
GPT-1
-
GPT-1은 왜 탄생하였는가?
대부분의 딥러닝 학습은 라벨링이 되어있는 데이터를 활용하는 비지도학습을 하게 되는 데, 실제로 많은 데이터는 라벨링이 되어 있는 데이터를 구하기는 어렵다.
이에따라 텍스트 그대로를 활용하여 학습을 하는 unsupervised learning(비지도 학습)을 하여 학습할 수 있는 모델이 필요하였고 GPT-1이 탄생하게 되었다. -
라벨링이 되어지지 않은 텍스트 데이터에서 일정 수준 정보를 얻는 것은 두가지 한계점을 가지고 있다.
1, 어느 optimization이 전이학습에 유용한 텍스트 표현을 배우는데 효과적인지 불분명하다.
(이때, 전이학습이란 이미학습된 weight들을 transfer(전송)하여 자신의 model에 튜닝하여 학습하는 방법을 말한다.)
2, 학습된 표현을 다른 과제로 전이하는 가장 효과적인 방법에 대한 일치된 방법이 존재하지 않는다.
-
GPT-1의 활용 모델
출처: Naver BoostCamp AI Tech - edwith 강의
출처: Naver BoostCamp AI Tech - edwith 강의
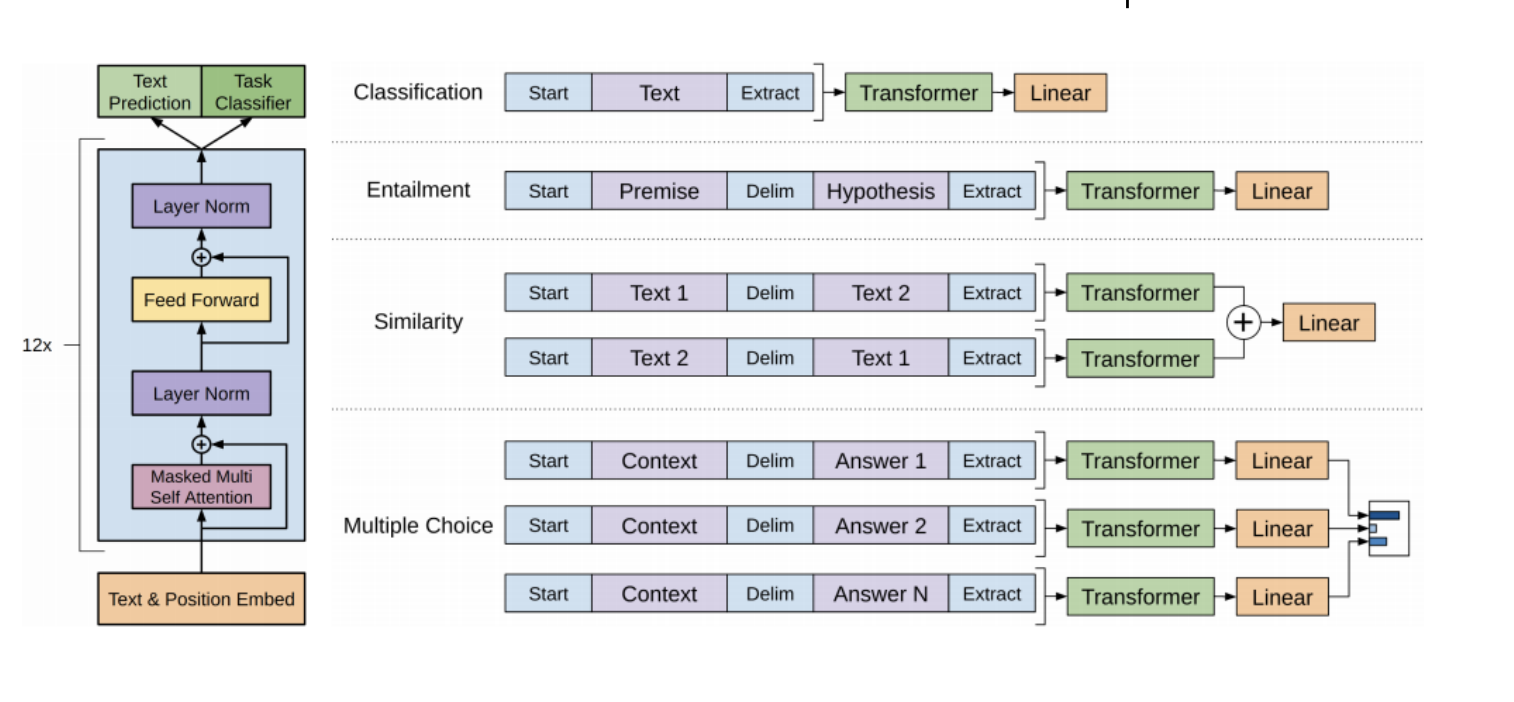
transformer의 decoder부분을 사용하고 있고 최종 아웃풋은 text Prediction, Task Classifier(Classification, Entailment, Similarity, Multiple Choice)의 아웃풋을 내 놓고 있다.
이때, 분류문제에 대하여 문장에 대한 다양한 표시를 해 주기 위하여 특별한 토큰등을 활용하여 분류 문제를 수행하게 된다.
(예를 들어, Entailment부분에서는 두 문장을 Delim토큰으로 구분을 하고 최종 Extract토큰에 대한 output 값을 이용하여 분류 문제를 수행하게 된다.) -
GPT-1의 활용
라벨링 되어지지 않은 데이터로부터 모델을 pre-traning을 시킨 후 특정 task에 맞게 fine-tuning과정을 거쳐 특정 task를 완료하도록 활용되어지고 있다.
pre-trainig : 기존 GPT-1의 모델에 대하여 Languagel Model및 Classifier에 대하여 학습을 시킨다.
fine-tuning : pre-trainig된 모델을 활용하여 해결하고자 하는 task에 맞게 model을 미세조정 한다.
=> 이때, fine-tuning을 하고 학습을 수행 할 시 미리 학습(pre-trainig)을 한 모델에 대하여는 learning rate를 작게 하여 학습의 폭이 작게 하고 새로 추가한 부분에 있어서는 learning rate를 크게하여 학습을 크게 하도록 수행을 한다.
(예를 들어, 해당 문장이 정치, 경제, 사회등... 분류 문제를 수행 할 때 맨 위의 층을 제거하고 word encoding vector를 이용하여 해결하고자 하는 task에 맞게 층을 위에쌓아서 task를 수행하게 된다.) -
Unsupervised pre-training
- objective function
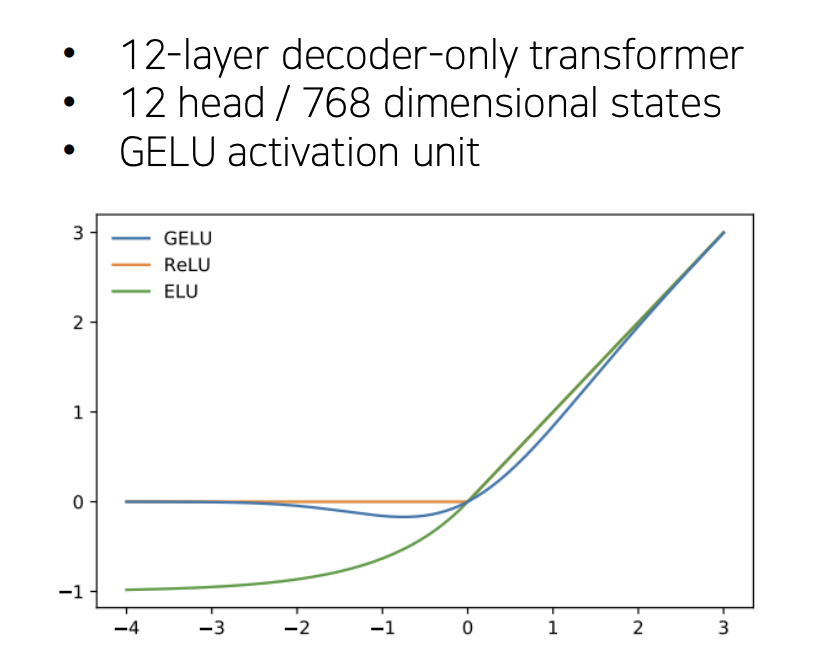
이때, k는 context window이고 조건부확률 는 parameter가 인 신경망을 사용하도록 되어 있고, SDG(확률적 경사 하강법)을 사용하였다. - 12개의 Tmulti-layer Transformer decoder 층을 사용하며 입력 문맥 token에 multi-headed self-attention을 적용하고 목표 토큰에 대한 출력분포를 얻기 위해 position-wise feedforward layer를 적용한다.
: 토큰의 문맥벡터
n : layer의 수
: token embedding행렬
: 위치 embedding 행렬
- objective function
-
Supervised fine-tuning
우도에 따라 모델을 학습 후 Parameter를 task에 맞게 미세조정을 한다.
입력 토큰 및 그 정답 레이블 y, 입력 데이터는 최종 transformer block의 활성값 을 얻기 위해 사전학습된 모델에 전달하고 결과는 다시 y를 에측하기 위해 parameter 에 대하여 fully connected layer를 통과하여 값을 얻어내고 이 우도를 최대화 하는 방향으로 학습을 진행한다.
따라서, 최종 목적함수는 다음과 같다.
이 식을 보게되면 언어모델()을 보조 목적함수로 사용하는 것을 볼 수 있는데
이 이유는 두가지가 있다.
1, 지도 모델의 일반화 향상
2, 수렴을 가속화
이를 통해 fine-tuning과정에서 추가된 파라미터는 와 구분자 token의 embedding이다. -
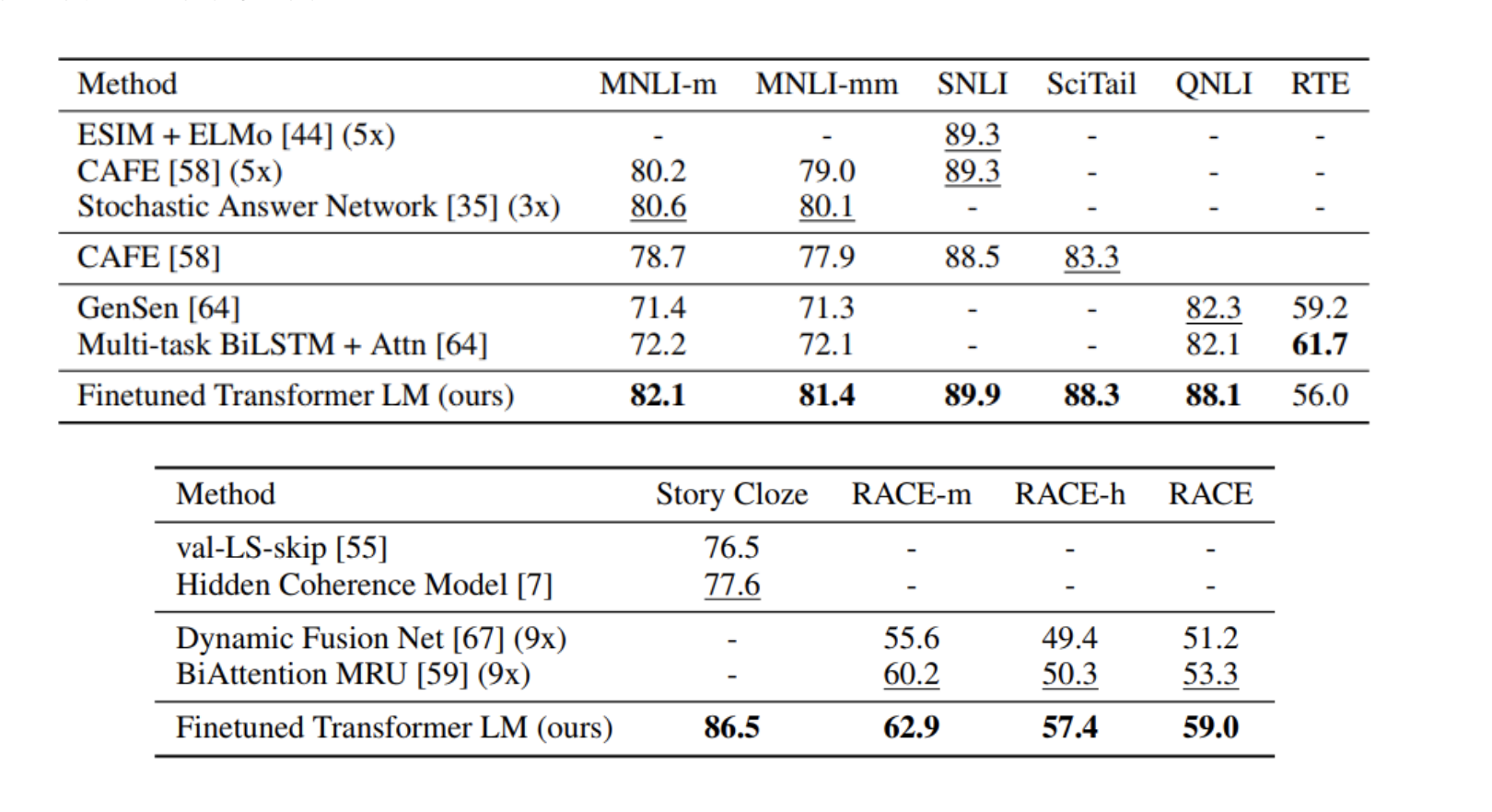
GPT-1의 성능평가 지표
출처: Naver BoostCamp AI Tech - edwith 강의
BERT
-
BERT는 구글에서 개발한 NLP(자연어처리)사전 훈련 기술이며, 특벙 분야를 벗어나 모든 자연어 처리 분야에 좋은 성능을 내는 범용 Language Model이다.
-
BERT는 '사전 훈련 언어모델'로써 GPT1과 마찬가지로 pre-training을 수행 한 후 fine-tuning을 통해 특정 task를 수행한다.
출처: Naver BoostCamp AI Tech - edwith 강의
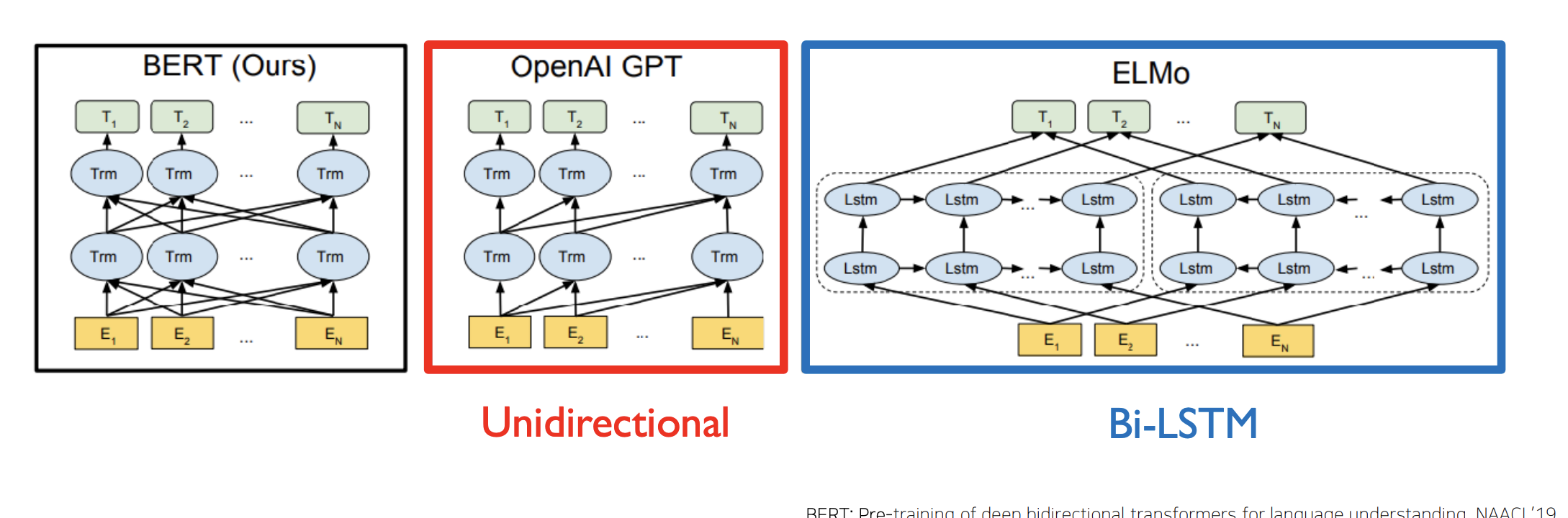
GPT1의 경우에는 전체 문장에 대한 단어의 관게도를 파악하는 것이 아닌 이전의 단어들에 대해서만 관계도를 파악한다면 BERT는 전체 단어를 고려해서 학습을 진행한다.
(GPT1 - transformer의 decoder부분, BERT - transformer의 encoder부분) -
Pre-traning
- [MASK]토큰의 자리에 알맞은 단어를 넣기
전체 문장에서 15%정도의 부분을 [MASK]
토큰으로 치환 한 후 이 부분을 맞추도록 학습이 진행되어 진다.

출처: Naver BoostCamp AI Tech - edwith 강의
이때, 15%의 수치는 너무 [MASK]토큰이 너무 많으면 토큰에 들어갈 적절한 단어를 유추하는 데에 정보가 부족하고 [MASK]토큰이 너무 부족하면 학습 효율과 시간이 너무 오래 걸린다.
따라서, 적절한 수치는 15%정도라고 논문에서는 밝히고 있다.
또한, [MASK]토큰에 대한 부작용도 존재를 하게 되는데 첫번째로는 pre-training당시에는 15%정도의 [MASK]
토큰이 있다가 문서의 주제분류같은 다양한 task에는 [MASK]토큰이 등장하지 않으므로 train환경과 test환경이 상이하다는 부작용이 있을 수 있다.
이에 따라, 해결책은 전체 [MASK]토큰 중 80%정도를 [MASK]토큰으로 두고 10%정도를 랜덤한 word를 넣고 복원시켜주는 방향으로 학습하며 나머지 10%는 원래 단어를 그래로 둔 채 원래 있던 단어인지에 대한 유무 파악의 형식으로 학습을 진행하게 된다.
- 다음 문장으로 나오는 것이 적합한지 파악

출처: Naver BoostCamp AI Tech - edwith 강의
[MASK]토큰 자리에서 나오는 vector는 Fully connected layer를 통과하여 단어를 예측하고 [SEP]토큰은 문장을 분리하며 [CLS]토큰은 두 문장이 실제로 연속된 문장인지 Binary Classification수행
- [MASK]토큰의 자리에 알맞은 단어를 넣기
-
Bert의 다양한 모델 및 특징
-
모델 종류
1, BERT BASE : L=12, H = 768, A = 12
2, BERT LARGE : L=24, H=1024, A=16
(L : layer수, H : hidden state demension수, A : 각 layer별로 정의되는 Attention head의 수) -
input표현
1, WordPiece embeddings(30,000 WordPiece)<pre traning => '-'으로 연결되어 있지 않아도 합성어로 판별>
2, Learned positional embedding : positional embedding도 학습에 의해 결정될 수 있도록
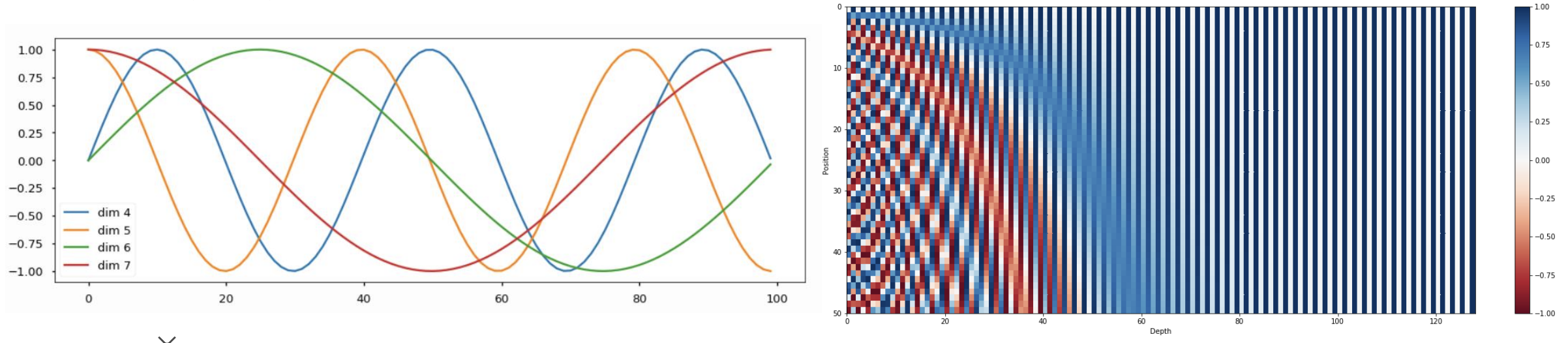
출처: Naver BoostCamp AI Tech - edwith 강의
3, Classification embedding을 위한 [CLS]토큰
4, Packed sentence embedding[SEP] (문장 단위로 판별하기 위한 토큰)
5, Segment Embedding
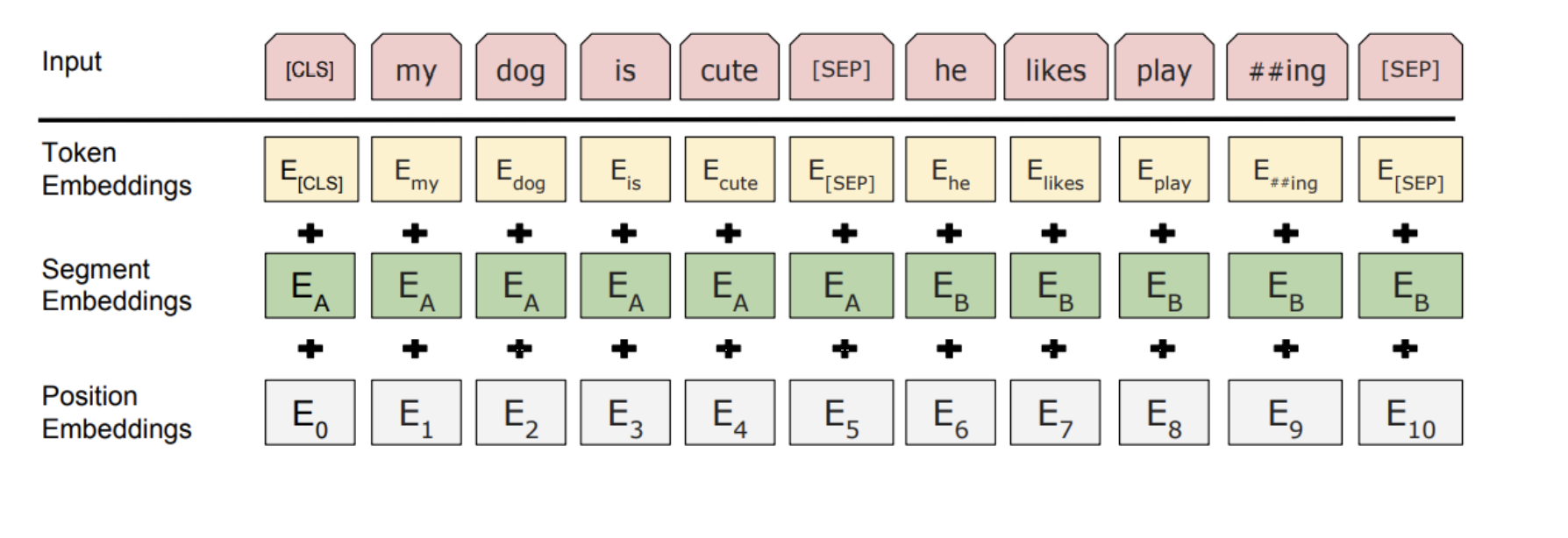
출처: Naver BoostCamp AI Tech - edwith 강의
문장의 위치를 반별하기 위한 position embeddings를 더해주는 한변 문장단위로 구별하기 위해 segment embeddings를 더해줌
-
-
fine-tuning
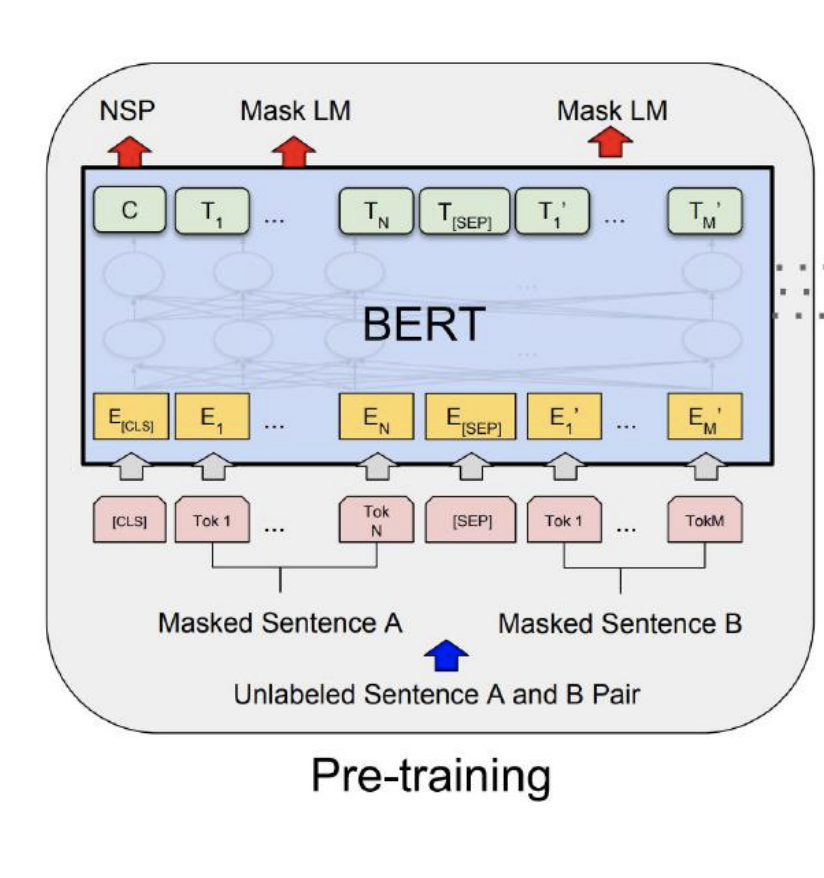
출처: Naver BoostCamp AI Tech - edwith 강의
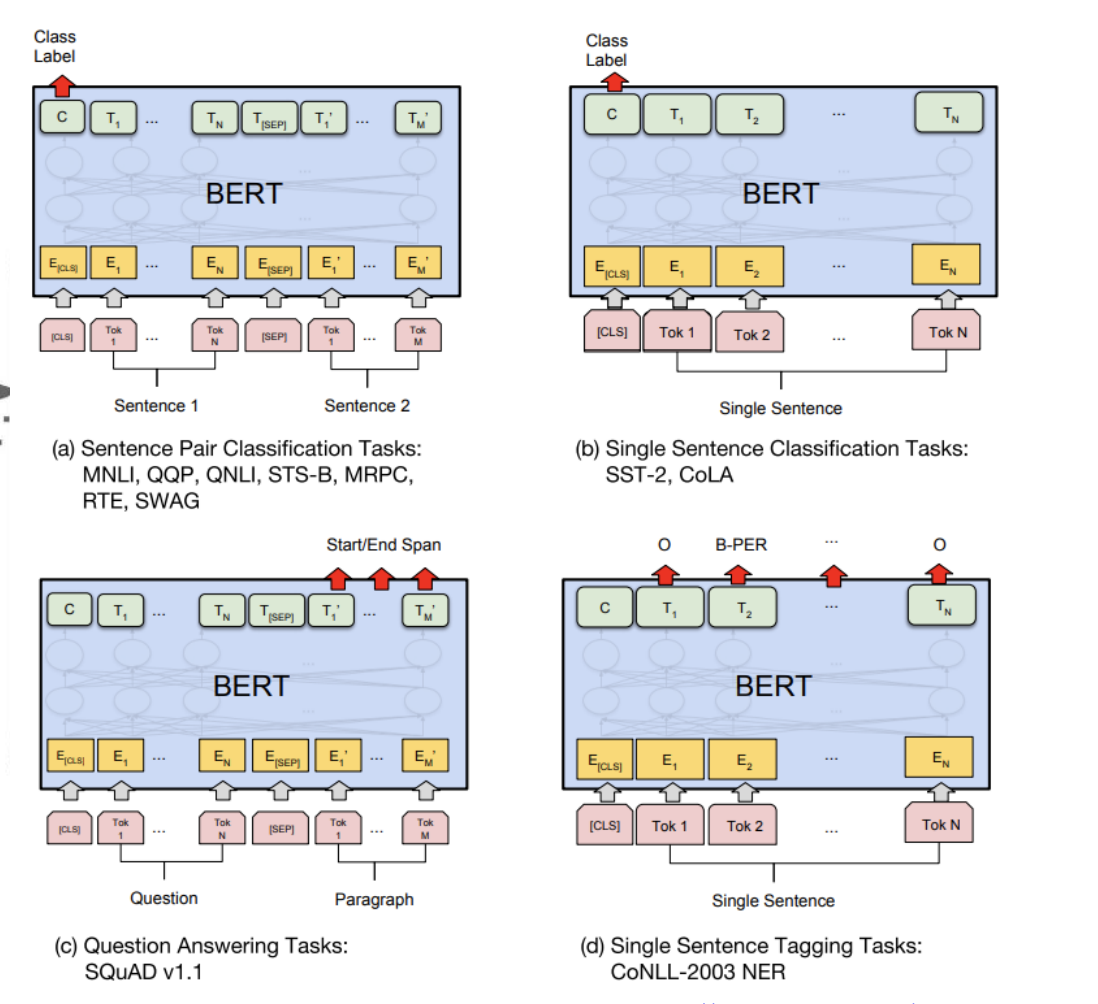
출처: Naver BoostCamp AI Tech - edwith 강의
1, Sentence Pair Classification Task(입력 문장이 여러개고 분류 task를 수행 할 시)
2, Single Sentence Classification Task
3, Question Aswering Tasks
4, Single Sentence Tagging Tasks(주어진 문장에서 각각의 word에 대한 정보를 산출하고 싶을 때 -품사 등...)
-
fine-tining을 한 BERT의 성능(GLUE Menchmark Result)
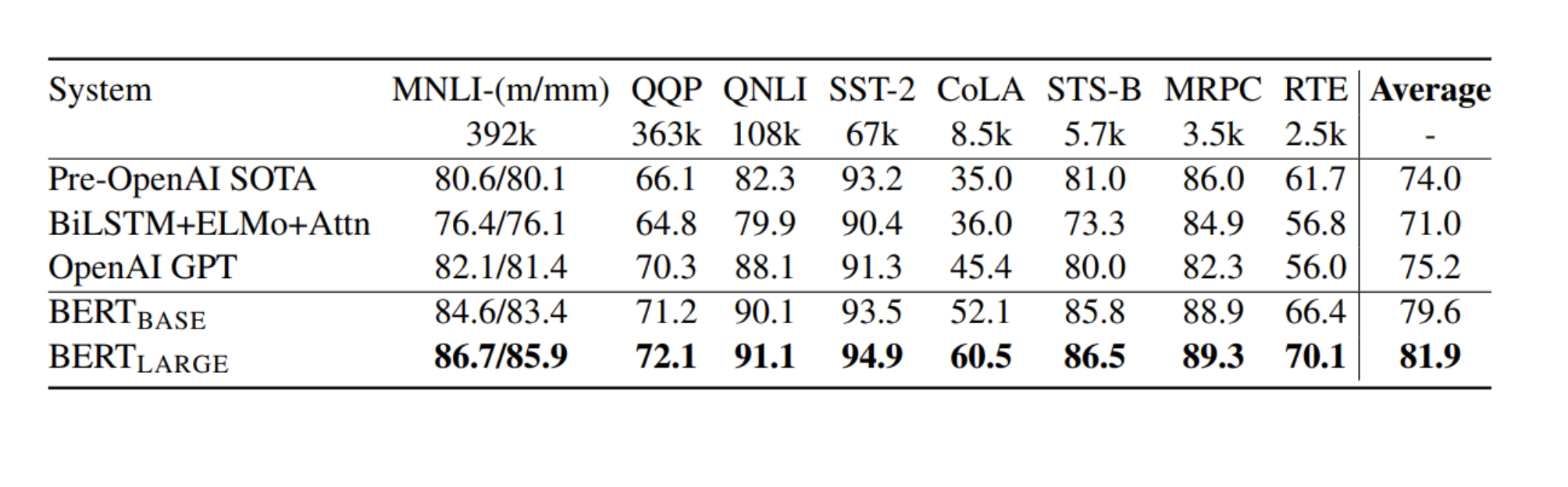
출처: Naver BoostCamp AI Tech - edwith 강의
(결과물을 도출한 층을 제거 후 해결하고자 하는 task를 수행하기 위한 층을 추가하여 수행한 결과)
BERT와 GPT1
- traning 데이터의 크기
GPT-1 : BookCorpus(800M words)
BERT : BookCorpus & Wikipedia(2,500M words) - 훈련에 사용되는 special token
BERT : [SEP], [CLS]토큰들을 사용하고 pre-training시 segment embedding사용 - Batch size
GPT-1 : 32,000words
BERT : 128,000words
(Batch size는 큰 사이즈 일수록 학습 성과가 안정화 되어지는데 이는 역전파 수행 시 Batch size의 크기가 클 수록 전체 데이터를 학습하는 것과 비슷한 효과를 가지기 때문이다.) - Task-specific fine-tuning
GPT-1 : fine-tuning실험 시 모든 task에 대하여 동일한 learning rate를 사용한 반면 BERT는 각 task마다 fine-tuning실험 시 각기 다른 learning rate를 사용
이 외의 Self- Supervised Pre-Traning Models
- GPT-2
- GPT-3
- ALBERT
- ELECTRA
- Light-weight Models
- DistillBERT, TinyBERT
- Fusing Knowledge Graph into Language Model
- ERNIE, KagNET
Reference
Naver BoostCamp AI Tech - edwith
https://medium.com/@eyfydsyd97/%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-improving-language-understanding-by-generative-pre-training-gpt1-c65bed865990
https://simonezz.tistory.com/73
https://greeksharifa.github.io/nlp(natural%20language%20processing)%20/%20rnns/2019/08/21/OpenAI-GPT-1-Improving-Language-Understanding-by-Generative-Pre-Training/
https://blog.naver.com/PostView.nhn?blogId=flowerdances&logNo=221189533377&categoryNo=32&parentCategoryNo=0&viewDate=¤tPage=1&postListTopCurrentPage=1&from=postView
