으로써 input단어에 어디에 집중을 했는지 알 수 있다.

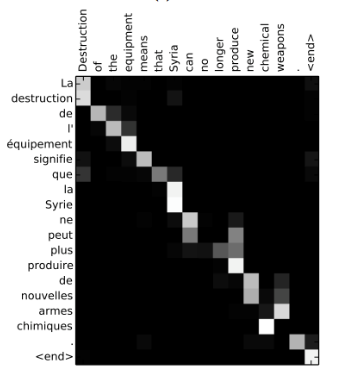
출처: Naver BoostCamp AI Tech - edwith 강의
- decoder를 조사함으로써 input단어에 어디에 집중을 했는지 알 수 있다.
Beam Search
-
Beam Search는 왜 나오게 되었을까?
decoder부분에서 하나의 output이 틀리게 되었을 시 다음 단어도 연속적으로 틀리게 될 가능성이 높기 때문에 이에 대하여 유연하게 대처하기 위하여 나오게 되었다. -
Greedy decoding
계속해서 input값을 넣어 나온 값을 다시 input으로 건네는 방식으로 한번 틀리면 돌아갈 방법이 없이 틀린 채로 계속해서 진행을 해야 한다. -
Exhaustive search
이때, input값을 라 하고 는 각각의 output의 값인데 목적은 를 키우는 것이다.
하지만, 현재 단어사전(고려하는 단어)의 수가 라 한다면 time step 에 대하여 다 고려를 해 준다면 의 시간복잡도로써 매우 큰 수이므로 차선책이 필요하였다 -
Beam Search
Greedy decoding와 Exhaustive search방법을 적절히 섞은 방법으로써 decoder 각각의 time step에서 가장 확률값이 높은 것(Greedy decoding 특성)을 k개를 골라(Exhaustive search 특성) 계속해서 고려 해 나가 준다.
이때의 확률는 hypothese라고 하고 k는 라고 한다.
(log값이 가장 큰 경우를 찾아보자 : log를 씌워 준 이유는 곱셈을 덧셈으로 만들어 주기 위해서이다.)
또한, 확률의 값은 0-1사이의 값인데 log함수의 성질에 의하여 항상 음의 수가 나오게 됨을 알 수 있다.(확률이 0또는 1인 경우는 현실에서는 찾아보기 힘들다.)
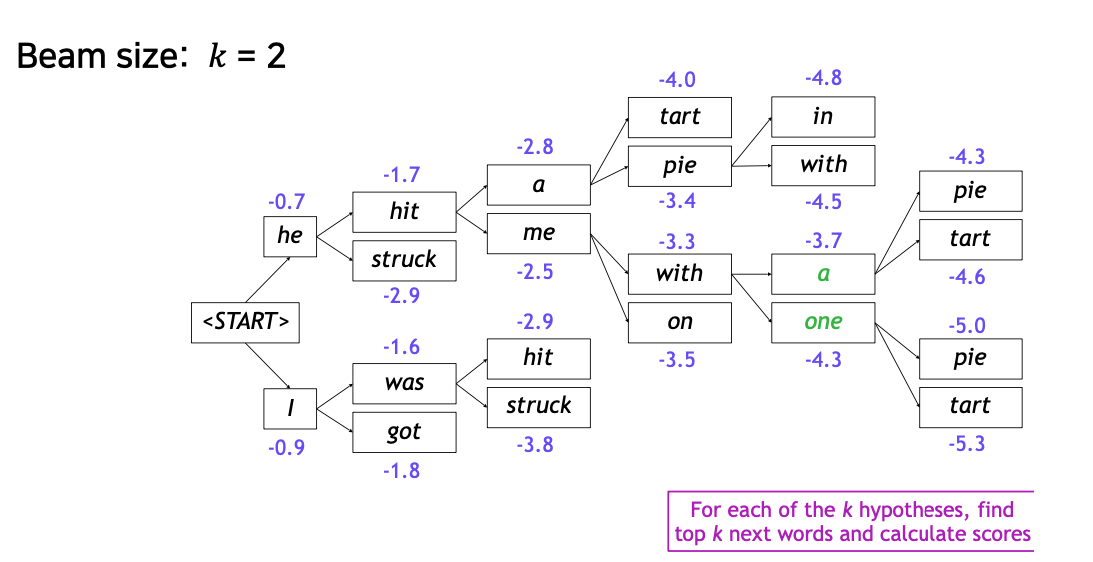
출처: Naver BoostCamp AI Tech - edwith 강의
위와 같은 방법으로 각각의 문장들에 대한 hypothese를 찾은 다음 그 값이 가장 큰 문장을 채택하여 output으로 내놓게 된다.
조사를 하다보면 각각 문장이 끝나는 시점이 다를 수 있는데 <END>토큰이 나온 경우(문장의 끝) 아직 조사가 더 필요한 분장이 있다면 임시로 저장공간에 저장하였다가 마지막 부분에서 판단하여 준다.
또한, 보통 조사하는 maximum길이를 정하여 일정 수준이 되면 아직 문장의 끝을 표하는 <END>토큰이 나오지 않더라도 완료를 해 주게 된다.
또한, 서로 길이가 다른 hypothese에 대하여 지속적으로 음수값이 더해지면 당연히 값이 작아질 수 밖에 없음으로 length에 대하여 정규화를 수행 해 준다.
BLEU score
-
BLEU score은 decoder의 성능지표를 수치화 하기 위하여 나온 개념이다.
-
전체 ground tool(input)값에서 output값이 하나라도 빠지게 되는 현상이나 단어가 밀리는 현상 등이 일어나게 되면 대응 형식으로는 평가가 제대로 수치화 되어 나타내어 지지 못한다.
I love you <-> Oh I love you(평가가 0%)

출처: Naver BoostCamp AI Tech - edwith 강의
1, Precision(정밀도)
실직적으로 느끼는 정확도로 현재 에측된 문장을 기준으로 얼마나 맞췄는지에 대한 수치로 생각할 수 있고 실제로 검색 결과로써 많이 사용되는 measure이다.(맞는 단어의 갯수를 예측 문장의 길이로 나눠 줌)
2, recall(재현율)
실질적으로 Reference를 얼마만큼 구현을 하였는지에 대한 수치로 생각할 수 있다.
3, F-measure
Precision와 recall의 조화평균이다.
참고
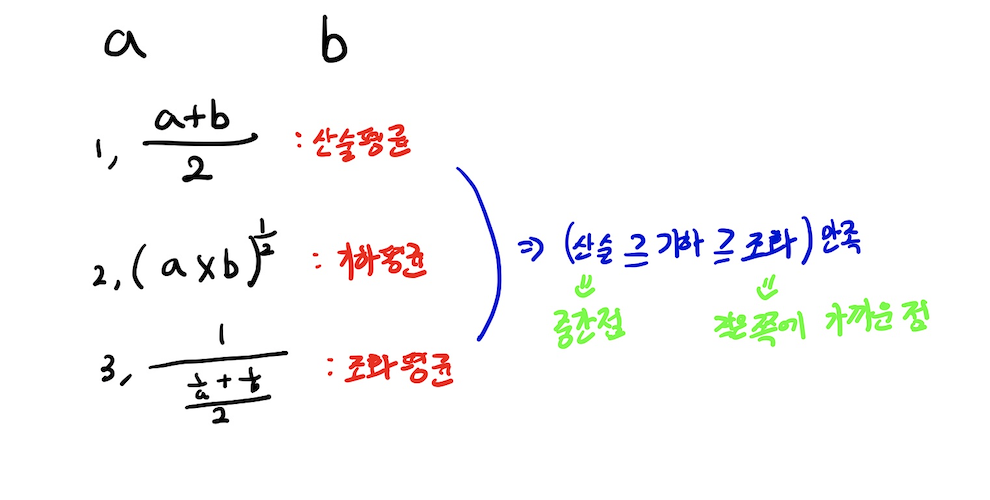
F-measure을 구하는 예시

출처: Naver BoostCamp AI Tech - edwith 강의
위의 예시에서 순서에 대한 정확도를 반영하지는 못하는 단점을 알 수 있다. -
F-measure를 사용하였을 시 순서에 대한 정확도를 반영하지 못하는 단점을 극복하기 위해 BLEU score라는 개념이 나오게 되었다.
-
BLEU score방법
- N-gram overlap방법 사용
- N-gram 고려 길이는 1 ~ 4까지
- brevity penalty를 줌(길이에 대한 패널티)
BLEU score를 구하는 예시
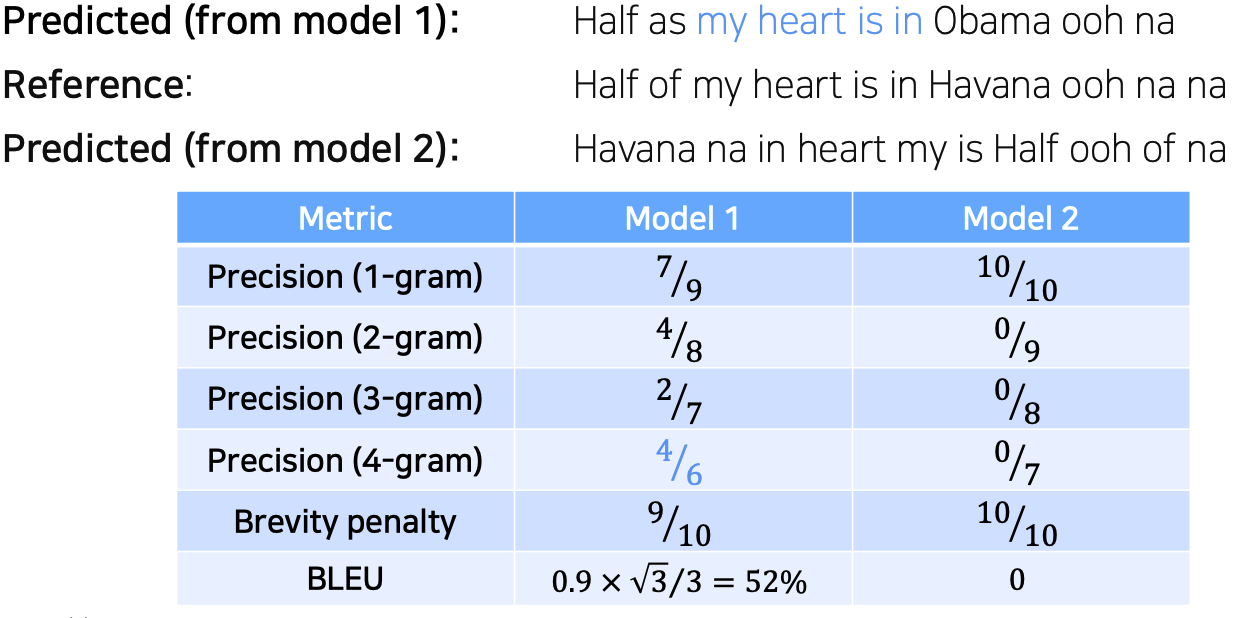
reference
Naver BoostCamp AI Tech - edwith
https://www.youtube.com/watch?v=WsQLdu2JMgI
